Lucene学习总结
Lucene是当下十分流行的开源全文检索工具,在很多网站和系统中都得到了广泛应用(开源中国就是使用Lucene)。本人学习Lucene时间不长,水平有限,目前也还在学习探索阶段。现在将学习ucene过程中的知识点做以总结和归纳,期待和大家共同交流。Lucene并不是现成的搜索引擎,只算的上是Java开发的全文索引工具包。与传统的数据库查询比,全文索引技术更具有优势。Lucene不仅可以对数据库记录进行索引,也可以对磁盘文件进行索引(txt,word,excel,pdf等)。Lucene学习资料汇总 点击这里。
Lucene学习总结系列打算从以下几个方面介绍。
Lucene概述
入门实例
索引创建、更新和删除
分词
搜索结果排序
高亮关键字
第一部分:为什么使用Lucene
举个栗子,比如用户想查询博客系统中与“Lucene”相关的博客,在没有全文检索之前,我们可能只能依赖于数据库查询语句like来实现我们上述所说的功能,但这样做有几个明显的弊端:
当数据量大的时候,查询的速度很慢,效率很低,每次查询都得执行全表扫描,相同的查询无法复用;
查询的结果无法根据关键字相关性进行排序,设想一下如果查询结果数据量很大的情况下,让用户人工去筛选结果无疑是灾难性的;
现实中的数据可能是html,word,excel等文件格式的,而这类非结构化数据的查询则是数据库查询无法完成的。而Lucene通过其强大的索引体系很好的解决了问题。
此外,Lucene还具有以下几个优点:
索引文件格式独立于应用平台。Lucene自定义了一套以8字节为基础的索引文件格式,使得不同系统或者不同平台应用能够共享建立的索引文件;
在倒序索引的基础上实现了分块索引。能够针对新的文件建立小块的索引,提升索引速度,然后通过与原有索引的合并达到优化的目的;
优秀的面向对象设计,使得Lucene很容易学习和扩展,例如分词组件;
免费开源,适合各种平台,有各种语言的实现版本。例如C语言版本的:CLucene等等。
第二部分:Lucene的工作原理
Lucene的工作原理就是全文检索的基本原理。全文检索的原理可以查看这篇博客。下面这张图来自《Lucene in Action》是对Lucene工作原理的简明阐述。我把它划分为了左右两个部分以方便理解。
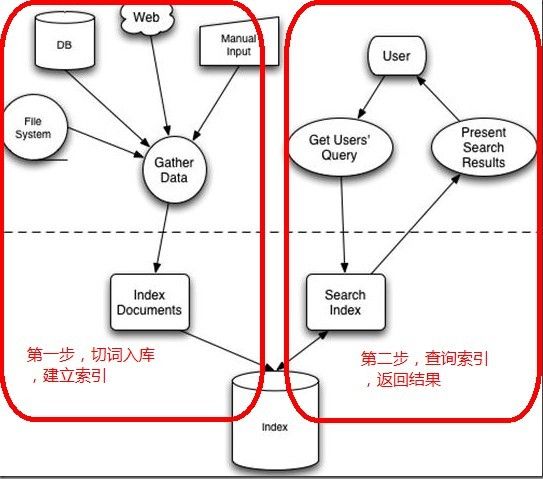
如上图所示,Lucene的工作原理可以简要的概括为两步:
第一步,切词入库,建立索引。Lucene对各类文档数据进行切词入库并建立索引,记录下各个词在各个文件中出现的次数和位置,生成独立的索引文件(索引库),这种索引称为倒序索引;
第二步,查询索引,返回结果。Lucene接收用户提交的查询,对查询进行分析然后去查询索引库,查询完成后返回结果给客户端。这两个过程中其实涉及了很多的细节,但为了方便理解我们先不涉及,后面会一一详细讲解。
第三部分:Lucene核心API
在使用Lucene前,我们先大致熟悉一下Lucene的几个核心类。
核心索引类:
public class IndexWriter
索引过程的中心组件,把它想象成一个可以对索引进行写操作的对象。
public abstract class Directory
Directory代表索引所在的位置,该抽象类有两个具体的子类实现。FSDirectory表示存储在文件系统的索引位置,RAMDirectory表示存储在内存中的索引的位置。
public abstract class Analyzer
分词组件。在建立索引前首先要对文档进行分词,Lucene默认有一些分词类的实现,自己实现的分词要继承该类。
public final class Document
Document类似于数据库中的一条记录,它由好几个字段Field组成。
public final class Field
Field用来描述文档的某个属性,例如文章的标题,内容等等。
核心搜索类:
public class IndexSeacher
用来在已经建好的索引上进行搜索操作
public final class Term
搜索的基本单元。Term对象有两个域组成。Term term = new Term("fieldName","queryWord");
public abstract class Query
抽象类,有很多具体实现类。该类主要作用把用户输入的查询语句转换为Lucene能够是别的query。
public final class Hits(TopDocs)
Hits是用来保存查询得到的结果的。最新版的Lucene中,TopDocs已代替了Hits。
第四部分:Lucene入门实例
第二节Lucene简介中有一张Lucene工作原理的图大家应该印象深刻。Lucene的实现原理其实就体现在这两个方面:
