阿里巴巴开源Cobar使用记录
Cobar的分布式主要是通过将表放入不同的库来实现:
1. Cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分
2. Cobar也支持将不同的表放入不同的库
3. 多数情况下,用户会将以上两种方式混合使用
这里需要强调的是,Cobar不支持将一张表,例如test表拆分成test_1, test_2, test_3.....放在同一个库中,必须将拆分后的表分别放入不同的库来实现分布式。
HA:
在用户配置了MySQL心跳的情况下,Cobar可以自动向后端连接的MySQL发送心跳,判断MySQL运行状况,一旦运行出现异常,Cobar可以自动切换到备机工作。但需要强调的是:
1. Cobar的主备切换有两种触发方式,一种是用户手动触发,一种是Cobar的心跳语句检测到异常后自动触发。那么,当心跳检测到主机异常,切换到备机,如果主机恢复了,需要用户手动切回主机工作,Cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常。
2. Cobar只检查MySQL主备异常,不关心主备之间的数据同步,因此用户需要在使用Cobar之前在MySQL主备上配置双向同步,详情可以参阅MySQL参考手册。
其次,我们也需要注意Cobar的功能约束:
1) 不支持跨库情况下的join、分页、排序、子查询操作。
2) SET语句执行会被忽略,事务和字符集设置除外。
3) 分库情况下,insert语句必须包含拆分字段列名。
4) 分库情况下,update语句不能更新拆分字段的值。
5) 不支持SAVEPOINT操作。
6) 暂时只支持MySQL数据节点。
7) 使用JDBC时,不支持rewriteBatchedStatements=true参数设置(默认为false)。
8) 使用JDBC时,不支持useServerPrepStmts=true参数设置(默认为false)。
9) 使用JDBC时,BLOB, BINARY, VARBINARY字段不能使用setBlob()或setBinaryStream()方法设置参数。
然后,我们来分析一下Cobar逻辑层次图:
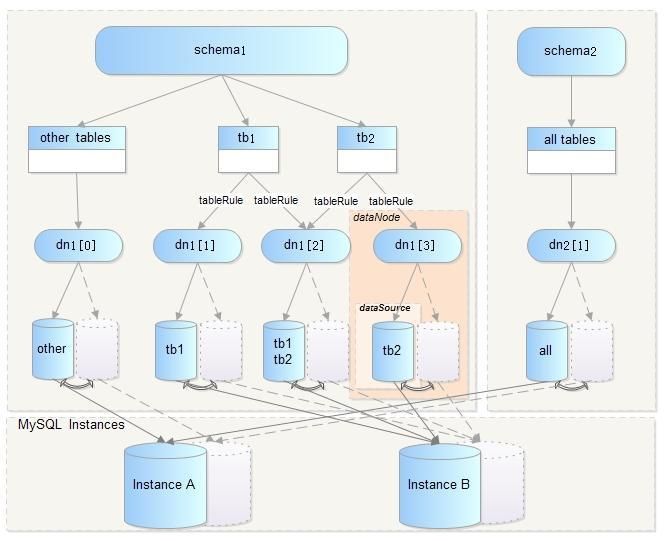
* dataSource:数据源,表示一个具体的数据库连接,与物理存在的数据库schema一一对应。
* dataNode:数据节点,由主、备数据源,数据源的HA以及连接池共同组成,可以将一个dataNode理解为一个分库。
* table:表,包括拆分表(如tb1,tb2)和非拆分表。
* tableRule:路由规则,用于判断SQL语句被路由到具体哪些datanode执行。
* schema:cobar可以定义包含拆分表的schema(如schema1),也可以定义无拆分表的schema(如schema2)。
Cobar支持的数据库结构(schema)的层次关系具有较强的灵活性,用户可以将表自由放置不同的datanode,也可将不同的datasource放置在同一MySQL实例上。在实际应用中,我们需要通过配置文件(schema.xml)来定义我们需要的数据库服务器和表的分布策略,这点我们将在后面的安装和配置部分中介绍到。
接着,我们来介绍Cobar的安装和配置步骤:
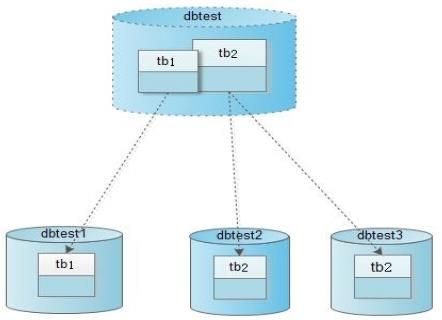
下面我们将使用一个最简单的分库分表的例子来说明Cobar的基本用法,数据库schema如下图(该实例也可参考: Cobar产品首页 )。
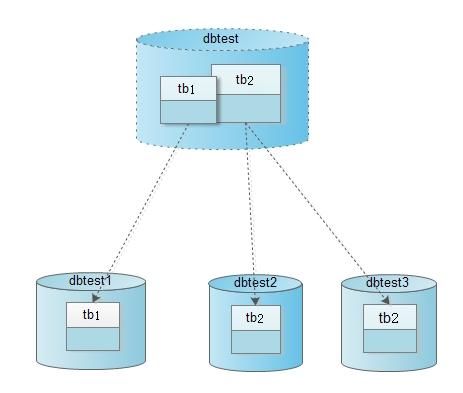
1) 系统对外提供的数据库名是dbtest,并且其中有两张表tb1和tb2。
2) tb1表的数据被映射到物理数据库dbtest1的tb1上。
3) tb2表的一部分数据被映射到物理数据库dbtest2的tb2上,另外一部分数据被映射到物理数据库dbtest3的tb2上。
1、环境准备
操作系统:Linux或者Windows (推荐在Linux环境下运行Cobar)
MySQL: http://www.mysql.com/downloads/ (推荐使用5.1以上版本)
JDK: http://www.oracle.com/technetwork/java/javase/downloads/ (推荐使用1.6以上版本)
Cobar: http://code.alibabatech.com/wiki/display/cobar/release/ (下载tar.gz或者zip文件)
2、数据准备
假设本文MySQL所在服务器IP为192.168.0.1,端口为3306,用户名为test,密码为空,我们需要创建schema:dbtest1、dbtest2、dbtest3,table:tb1、tb2,SQL如下:
- #创建dbtest1
- drop database if exists dbtest1;
- create database dbtest1;
- use dbtest1;
- #在dbtest1上创建tb1
- create table tb1(
- id int not null,
- gmt datetime);
- #创建dbtest2
- drop database if exists dbtest2;
- create database dbtest2;
- use dbtest2;
- #在dbtest2上创建tb2
- create table tb2(
- id int not null,
- val varchar(256));
- #创建dbtest3
- drop database if exists dbtest3;
- create database dbtest3;
- use dbtest3;
- #在dbtest3上创建tb2
- create table tb2(
- id int not null,
- val varchar(256));
3、配置Cobar
Cobar解压之后有四个目录:
bin/:可执行文件目录,包含启动(start)、关闭(shutdown)和重启(restart)脚本
