TCP Silly Window Syndrome
In the topic describing TCP's Maximum Segment Size (MSS) parameter, I explained the trade-off in determining the optimal size of TCP segments. If segments are too large, we risk having them become fragmented at the IP level. Too small, and we get greatly reduced performance because we are sending a small amount of data in a segment with at least 40 bytes of header overhead. We also use up valuable processing time that is required to handle each of these small segments.
The MSS parameter ensures that we don't send segments that are too large—TCP is not allowed to create a segment larger than the MSS. Unfortunately, the basic sliding windows mechanism doesn't provide any minimum size of segment that can be transmitted. In fact, not only is itpossible for a device to send very small, inefficient segments, the simplest implementation of flow control using unrestricted window size adjustmentsensures that under conditions of heavy load, window size will become small, leading to significant performance reduction!
How Silly Window Syndrome OccursTo see how this can happen, let's consider an example that is a variation on the one we’ve been using so far in this section. We'll assume the MSS is 360 and a client/server pair where again, the server's initial receive window is set to this same value, 360. This means the client can send a “full-sized” segment to the server. As long as the server can keep removing the data from the buffer as fast as the client sends it, we should have no problem. (In reality the buffer size would normally be larger than the MSS.)
Now, imagine that instead, the server is bogged down for whatever reason while the client needs to send it a great deal of data. For simplicity, let's say that the server is only able to remove 1 byte of data from the buffer for every 3 it receives. Let's say it also removes 40 additional bytes from the buffer during the time it takes for the next client's segment to arrive. Here's what will happen:
- The client's send window is 360, and it has lots of data to send. It immediately sends a 360 byte segment to the server. This uses up its entire send window.
- When the server gets this segment it acknowledges it. However, it can only remove 120 bytes so the server reduces the window size from 360 to 120. It sends this in the Window field of the acknowledgment.
- The client receives an acknowledgment of 360 bytes, and sees that the window size has been reduced to 120. It wants to send its data as soon as possible, so it sends off a 120 byte segment.
- The server has removed 40 more bytes from the buffer by the time the 120-byte segment arrives. The buffer thus contains 200 bytes (240 from the first segment, less the 40 removed). The server is able to immediately process one-third of those 120 bytes, or 40 bytes. This means 80 bytes are added to the 200 that already remain in the buffer, so 280 bytes are used up. The server must reduce the window size to 80 bytes.
- The client will see this reduced window size and send an 80-byte segment.
- The server started with 280 bytes and removed 40 to yield 240 bytes left. It receives 80 bytes from the client, removes one third, so 53 are added to the buffer, which becomes 293 bytes. It reduces the window size to 67 bytes (360-293).
This process, which is illustrated in Figure 228, will continue for many rounds, with the window size getting smaller and smaller, especially if the server gets even more overloaded. Its rate of clearing the buffer may decrease even more, and the window may close entirely.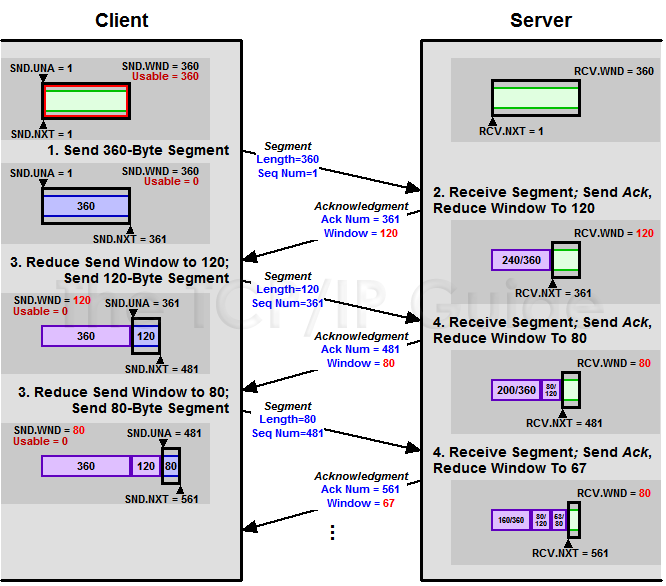
Figure 228: TCP “Silly Window Syndrome”
This diagram shows one example of how the phenomenon known as TCP silly window syndrome can arise. The client is trying to send data as fast as possible to the server, which is very busy and cannot clear its buffers promptly. Each time the client sends data the server reduces its receive window. The size of the messages the client sends shrinks until it is only sending very small, inefficient segments.
(Note that in this diagram I have shown the server’s buffer fixed in position, rather than sliding to the right as in the other diagrams in this section. This way you can see the receive window decreasing in size more easily.
Let's suppose this happens. Now, eventually, the server will remove some of the data from this buffer. Let's say it removes 40 bytes by the time the first closed-window “probe” from the client arrives. The server then reopens the window to a size of 40 bytes. The client is still desperate to send data as fast as possible, so it generates a 40-byte segment. And so it goes, with likely all the remaining data passing from the client to the server in tiny segments until either the client runs out of data, or the server more quickly clears the buffer.
