理解Postgres性能
理解Postgres性能
对于很多应用程序开发人员来说数据库就是一个黑盒子。在数据进进出出之间,开发人员希望它的时间跨度短点。不用成为DBA,这里有一些可以为大多数应用程序开发人员所理解的数据来帮助他们理解他们的数据库表现是否足够好。这篇文章将会提供一些小提示,帮助你判断是否你的数据库的性能降低了程序的性能,以及如果那样的话你该怎么做。
理解缓存和缓存命中率
对于大多数应用来说典型的判断规则是哪部分数据是经常访问的。同其他一样都服从80/20法则,就是20%的数据占据着80%的读,并且有时更高。Postgres它会跟踪你数据的模式并且还会把经常访问的数据保存到缓存中。一般来说你希望数据库能够有99%的缓存命中率。你可以查看缓存命中率:
SELECT sum(heap_blks_read) as heap_read, sum(heap_blks_hit) as heap_hit, sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio FROM pg_statio_user_tables;我们可以这个在 dataclip上显示 Heroku Postgres的缓存命中率为99.99%。如果你发现比例低于99%,那么你可能想要考虑增加数据库的缓存可用性了,你可以在Heroku Postgres上使用 快速提升数据库性能 或者在像EC2之类的上使用dump/restore组成一个更大的实例来提升性能。
理解索引用途
其它主要提升性能的方式就是索引了。一些框架会为你的主键添加索引,但是如果你在其它字段搜索或者大量的联接时,你可能需要手动添加那样的索引了。
索引是最有价值的对于大表更是如此。同时从缓存中访问数据比从磁盘更快,即使数据在内存中可能会变慢因为Postgres必须要解析成百上千的行来确定这是不是它们曾经已处理过的条件。为了得到在你数据库中表的索引使用时间百分比并且按照表从大到小顺序显示,你可以执行这样的语句:
SELECT
relname,
100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used,
n_live_tup rows_in_table
FROM
pg_stat_user_tables
WHERE
seq_scan + idx_scan > 0
ORDER BY
n_live_tup DESC; 然而这里没有最完美的答案,如果在某些地方访问超过10,000行数据时命中率在99%左右时,你可以考虑添加索引了。当检查在哪里添加索引你应该参照你所运行的查询类型了。一般来说,你应该在使用其它id来查询或者你经常要过滤的值如created_at字段的地方添加索引。
专业提示:如果你在产品数据库中使用CREATE INDEX CONCURRENTLY来添加索引的话,请在后台建立索引以及不要持有表锁。同时创建索引的局限是它一般会多花2-3倍时间来创建并且不会在事务中执行。即使对于任何大型产品网站,这些取舍对您的最终用户是值得的。
Heroku Dashboard示例
使用最近访问Heroku dashboard作为现实世界的示例,我们可以运行这样的查询语句以及运行结果:
# SELECT relname, 100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used, n_live_tup rows_in_table FROM pg_stat_user_tables ORDER BY n_live_tup DESC;
relname | percent_of_times_index_used | rows_in_table
---------------------+-----------------------------+---------------
events | 0 | 669917
app_infos_user_info | 0 | 198218
app_infos | 50 | 175640
user_info | 3 | 46718
rollouts | 0 | 34078
favorites | 0 | 3059
schema_migrations | 0 | 2
authorizations | 0 | 0
delayed_jobs | 23 | 0 从这里我们可以看到events表有接近700,000行被使用了但是却没有索引。从这里你可以研究我的应用以及看出一些所使用的通用查询语句,一个例子就是把博客推送到你那里。你可以执行EXPLAIN ANALYZE来看你的execution plan,对于特定的查询语句的性能来说它可以给你更好的主意。
EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559; QUERY PLAN ------------------------------------------------------------------- Seq Scan on events (cost=0.00..63749.03 rows=38 width=688) (actual time=2.538..660.785 rows=89 loops=1) Filter: (app_info_id = 7559) Total runtime: 660.885 ms在给定的顺序遍历所有数据这方面使用索引我们可以得到优化。你可以同时添加索引来阻止锁定表,并且查看性能怎么样:
CREATE INDEX CONCURRENTLY idx_events_app_info_id ON events(app_info_id); EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559; ---------------------------------------------------------------------- Index Scan using idx_events_app_info_id on events (cost=0.00..23.40 rows=38 width=688) (actual time=0.021..0.115 rows=89 loops=1) Index Cond: (app_info_id = 7559) Total runtime: 0.200 ms同时在这单一的查询语句中我们可以看到明显的改进,我们可以在 New Relic上检验这个结果,并且可以看到使用这个索引以及其它一些索引减少了我们在数据库上所花的时间。
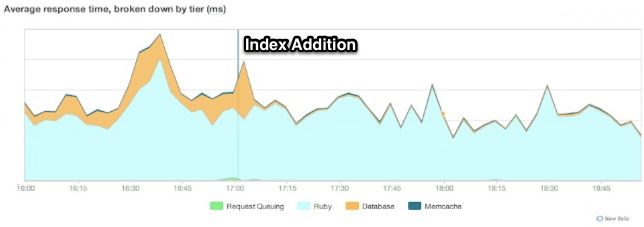
索引缓存命中率
最后两者结合,如果你对有多少索引在你的缓存中感兴趣的话,你可以运行:
SELECT sum(idx_blks_read) as idx_read, sum(idx_blks_hit) as idx_hit, (sum(idx_blks_hit) - sum(idx_blks_read)) / sum(idx_blks_hit) as ratio FROM pg_statio_user_indexes;一般来说,你应该要求这个达到99%,和你一般缓存命中率一样。
原文:understanding-postgres-performance