lib/:逻辑类库目录,包含了Cobar所需的jar包
conf/:配置文件目录,下面会详细介绍
logs/:运行日志目录,最主要的log有两个:程序日志(stdout.log)和控制台输出(console.log)
配置文件的用法如下:
log4j.xml:日志配置,一般来说保持默认即可
schema.xml:定义了schema逻辑层次图中的所有元素,并利用这些元素以及rule.xml中定义的规则组建分布式数据库系统
rule.xml:定义了分库分表的规则
server.xml:系统配置文件
我们在schema.xml中配置数据库结构(schema)、数据节点(dataNode)、以及数据源(dataSource)。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE cobar:schema SYSTEM "schema.dtd">
- <cobar:schema xmlns:cobar="http://cobar.alibaba.com/">
- <!-- schema定义 -->
- <schema name="dbtest" dataNode="dnTest1">
- <table name="tb2" dataNode="dnTest2,dnTest3" rule="rule1" />
- </schema>
- <!-- 数据节点定义,数据节点由数据源和其他一些参数组织而成。-->
- <dataNode name="dnTest1">
- <property name="dataSource">
- <dataSourceRef>dsTest[0]</dataSourceRef>
- </property>
- </dataNode>
- <dataNode name="dnTest2">
- <property name="dataSource">
- <dataSourceRef>dsTest[1]</dataSourceRef>
- </property>
- </dataNode>
- <dataNode name="dnTest3">
- <property name="dataSource">
- <dataSourceRef>dsTest[2]</dataSourceRef>
- </property>
- </dataNode>
- <!-- 数据源定义,数据源是一个具体的后端数据连接的表示。-->
- <dataSource name="dsTest" type="mysql">
- <property name="location">
- <location>192.168.0.1:3306/dbtest1</location> <!--注意:替换为您的MySQL IP和Port-->
- <location>192.168.0.1:3306/dbtest2</location> <!--注意:替换为您的MySQL IP和Port-->
- <location>192.168.0.1:3306/dbtest3</location> <!--注意:替换为您的MySQL IP和Port-->
- </property>
- <property name="user">test</property> <!--注意:替换为您的MySQL用户名-->
- <property name="password">test</property> <!--注意:替换为您的MySQL密码-->
- <property name="sqlMode">STRICT_TRANS_TABLES</property>
- </dataSource>
- </cobar:schema>
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE cobar:rule SYSTEM "rule.dtd">
- <cobar:rule xmlns:cobar="http://cobar.alibaba.com/">
- <!-- 路由规则定义,定义什么表,什么字段,采用什么路由算法。-->
- <tableRule name="rule1">
- <rule>
- <columns>id</columns>
- <algorithm><![CDATA[ func1(${id})]]></algorithm>
- </rule>
- </tableRule>
- <!-- 路由函数定义,应用在路由规则的算法定义中,路由函数可以自定义扩展。-->
- <function name="func1" class="com.alibaba.cobar.route.function.PartitionByLong">
- <property name="partitionCount">2</property>
- <property name="partitionLength">512</property>
- </function>
- </cobar:rule>
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE cobar:server SYSTEM "server.dtd">
- <cobar:server xmlns:cobar="http://cobar.alibaba.com/">
- <!--定义Cobar用户名,密码-->
- <user name="root">
- <property name="password">passwd</property>
- <property name="schemas">dbtest</property>
- </user>
- </cobar:server>
4、运行Cobar
启动Cobar服务很简单,运用bin目录下的start.sh即可(停止使用shutdown.sh)。启动成功之后,可以在logs目录下的stdout.log中看到如下日志:
- 10:54:19,264 INFO ===============================================
- 10:54:19,265 INFO Cobar is ready to startup ...
