Hadoop伪分布配置与基于Eclipse开发环境搭建
1、开发配置环境:
开发环境:Win7(64bit)+Eclipse(kepler service release 2)
配置环境:Ubuntu Server 14.04.1 LTS(64-bit only)
辅助工具:WinSCP + Putty
Hadoop版本:2.5.0
Hadoop的Eclipse开发插件(2.x版本适用):http://pan.baidu.com/s/1eQy49sm
服务器端JDK版本:OpenJDK7.0
以上所有工具请自行下载安装。
2、Hadoop服务端配置(Master节点)
最近一直在摸索Hadoop2的配置,因为Hadoop2对原有的一些框架API做了调整,但也还是兼容旧版本的(包括配置)。像我这种就喜欢用新的东西的人,当然要尝一下鲜了,现在网上比较少新版本的配置教程,那么下面我就来分享一下我自己的实战经验,如有不正确的地欢迎指正:)。
假设我们已经成功地安装了Ubuntu Server、OpenJDK、SSH,如果还没有安装的话请先安装,自己网上找一下教程,这里我就说一下SSH的无口令登陆设置。首先通过
$ ssh localhost
测试一下自己有没有设置好无口令登陆,如果没有设置好,系统将要求你输入密码,通过下面的设置可以实现无口令登陆,具体原理请百度谷歌:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
其次是Hadoop安装(假设已经安装好OpenJDK以及配置好了环境变量),到Hadoop官网下载一个Hadoop2.5.0版本的下来,好像大概有100多M的tar.gz包,下载 下来后自行解压,我的是放在/usr/mywind下面,Hadoop主目录完整路径是/usr/mywind/hadoop,这个路径根据你个人喜好放吧。
解压完后,打开hadoop主目录下的etc/hadoop/hadoop-env.sh文件,在最后面加入下面内容:
# set to the root of your Java installation export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 # Assuming your installation directory is /usr/mywind/hadoop export HADOOP_PREFIX=/usr/mywind/hadoop
为了方便起见,我建设把Hadoop的bin目录及sbin目录也加入到环境变量中,我是直接修改了Ubuntu的/etc/environment文件,内容如下:
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/lib/jvm/java-7-openjdk-amd64/bin:/usr/mywind/hadoop/bin:/usr/mywind/hadoop/sbin" JAVA_HOME="/usr/lib/jvm/java-7-openjdk-amd64" CLASSPATH=".:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar"
也可以通过修改profile来完成这个设置,看个人习惯咯。假如上面的设置你都完成了,可以在命令行里面测试一下Hadoop命令,如下图:
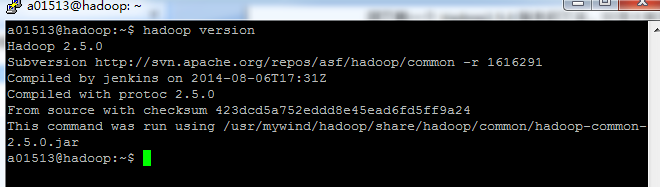
假如你能看到上面的结果,恭喜你,Hadoop安装完成了。接下来我们可以进行伪分布配置(Hadoop可以在伪分布模式下运行单结点)。
接下来我们要配置的文件有四个,分别是/usr/mywind/hadoop/etc/hadoop目录下的yarn-site.xml、mapred-site.xml、hdfs-site.xml、core-site.xml(注意:这个版本下默认没有yarn-site.xml文件,但有个yarn-site.xml.properties文件,把后缀修改成前者即可),关于yarn新特性可以参考官网或者这个文章http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/。
首先是core-site.xml配置HDFS地址及临时目录(默认的临时目录在重启后会删除):
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.8.184:9000</value> <description>same as fs.default.name</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/mywind/tmp</value> <description>A base for other temporary directories.</description> </property> </configuration>
然后是hdfs-site.xml配置集群数量及其他一些可选配置比如NameNode目录、DataNode目录等等:
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/usr/mywind/name</value> <description>same as dfs.name.dir</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/mywind/data</value> <description>same as dfs.data.dir</description> </property> <property> <name>dfs.replication</name> <value>1</value> <description>same as old frame,recommend set the value as the cluster DataNode host numbers!</description> </property> </configuration>
接着是mapred-site.xml配置启用yarn框架:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
最后是yarn-site.xml配置NodeManager:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
注意,网上的旧版本教程可能会把value写成mapreduce.shuffle,这个要特别注意一下的,至此我们所有的文件配置都已经完成了,下面进行HDFS文件系统进行格式化:
$ hdfs namenode -format
然后启用NameNode及DataNode进程:
$ start-yarn.sh
然后创建hdfs文件目录
$ hdfs dfs -mkdir /user $ hdfs dfs -mkdir /user/a01513
注意,这个a01513是我在Ubuntu上的用户名,最好保持与系统用户名一致,据说不一致会有许多权限等问题,我之前试过改成其他名字,报错,实在麻烦就改成跟系统用户名一致吧。
然后把要测试的输入文件放在文件系统中:
$ hdfs dfs -put /usr/mywind/psa input