切词入库,建立索引;
查询索引,返回结果。
因此,使用Lucene去实现查询功能的过程也是按照上述过程进行的,这样理解了以后,写起来就很简单。
下面我们来看第一个简单的Lucene实现索引的例子(Lucene版本为4.10.1)。
public class LuceneDemo {
public static void main(String[] args){
//RAMDirectory(内存路径)继承自Directory抽象类,另一个继承自该类的是FSDirectory(文件系统路径),Directory dir = FSDirectory.open(new File("此处写索引存储的位置,"));
Directory dir = new RAMDirectory();
//SimpleAnalyzer继承自抽象类Analyzer,是分词组件,不同语言有不同的分词组件包,也可以自己定义实现该抽象类
Analyzer analyzer = new SimpleAnalyzer();
//定义IndexWriterConfig
IndexWriterConfig iwc = new IndexWriterConfig(Version.LATEST, analyzer);
//定义document对象
Document doc = new Document();
try {
//第一步,切词入库,创建索引。定义IndexWriter对索引进行“写”操作
IndexWriter iw = new IndexWriter(dir, iwc);
//Field对象的构造方法有四个参数,前两个参数表示要建立索引的name和value,name指索引的名称,value指要建立索引的“文档对象”,例如博客的标题、正文
//Field.Store有YES和NO两个值,表示是否存储该Field
//Field.Index有5个不同的取值,ANALYZED,ANALYZED_NO_NORMS,NOT_ANALYZED,NOT_ANALYZED_NO_NORMS,NO,根据不同情况选择是否分词
doc.add(new Field("title", "james bonde", Field.Store.YES, Field.Index.ANALYZED));
doc.add(new Field("content","He want to go to school next year.",Field.Store.YES,Field.Index.ANALYZED));
doc.add(new Field("doc","He will go to his mother's home.",Field.Store.YES,Field.Index.ANALYZED));
iw.addDocument(doc);
iw.close();
//第二步,查询索引,返回结果
IndexReader ir = DirectoryReader.open(dir);
//定义IndexSearcher
IndexSearcher is = new IndexSearcher(ir);
//定义Term,new Term("doc", "home"),第一个值表示要搜索的域,第二个则表示搜索值
Term term = new Term("doc", "home");
//TermQuery继承自Query抽象类,是Lucene最基本的查询
Query query = new TermQuery(term);
//执行查询,返回TopDocs对象结果集
TopDocs td = is.search(query, 10);
for(int i=0;i<td.scoreDocs.length;i++){
Document d = is.doc(td.scoreDocs[i].doc);
System.out.println("----------"+d.getField("title"));
System.out.println("----------"+d.getField("content"));
System.out.println("----------"+d.getField("doc"));
}
dir.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Lucene官方关于Field的几个属性值的用法:点击这里
第五部分:索引的创建、修改和删除
首先,我们来看一个例子:开源中国社区每天都有人发布新的博客,同时也有很多人在进行修改和删除博客的操作。如果我们只更新博客数据而不更新对应的索引数据,这会带来那些问题呢?