- 10:54:19,265 INFO Startup processors ...
- 10:54:19,443 INFO Startup connector ...
- 10:54:19,446 INFO Initialize dataNodes ...
- 10:54:19,470 INFO dnTest1:0 init success
- 10:54:19,472 INFO dnTest3:0 init success
- 10:54:19,473 INFO dnTest2:0 init success
- 10:54:19,481 INFO CobarManager is started and listening on 9066
- 10:54:19,483 INFO CobarServer is started and listening on 8066
- 10:54:19,484 INFO ===============================================
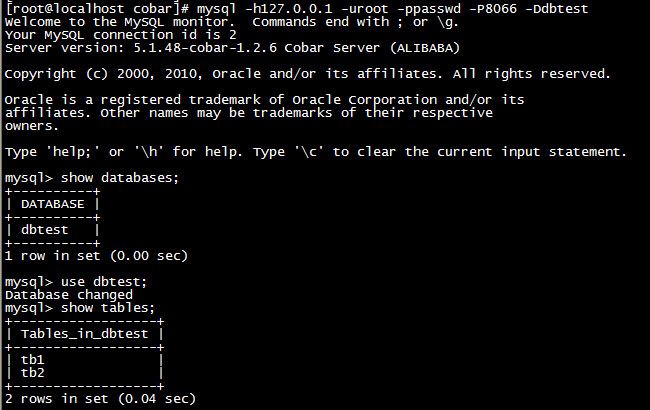
接着,我们就可以使用“mysql -h127.0.0.1 -uroot -ppasswd -P8066 -Ddbtest”命令来登录Cobar服务了,再接下来的操作就和在其他MySQL Client中一样了。比如,我们可以使用“show databases”命令查看数据库,使用“show tables”命令查看数据表,如下图:
接着,我们按照下图中的SQL指定向数据表插入测试记录。
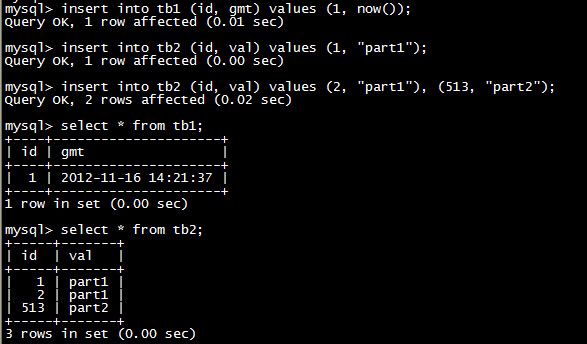
可以看到,这里的tb2中包含了id为1、2、513的3条记录。而实际上,这3条记录存储在不同的物理数据库上的,大家可以到物理库上验证一下。
至于Cobar的连接和使用方法和MySQL一样,Java程序中可以使用JDBC(建议5.1以上的版本),PHP中可以使用PDO。当然,Cobar还提供HA、集群等高级的功能,更多信息请参考其《 产品文档 》 。此外,产品文档中还为我们提供了详细的PPT文档《Cobar原理及应用.ppt》来介绍Cobar在实际生产环境中的使用方法,真可谓之用心良苦啊!
此外,特别解释一下大家可能比较关心的心跳检测问题,Cobar的心跳检测主要用在以下两个地方。
1、在配置数据节点的时候,我们需要使用心跳检测来探测数据节点的运行状况。Cobar中使用执行SQL的方式来进行探测,简单且实用。例如,我们可以把前面实例中的schema.xml中的dataNode配置成下面的样子。
- ... ...
- <!-- 数据节点定义,数据节点由数据源和其他一些参数组织而成。-->
- <dataNode name="dnTest1">
- <property name="dataSource">
- <dataSourceRef>dsTest[0]</dataSourceRef>
- </property>
- <!--Cobar与后端数据源连接池大小设置-->
- <property name="poolSize">256</property>
- <!--Cobar通过心跳来实现后端数据源HA,一旦主数据源心跳失败,便切换到备数据源上工作-->
- <!--Cobar心跳是通过向后端数据源执行一条SQL语句,根据该语句的返回结果判断数据源的运行情况-->
- <property name="heartbeat">select user()<property>
- </dataNode>
- ... ...