Now imagine the worst-case scenario. This time, it is the application process on the server that is overloaded. It is drawing data from the buffer one byte at a time. Every time it removes a byte from the server's buffer, the server's TCP opens the window with a window size of exactly 1 and puts this in theWindow field in an acknowledgment to the client. The client then sends a segment with exactly one byte, refilling the buffer until the application draws off the next byte.
The Cause of Silly Window Syndrome: Inefficient Reductions of Window Size
None of what we have seen above represents a failure per se of the sliding window mechanism. It is working properly to keep the server's receive buffer filled and to manage the flow of data. The problem is that the sliding window mechanism is only concerned with managing the buffer—it doesn't take into account the inefficiency of the small segments that result when the window size is micromanaged in this way.
In essence, by sending small window size advertisements we are “winning the battles but losing the war”. Early TCP/IP researchers who discovered this phenomenon called it silly window syndrome (SWS), a play on the phrase “sliding window system” that expresses their opinion on how it behaves when it gets into this state.
The examples above show how SWS can be caused by the advertisement of small window sizes by a receiving device. It is also possible for SWS to happen if the sending device isn't careful about how it generates segments for transmission, regardless of the state of the receiver's buffers.
For example, suppose the client TCP in the example above was receiving data from the sending application in blocks of 10 bytes at a time. However, the sending TCP was so impatient to get the data to the client that it took each 10-byte block and immediately packaged it into a segment, even though the next 10-byte block was coming shortly thereafter. This would result in a needless swarm of inefficient 10-data-byte segments.
Silly Window Syndrome Avoidance Algorithms
Since SWS is caused by the basic sliding window system not paying attention to the result of decisions that create small segments, dealing with SWS is conceptually simple: change the system so that we avoid small window size advertisements, and at the same time, also avoid sending small segments. Since both the sender and recipient of data contribute to SWS, changes are made to the behavior of both to avoid SWS. These changes are collectively termed SWS avoidance algorithms.
Receiver SWS AvoidanceLet's start with SWS avoidance by the receiver. As we saw in the initial example above, the receiver contributed to SWS by reducing the size of its receive window to smaller and smaller values due its being busy. This caused the right edge of the sender's send window to move by ever-smaller increments, leading to smaller and smaller segments. To avoid SWS, we simply make the rule that the receiver may not update its advertised receive window in such a way that this leaves too little usable window space on the part of the sender. In other words, we restrict the receiver from moving the right edge of the window by too small an amount. The usual minimum that the edge may be moved is either the value of the MSS parameter, or one-half the buffer size, whichever is less.
Let's see how we might use this in the example above. When the server receives the initial 360-byte segment from the client and can only process 120 bytes, it does not reduce the window size to 120. It reduces it all the way to 0, closing the window. It sends this back to the client, which will then stop and not send a small segment. Once the server has removed 60 more bytes from the buffer, it will now have 180 bytes free, half the size of the buffer. It now opens the window up to 180 bytes in size and sends the new window size to the client.
It will continue to only advertise either 0 bytes, or 180 or more, not smaller values in between. This seems to slow down the operation of TCP, but it really doesn't. Because the server is overloaded, the limiting factor in overall performance of the connection is the rate at which the server can clear the buffer. We are just exchanging many small segments for a few larger ones.
Sender SWS Avoidance and Nagle's Algorithm
SWS avoidance by the sender is accomplished generally by imposing “restraint” on the part of the transmitting TCP. Instead of trying to immediately send data as soon as we can, we wait to send until we have a segment of a reasonable size. The specific method for doing this is called Nagle's algorithm, named for its inventor, John Smith. (Just kidding, it was John Nagle. J) Simplified, this algorithm works as follows:
- As long as there is no unacknowledged data outstanding on the connection, as soon as the application wants, data can be immediately sent. For example, in the case of an interactive application like Telnet, a single keystroke can be “pushed” in a segment.
- While there is unacknowledged data, all subsequent data to be sent is held in the transmit buffer and not transmitted until either all the unacknowledged data is acknowledged, or we have accumulated enough data to send a full-sized (MSS-sized) segment. This applies even if a “push” is requested by the user.
This might seem strange, especially the part about buffering data despite a push request! You might think this would cause applications like Telnet to “break”. In fact, Nagle's algorithm is a very clever method that suits the needs of both low-data-rate interactive applications like Telnet and high-bandwidth file transfer applications.
If you are using something like Telnet where the data is arriving very slowly (humans are very slow compared to computers), the initial data (first keystroke) can be pushed right away. The next keystroke has to wait for an acknowledgment, but this will probably come reasonably soon relative to how long it takes to hit the next key. In contrast, more conventional applications that generate data in large amounts will automatically have the data accumulated into larger segments for efficiency.
Nagle’s algorithm is actually far more complex than this description, but this topic is already getting too long. RFC 896 discusses it in (much) more detail.