新增的博客信息不能够及时被用户搜索到;
修改的博客信息查询时依然显示之前的内容;
删除的博客信息查询时存在但实际已被删除。
因此,为了提高系统搜索的准确性和实时性,我们在进行数据更新的同时,也会更新与之对应的索引数据,这样业务数据就可以保持与索引数据的一致,上面的几个问题也就随之解决了。
首先,我们来看新增索引的操作,这个比较简单,之前的例子里面已经有讲到:
//当新增博客时,索引也增量更新
public void addLuceneIndex(Blog blog){
try {
IndexWriter writer = new IndexWriter(directory, config);
Document doc = new Document();
//文章id,需要存储,查询结果的链接需要,但不需要检索
doc.add(new Field("id",blog.getString("id"),Field.Store.YES,Field.Index.NO));
//文章标题,需要存储也需要切词索引
doc.add(new Field("title",blog.getString("title"),Field.Store.YES,Field.Index.ANALYZED));
//文章内容一般会比较长,所以不需要存储,但需要切词索引
doc.add(new Field("content",blog.getString("content"),Field.Store.NO,Field.Index.ANALYZED));
//文章作者,需要存储,整体索引但不切词
doc.add(new Field("author",blog.getString("author"),Field.Store.YES,Field.Index.NOT_ANALYZED));
writer.addDocument(doc);
writer.forceMerge(1);
writer.commit();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
当博客被修改时,对应索引也执行更新操作,实际后台代码执行的是先删除再新增操作。
//索引更新操作
public void updateLuceneIndex(Blog blog){
try {
IndexWriter writer = new IndexWriter(directory, config);
Document doc = new Document();
writer.updateDocument(new Term("id", blog.getString("id")), doc);
writer.forceMerge(1);
writer.commit();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
当文章删除时,对应索引也执行删除操作
//索引删除操作
public void delLuceneIndex(Blog blog){
try {
indexWriter.deleteDocuments(new Term("id", blog.getString("id"))); // Document删除
} catch (IOException e) {
e.printStackTrace();
}
}
最后说明一下,索引文件的增、删、改在实际应用过程中也是有很多策略的。比如对于搜索实时性要求比较高的系统,可以采取实时更新的策略,在更新记录时同时更新索引;如果系统对搜索的实时性要求不高,且服务器资源有限,可以设置一个定时任务,把白天更新的记录都标记出来,在凌晨服务器空闲的时候批量更新。总之,可以根据自己的需要去灵活的应用。
第六部分:分词(切词)
分词也叫作切词,是指把文档的内容按照一定的规则切分成一个个独立的词语,通俗的说就是把句子切分成词语。分词是影响Lucene查询效率和查询准确率的关键因素。所有的分词器都继承自Lucene的Analyzer,今天介绍最流行和通用的中文分词器IKAnalyzer的使用。
Lucene默认实现的有英文分词。英文分词相对简单,主要是对每个单词的单复数,时态等做转换即可。而中文分词相对更复杂一些。因为中文的词库本身就非常庞杂,同一个句子可能有好几种分词法,不同的分词法可能就会导致不同的查询结果。IKAnalyzer为我们解决以上问题提供了很好的方案,它允许我们可以个性化定义扩展词库,而且分词效率极高。
下面我们来看下IKAnalyzer的配置文件IKAnalyzer.cfg.xml,把它放置到源文件根目录下面,系统会自动加载进来。
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IKAnalyzer扩展配置</comment> <!--用户可以在这里配置自己的扩展字典--> <entry key="ext_dict"> /com/jfinal/lucene/ext.dic; /com/jfinal/lucene/ft_main2012.dic; /com/jfinal/lucene/ft_quantifier.dic; </entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"> /com/jfinal/lucene/stop.dic </entry> </properties>
ext.dic用来定义自己的扩展词库。比如特定的地名,人名,就相当于告诉分词器如果遇到这些词汇就把它们做单独分词;
stop.dic用来定义自己的扩展停止词字典,停止词就是指那些最普通的,没有特定含义的词。比如英语里面的a ,the,汉语里面的了,又等等。
把IKAnalyzer的jar包拷贝到lib下,使用时新建对象即可。
Analyzer analyzer = new IKAnalyzer()