- ... ...
- <!--组建一个Cobar集群,只需在cluster配置中把所有Cobar节点(注意:包括当前Cobar自身)都配置上便可-->
- <cluster>
- <!--node名称,一个node表示一个Cobar节点,一旦配置了node,当前Cobar便会向此节点定期发起心跳,探测节点的运行情况-->
- <node name="cobar1">
- <!--Cobar节点IP, 表示当前Cobar将会向192.168.0.1上部署的Cobar发送心跳-->
- <property name="host">192.168.0.1</property>
- <!--节点的权重,用于客户端的负载均衡,用户可以通过命令查询某个节点的运行情况以及权重-->
- <property name="weight">1</property>
- </node>
- <!--当前Cobar将会向192.168.0.2上部署的Cobar发送心跳-->
- <node name="cobar2">
- <property name="host">192.168.0.2</property>
- <property name="weight">2</property>
- </node>
- <!--当前Cobar将会向192.168.0.3上部署的Cobar发送心跳-->
- <node name="cobar3">
- <property name="host">192.168.0.3</property>
- <property name="weight">3</property>
- </node>
- <!--用户还可以将Cobar节点分组,以便实现schema级别的细粒度负载均衡-->
- <group name="group12">
- <property name="nodeList">cobar1,cobar2</property>
- </group>
- <group name="group23">
- <property name="nodeList">cobar2,cobar3</property>
- </group>
- </cluster>
- ... ...
最后,简单看一下Cobar的实现原理。
首先是系统模块架构。

从上图中可以看到,Cobar的前、后端模块都实现了MySQL协议;当接受到SQL请求时,会依次进行解释(SQL Parser)和路由(SQL Router)工作,然后使用SQL Executor去后端模块获取数据集(后端模块还负责心跳检测功能);如果数据集来自多个数据源,Cobar则需要把数据集进行组合(Result Merge),最后返回响应。整个过程应该比较容易理解,
下面是Cobar的网络通讯模块架构。

从上图中可以看出,Cobar采用了主流的Reactor设计模式来处理请求,并使用NIO进行底层的数据交换,这大大提升系统的负载能力。其中,NIOAcceptor用于处理前端请求,NIOConnector则用于管理后端的连接,NIOProcessor用于管理多线程事件处理,NIOReactor则用于完成底层的事件驱动机制,就是看起来和Mina和Netty的网络模型比较相似。如果有兴趣,大家还可以到Cobar站点的下载页面(http://code.alibabatech.com/wiki/display/cobar/release)获取该项目的源码
、基本功能测试
本环节测试了基本的MySQL功能,查询,插入等。
数据表分配如下:
在schema.xml中定义了该schema的默认datanode,定义了tb2分布在dbtest2、dbtest3中。默认datanode的作用是存放未指定的表,比如创建tb1,就会默认放在dbtest1中。
在rule.xml中为tb2定义了路由用的partitionCount和partitionLength,会按照特定字段进行分库操作。
1.insert
insert命令能够按照约定的路由规则插入特定的分库中。