文件内容是Hadoop经典的天气例子的数据:
12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+001212345678903456 12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+011212345678903456 12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+021212345678903456 12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+003212345678903456 12345679867623119010123456798676231190201234567986762311901012345679867623119010123456+004212345678903456 12345679867623119010123456798676231190201234567986762311901012345679867623119010123456+010212345678903456 12345679867623119010123456798676231190201234567986762311901012345679867623119010123456+011212345678903456 12345679867623119010123456798676231190501234567986762311901012345679867623119010123456+041212345678903456 12345679867623119010123456798676231190501234567986762311901012345679867623119010123456+008212345678903456
把文件拷贝到HDFS目录之后,我们可以通过浏览器查看相关的文件及一些状态:
http://192.168.8.184:50070/
这里的IP地址根据你实际的Hadoop服务器地址啦。
好吧,我们所有的Hadoop后台服务搭建跟数据准备都已经完成了,那么我们的M/R程序也要开始动手写了,不过在写当然先配置开发环境了。
3、基于Eclipse的Hadoop2.x开发环境配置
关于JDK及ECLIPSE的安装我就不再介绍了,相信能玩Hadoop的人对这种配置都已经再熟悉不过了,如果实在不懂建议到谷歌百度去搜索一下教程。假设你已经把Hadoop的Eclipse插件下载下来了,然后解压把jar文件放到Eclipse的plugins文件夹里面:

重启Eclipse即可。
然后我们再安装Hadoop到Win7下,在这不再详细说明,跟安装JDK大同小异,在这个例子中我安装到了E:\hadoop。
启动Eclipse,点击菜单栏的【Windows/窗口】→【Preferences/首选项】→【Hadoop Map/Reduce】,把Hadoop Installation Directory设置成开发机上的Hadoop主目录:
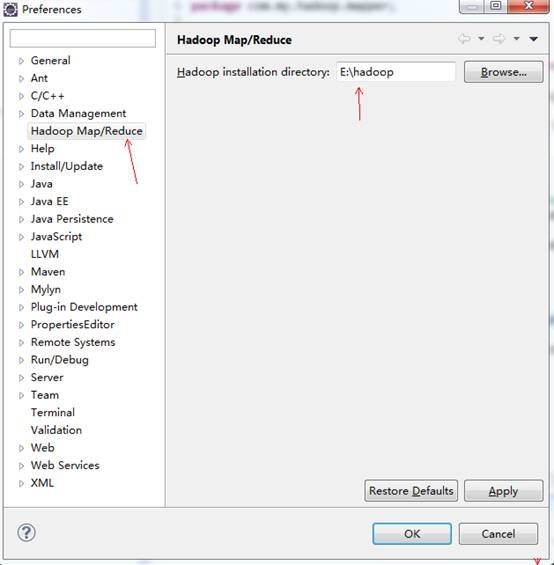
点击OK。
开发环境配置完成,下面我们可以新建一个测试Hadoop项目,右键【NEW/新建】→【Others、其他】,选择Map/Reduce Project

输入项目名称点击【Finish/完成】:

创建完成后可以看到如下目录:

然后在SRC下建立下面包及类:
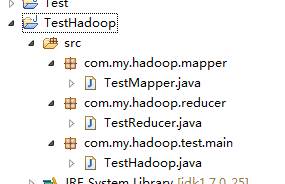
以下是代码内容:
TestMapper.java
package com.my.hadoop.mapper;
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class TestMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
private static final Log LOG = LogFactory.getLog(TestMapper.class);
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output,Reporter reporter)
throws IOException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
LOG.info("loki:"+airTemperature);
String quality = line.substring(92, 93);
LOG.info("loki2:"+quality);
if (airTemperature != MISSING && quality.matches("[012459]")) {
LOG.info("loki3:"+quality);
output.collect(new Text(year), new IntWritable(airTemperature));
}
}
}
TestReducer.java
package com.my.hadoop.reducer;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.Reducer;
public class TestReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,Reporter reporter)
throws IOException{
int maxValue = Integer.MIN_VALUE;
while (values.hasNext()) {
maxValue = Math.max(maxValue, values.next().get());
}
output.collect(key, new IntWritable(maxValue));
}
}
TestHadoop.java
package com.my.hadoop.test.main;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import com.my.hadoop.mapper.TestMapper;
import com.my.hadoop.reducer.TestReducer;
public class TestHadoop {
public static void main(String[] args) throws Exception{
if (args.length != 2) {
System.err
.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
JobConf job = new JobConf(TestHadoop.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(TestMapper.class);
job.setReducerClass(TestReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
JobClient.runJob(job);
}
}
为了方便对于Hadoop的HDFS文件系统操作,我们可以在Eclipse下面的Map/Reduce Locations窗口与Hadoop建立连接,直接右键新建Hadoop连接即可:

连接配置如下:

然后点击完成即可,新建完成后,我们可以在左侧目录中看到HDFS的文件系统目录:

这里不仅可以显示目录结构,还可以对文件及目录进行删除、新增等操作,非常方便。
当上面的工作都做好之后,就可以把这个项目导出来了(导成jar文件放到Hadoop服务器上运行):

点击完成,然后把这个testt.jar文件上传到Hadoop服务器(192.168.8.184)上,目录(其实可以放到其他目录,你自己喜欢)是:
/usr/mywind/hadoop/share/hadoop/mapreduce
如下图:

4、运行Hadoop程序及查看运行日志
当上面的工作准备好了之后,我们运行自己写的Hadoop程序很简单:
$ hadoop jar /usr/mywind/hadoop/share/hadoop/mapreduce/testt.jar com.my.hadoop.test.main.TestHadoop input output
注意这是output文件夹名称不能重复哦,假如你执行了一次,在HDFS文件系统下面会自动生成一个output文件夹,第二次运行时,要么把output文件夹先删除($ hdfs dfs -rmr /user/a01513/output),要么把命令中的output改成其他名称如output1、output2等等。
如果看到以下输出结果,证明你的运行成功了:
a01513@hadoop :~$ hadoop jar /usr/mywind/hadoop/share/hadoop/mapreduce/testt.jar com.my.hadoop.test.main.TestHadoop input output 14/09/02 11:14:03 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0 :8032 14/09/02 11:14:04 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0 :8032 14/09/02 11:14:04 WARN mapreduce.JobSubmitter: Hadoop command-line option parsin g not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 14/09/02 11:14:04 INFO mapred.FileInputFormat: Total input paths to process : 1 14/09/02 11:14:04 INFO mapreduce.JobSubmitter: number of splits:2 14/09/02 11:14:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_14 09386620927_0015 14/09/02 11:14:05 INFO impl.YarnClientImpl: Submitted application application_14 09386620927_0015 14/09/02 11:14:05 INFO mapreduce.Job: The url to track the job: http://hadoop:80 88/proxy/application_1409386620927_0015/ 14/09/02 11:14:05 INFO mapreduce.Job: Running job: job_1409386620927_0015 14/09/02 11:14:12 INFO mapreduce.Job: Job job_1409386620927_0015 running in uber mode : false 14/09/02 11:14:12 INFO mapreduce.Job: map 0% reduce 0% 14/09/02 11:14:21 INFO mapreduce.Job: map 100% reduce 0% 14/09/02 11:14:28 INFO mapreduce.Job: map 100% reduce 100% 14/09/02 11:14:28 INFO mapreduce.Job: Job job_1409386620927_0015 completed successfully 14/09/02 11:14:29 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=105 FILE: Number of bytes written=289816 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=1638 HDFS: Number of bytes written=10 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=14817 Total time spent by all reduces in occupied slots (ms)=4500 Total time spent by all map tasks (ms)=14817 Total time spent by all reduce tasks (ms)=4500 Total vcore-seconds taken by all map tasks=14817 Total vcore-seconds taken by all reduce tasks=4500 Total megabyte-seconds taken by all map tasks=15172608 Total megabyte-seconds taken by all reduce tasks=4608000 Map-Reduce Framework Map input records=9 Map output records=9 Map output bytes=81 Map output materialized bytes=111 Input split bytes=208 Combine input records=0 Combine output records=0 Reduce input groups=1 Reduce shuffle bytes=111 Reduce input records=9 Reduce output records=1 Spilled Records=18 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=115 CPU time spent (ms)=1990 Physical memory (bytes) snapshot=655314944 Virtual memory (bytes) snapshot=2480295936 Total committed heap usage (bytes)=466616320 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1430 File Output Format Counters Bytes Written=10 a01513@hadoop :~$
我们可以到Eclipse查看输出的结果:
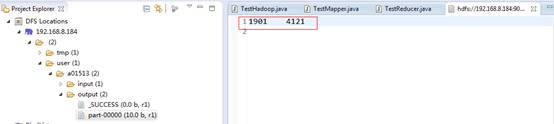
或者用命令行查看:
$ hdfs dfs -cat output/part-00000
![]()
假如你们发现运行后结果是为空的,可能到日志目录查找相应的log.info输出信息,log目录在:/usr/mywind/hadoop/logs/userlogs 下面。
好了,不太喜欢打字,以上就是整个过程了,欢迎大家来学习指正。