为了简单测试cobar的插入效率,对tb2插入了10W条数据,结果显示要比单机MySQL插入10W条数据稍慢,随后测试16节点cobar插入10W条数据,速度已经和单机插入接近,如果多线程并发执行的话,cobar会有比较大的优势。
2.select
对上一步插入的数据进行select操作,每个分库结果会merge在一起但是merge的顺序是不确定的。
同样对cobar中的10W条数据进行查询,结果显示依旧是比单机慢:
Cobar:

单机MySQL:

三)、特定功能测试
正常业务中的SQL语句不会仅仅只是insert、select,会用到聚合函数、内外连接、子查询等。官方文档里已经明确说明不支持跨库条件下的这些操作,具体测试如下。
1、order by
对数据id排序查询,单库中order by可以正常显示,对cobar进行相同的操作,可以返回结果,每个分库的结果集按照各自的order排序,最后merge的时候并不是全部排序,而是随机联接在一起。
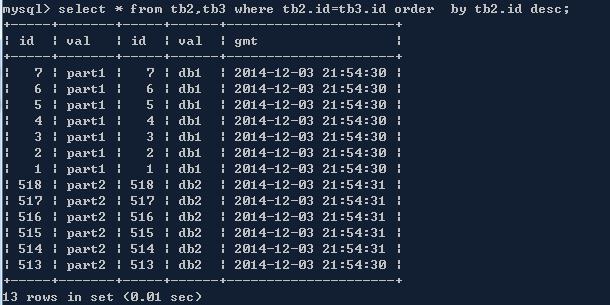
2、sum count
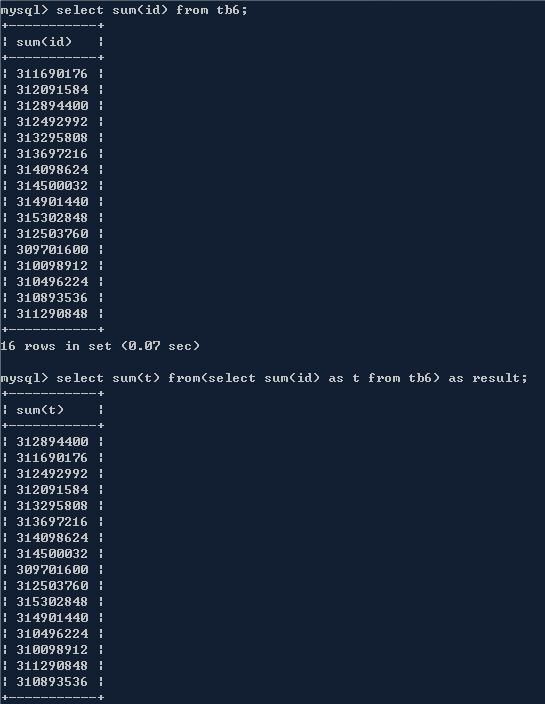
sum常用来合计某些字段,count用来计数,都是比较常用的sql关键字。Cobar能够返回sum/count的结果,但依旧是每个分库各自统计。
用子查询也不能合并分库的sum,这两个sql查出来的结果是相同的。
3、join
join也是极其常用的sql关键字,但是在cobar中如果切分规则不同的两张表进行join,则构成了跨库。Cobar会报错,提示不存在共同分库中的相应表。而如果两张表采用相同的切分字段,相同的路由规则,那么两者是能够join的。
在测试环境中,tb1不是和tb4相同切分,如果和tb4 join,就会提示不存在dbtest3.tb1。
![]()
而如果和tb4切分相同的tb3和它join就可以实现。

4、exists
exists也可以用,但是也是要考虑在不在一个库中
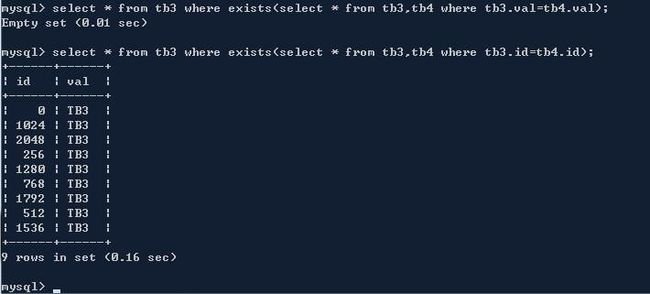
tb3和tb4是按照相同的分片规则分布在数据库中的
5、子查询
子查询在跨库情况下也是不能实现的,但是如果能够限制过程中使用的都封闭在同一个分库中,那么子查询是可以成立的。
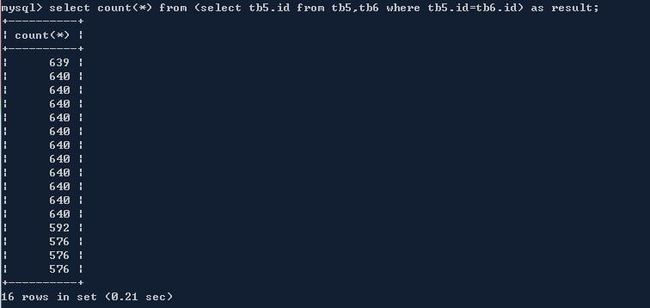
6、存储过程
在尝试插入10W条数据的时候,单机用到了存储过程,总共用时50余秒,同样语句用到cobar的时候,会显示语法错误,官方提示没有测试过存储过程,不推荐使用。

四、应用Cobar的问题及解决方案
现实中有的业务是比较复杂的,功能实现中使用到的SQL语句也可能是很复杂的,可能遇到的问题如下:
一)、参数表
实际业务中会有一些读操作很多而对写要求不多的参数表,会频繁地和其他表进行join,但是cobar不支持跨库join,那么可行的方案就是在每个分库中保留一份参数表,以便每个分库都可以合法操作。
但这会带来两个问题:
1.参数表之间需要union操作,但是每个分库中有一份相同表的结果就是union操作不能够除去重复项。
可以在分表的schema外有一个单库的schema,所有对参数表的增删改操作都限制在该库中,其所产生的变化都同步到每个分库中。
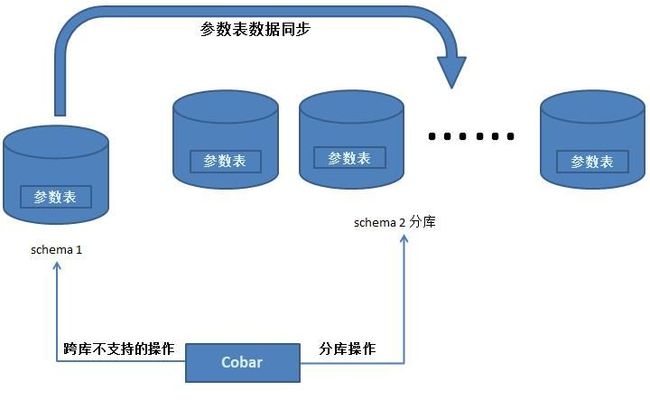
2.不同分库的参数表需要同步,那么如何保持参数表的数据一致性也是必须要考虑的问题。
二)、跨库操作问题
1、分库分表问题
Cobar不支持跨库操作,但是很多操作已经证明只要是封闭在各自分库中就是可以实现的,比如子查询、join等。
那么关键的问题就是如何分库分表,需要按照业务的耦合关系将数据库拆分重组,将不能跨库的操作尽量限制在一个库中。
而且cobar当前的路由算法不一定能够满足复杂业务下的特异性分表方案,所以在有需求的情况下,还需要自定义cobar的路由算法,自定义路由算法需要extends PartitionFunction implements RuleAlgorithm。
2、sum/count
但是即使分库分表方案设计完善,还是不能解决sum/count等功能的不完善,需要把每个分库的结果再累加才是需要的结果。
解决这个问题有几个方案:
1.在应用程序中处理,实现比较简单,但是增加了模块间的耦合度,破坏了数据层与应用层的透明。
2.修改cobar源码,识别sql语句,在收到返回信息的时候进行处理。实现难度比较大,但是保持了模块间的低耦合。
三)、压力问题
本次测试用的是虚拟机,单台虚拟机安装了8个MySQL实例,共实现了16个datanode,虚拟了10W条数据的简单操作,但和生产环境下的硬件条件以及压力情况是有很大区别的,只有在接近生产环境下真正进行了压力测试,才能得出cobar性能好坏的结论。
四)、事务问题
分布式数据库要实现事务是比较困难的,很多对数据一致性要求不是很严格的场景都放弃了强一致性,而力求达到最终一致性。Cobar对于单库的事务是完全支持的,但是对于分布式事务不保证强一致性,分布式事务采用两阶段执行,即分为执行阶段和提交阶段。
执行阶段:把前端连接上当前事务所使用到的后端连接绑定下来,并执行SQL语句。
- 提交阶段:将commit命令分发到这些绑定的后端连接中。
- 在整个事务过程中,执行阶段出错,可以回滚。提交阶段出错不可以回滚。可以说只要是commit之前,执行出现不一致,cobar会自动回滚。
cobar的分布式事务具体做到什么程度,在实际应用前还是需要测试的。
五)、主从备份问题
Cobar支持基于MySQL的心跳(heartbeat)来实现主备机切换,当检测到主机心跳异常,会自动或手动切换到备机,但是故障排除后切换回主机需要手动,除非备机心跳也异常。
主从复制的过程中一致性的保证也是需要注意的问题。
六)、数据迁移问题
当MySQL集群需要扩容时,就可能需要数据迁移,Cobar本身没有对数据迁移有很大的支持,也不支持mysqldump备份,需要备份时,必须在每个物理分库进行dump。数据迁移需要应用程序的DAO和Cobar还有后台迁移程序共同配合完成。
五、总结
通过对cobar的一系列探究,对其有了一定的认识,但是对于这个拥有800个源文件的顶尖数据库开源项目来说,还远远不够。单就应用来说,binlog同步的问题,事务一致性测试的问题,压力测试的问题,路由算法的问题,数据迁移的问题都是需要深入探讨研究的。
Cobar在阿里3年的稳定运行,能够说明它是个成熟的项目,但是同时要意识到,它是契合阿里特定的业务的项目,任何的迁移都是需要论证的;而且在阿里的数据库中间件中,cobar只是上下游中的一环,有可靠的VIP设备,有跨机房同步的数据同步中间件,有先进的分布式消息系统,才能使cobar扬长避短
此外,特别解释一下大家可能比较关心的心跳检测问题,Cobar的心跳检测主要用在以下两个地方。
1、在配置数据节点的时候,我们需要使用心跳检测来探测数据节点的运行状况。Cobar中使用执行SQL的方式来进行探测,简单且实用。例如,我们可以把前面实例中的schema.xml中的dataNode配置成下面的样子。
[html] view plaincopy
1. ... ...
2. <!-- 数据节点定义,数据节点由数据源和其他一些参数组织而成。-->
3. <dataNode name="dnTest1">
4. <property name="dataSource">
5. <dataSourceRef>dsTest[0]</dataSourceRef>
6. </property>
7. <!--Cobar与后端数据源连接池大小设置-->
8. <property name="poolSize">256</property>
9. <!--Cobar通过心跳来实现后端数据源HA,一旦主数据源心跳失败,便切换到备数据源上工作-->
10. <!--Cobar心跳是通过向后端数据源执行一条SQL语句,根据该语句的返回结果判断数据源的运行情况-->
11. <property name="heartbeat">select user()<property>
12. </dataNode>
13.... ...
2、当我们需要对Cobar作集群(cluster),进行负载均衡的时候,我们也需要用到心跳机制。不过此处的配置则是在server.xml中,代码如下:
[html] view plaincopy
1. ... ...
2. <!--组建一个Cobar集群,只需在cluster配置中把所有Cobar节点(注意:包括当前Cobar自身)都配置上便可-->
3. <cluster>
4. <!--node名称,一个node表示一个Cobar节点,一旦配置了node,当前Cobar便会向此节点定期发起心跳,探测节点的运行情况-->
5. <node name="cobar1">
6. <!--Cobar节点IP, 表示当前Cobar将会向192.168.0.1上部署的Cobar发送心跳-->
7. <property name="host">192.168.0.1</property>
8. <!--节点的权重,用于客户端的负载均衡,用户可以通过命令查询某个节点的运行情况以及权重-->
9. <property name="weight">1</property>
10. </node>
11. <!--当前Cobar将会向192.168.0.2上部署的Cobar发送心跳-->
12. <node name="cobar2">
13. <property name="host">192.168.0.2</property>
14. <property name="weight">2</property>
15. </node>
16. <!--当前Cobar将会向192.168.0.3上部署的Cobar发送心跳-->
17. <node name="cobar3">
18. <property name="host">192.168.0.3</property>
19. <property name="weight">3</property>
20. </node>
21. <!--用户还可以将Cobar节点分组,以便实现schema级别的细粒度负载均衡-->
22. <group name="group12">
23. <property name="nodeList">cobar1,cobar2</property>
24. </group>
25. <group name="group23">
26. <property name="nodeList">cobar2,cobar3</property>
27. </group>
28. </cluster>
29.... ...
最后,简单看一下Cobar的实现原理。
首先是系统模块架构。

从上图中可以看到,Cobar的前、后端模块都实现了MySQL协议;当接受到SQL请求时,会依次进行解释(SQL Parser)和路由(SQL Router)工作,然后使用SQL Executor去后端模块获取数据集(后端模块还负责心跳检测功能);如果数据集来自多个数据源,Cobar则需要把数据集进行组合(Result Merge),最后返回响应。整个过程应该比较容易理解,
下面是Cobar的网络通讯模块架构。

从上图中可以看出,Cobar采用了主流的Reactor设计模式来处理请求,并使用NIO进行底层的数据交换,这大大提升系统的负载能力。其中,NIOAcceptor用于处理前端请求,NIOConnector则用于管理后端的连接,NIOProcessor用于管理多线程事件处理,NIOReactor则用于完成底层的事件驱动机制,就是看起来和Mina和Netty的网络模型比较相似。如果有兴趣,大家还可以到Cobar站点的下载页面(https://github.com/alibaba/cobar)获取该项目的源码,感谢阿里人的付出!
最后说点题外话,目前国内关于mysql分布式中间有
360公司的Atlas:http://www.guokr.com/blog/475765/
淘宝的tddl:http://www.guokr.com/blog/475765/
京东的蓝海豚:http://cio.zdnet.com.cn/cio/2014/0731/3028990.shtml?fromrss=rss
网易的DDB:http://wenku.baidu.com/link?url=TiILF6KxWQBUu1bj2n8mA1E-_-RUESzjI7ALpo-mDWXW9uQv-0PCjmJrl9QH6ijP1ycFTXyz3plcrWgXOV80snuIVcMkLYNNKJA3EujCPTG
但是还是阿里的cobar好些,因为他开源了,除了中间件本身,还开源提供驱动、管理器。.
cobar admin按照
https://github.com/alibaba/cobar/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E7%AD%94
写在常见问题里面了:
1.修改WEB-INF/或者源码src/main/resource/中log4j日志输出路径,日志级别调整为INFO及以上 2.将WEB-INF/或者源码src/main/resource/中的cluster.xml, cobar.xml, user.xml,property.xml拷贝到某个固定目录,比如/home/admin/xml/ 3.修改WEB-INF/xmlpath.properties中文件内容为xmlpath=/home/admin/xml/ 4.源码打包,将war包放入web容器执行 5.user.xml记录的初始用户名和密码为root/123456
重启tomcat,进入登陆界面:

输入密码root,123456
进入系统。可以查看配置,访问情况。
同时可以增加cobar节点,节点的密码配置在conf/server.xml里面。
<!-- 用户访问定义,用户名、密码、schema等信息。 --> <user name="test"> <property name="password">test</property> <property name="schemas">dbtest</property> </user>
(http://img.blog.csdn.net/20150302194710221)
增加成功之后在节点管理里面就可以看到了。
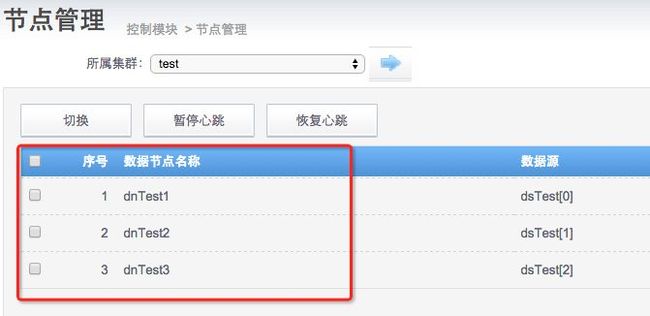
5,启动cobar-server
修改conf/schema.xml数据库连接地址。
然后启动报错:
#!Cobar#dnTest2 init failure
数据表没有创建。
#创建dbtest1 drop database if exists dbtest1; create database dbtest1; use dbtest1; #在dbtest1上创建tb1 create table tb1( id int not null, gmt datetime); #创建dbtest2 drop database if exists dbtest2; create database dbtest2; use dbtest2; #在dbtest2上创建tb2 create table tb2( id int not null, val varchar(256)); #创建dbtest3 drop database if exists dbtest3; create database dbtest3; use dbtest3; #在dbtest3上创建tb2 create table tb2( id int not null, val varchar(256));
**其中发现一个问题,如果使用Mariadb 5.5 查询不到数据表。
必须使用mysq数据库。我在centos6 上面安装的数据库可以(mysql 5.1.73),在centos7上面的mariaDB数据库就不行(MariaDB 5.5.40)。**
测试数据成功了。
# mysql -h127.0.0.1 -utest -ptest -P8066 -Ddbtest Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.1.48-cobar-1.2.7 Cobar Server (ALIBABA) Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show tables; +------------------+ | Tables_in_dbtest | +------------------+ | tb1 | | tb2 | +------------------+ 2 rows in set (0.00 sec) mysql> insert into tb1 (id, gmt) values (1, now()); Query OK, 1 row affected (0.02 sec) mysql> insert into tb2 (id, val) values (1, "part1"); Query OK, 1 row affected (0.01 sec) mysql> insert into tb2 (id, val) values (2, "part1"), (513, "part2"); Query OK, 2 rows affected (0.03 sec) mysql> select * from tb1; +----+---------------------+ | id | gmt | +----+---------------------+ | 1 | 2015-03-02 19:36:18 | +----+---------------------+ 1 row in set (0.01 sec) mysql> select * from tb2; +-----+-------+ | id | val | +-----+-------+ | 1 | part1 | | 2 | part1 | | 513 | part2 | +-----+-------+ 3 rows in set (0.00 sec)
5,总结
cobar 初步测试已经完成了。已经很好的解决了水平扩展和垂直扩展。
而且只需要修改配置就可以实现。完全可以平滑的切换过去。
作为程序员之所以被称为“Code Farmer”,足以说明离开code说事是难以说通的。还是直接上code吧。下面是一段shell脚本。在/etc/init.d/ 目录下创建名为cobar的文件,并给与授权“chmod u+x cobar”.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#!/bin/bash
#
#chkconfig:2345 80 90
#description:cobar
set JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.65.x86_64
set PATH=$JAVA_HOME/bin:$PATH
set CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
start(){
sh /home/cobar-server-1.2.7/bin/startup.sh
}
stop(){
sh /home/cobar-server-1.2.7/bin/shutdown.sh
}
restart(){
sh /home/cobar-server-1.2.7/bin/restart.sh
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
esac
|
当然关于startup.sh,shutdown.sh以及restart.sh这几个脚本的路径和Java环境变量还是以个人目录为准。
安装Service
执行以下Linux命令:
|
1
2
|
chkconfig --add cobar
service cobar start
|
当然停止Cobar即用命令service cobar stop,重启便是service cobar restart
设置开机自启动
|
1
|
chkconfig cobar on
|
产品约束
- 使用JDBC时,推荐使用5.1以上版本Driver进行连接
- 不支持跨库的关联操作:join、分页、排序、子查询。
- 不支持rewriteBatchedStatements=true参数设置。默认为false
- 不支持useServerPrepStmts=true参数设置。默认为false
- BLOB, BINARY, VARBINARY字段不能使用。若特殊需求需要这三种字段,禁止使用PreparedStatement的setBlob()或setBinaryStream()方法设置参数。
- 不支持SAVEPOINT操作。
- 不支持SET语句的执行,事务和字符集设置语句除外
- 对于拆分表(一个表的数据被映射到多个MySQL数据库),不能更新已有记录的拆分字段(分库字段)值
- 只支持MySQL数据节点。
- 对于拆分表,插入操作须给出列名,必须包含拆分字段。