小试PostgreSQL + PGPool-II 进行主从复制(同步)+负载均衡
PostgreSQL + PGPool-II 进行主从复制+负载均衡
一、准备软件
下载pgsql:http://www.postgresql.org/ftp/source/v9.3.5/
wget ‘https://ftp.postgresql.org/pub/source/v9.3.5/postgresql-9.3.5.tar.gz’
yum install gcc
tar -zxvf postgresql-9.3.5.tar.gz
cd
./configure --prefix=/opt/pgsql
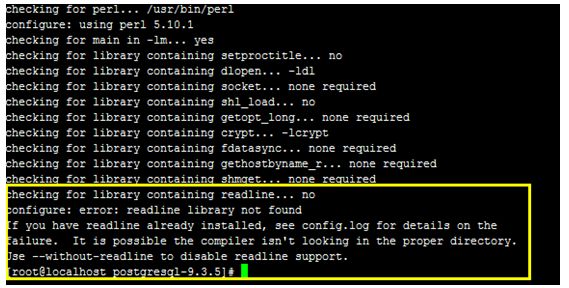
根据提示,应该是没有安装 readline包。
检查系统是否安装 readline 包 rpm -qa | grep readline
说明系统已经安装了 readline包。
通过 yum 搜索相关的readline 包 yum search readline
根据提示,有一个包引起了我的注意 "readline-devel",猜想可能与这个包有关。
安装 readline-devel 包
yum install readline-devel
关于 readline 的解释,来自官网
--without-readline
Prevents use of the Readline library (and libedit as well). Thisoption disables command-line
editing and history in psql, so it is notrecommended.
说明: 根据步骤2 执行 configure时报错提示,可以加上 "--without-readline" 从而避开这个ERROR,
但Postgresql官方不推荐这么做,所以还是安装吧。
继续./configure --prefix=/opt/pgsql
make
mak install
二、配置pgsql(Postgresql的hot standby 配置)
创建postgres用户:useradd postgres,设置密码passwd postgres
使用postgres登陆:su - postgres
设置用户postgres环境变量:vim .bash_profile
PATH=$PATH:$HOME/bin
export PGHOME=/opt/pgsql
export PGDATA=~/data
export PATH=$PATH:$PGHOME/bin:$PGDATA/bin
应用环境变量生效source .bash_profile
执行initdb,初始化数据
测试启动pg_ctl start
在主节点上新建一个rep用户用于复制:create user rep SUPERUSER ENCRYPTED PASSWORD '123456';
启动成功后,开始配置(主节点Master的)postgresql.conf
更改:
listen_addresses = '*'
max_connections = 100 #(可以设置大点,为程序提供连接数保证)
wal_level=hot_standby #(设置模式为hot standby)
max_wal_senders=5 #(设置wal发送的进程数量)
wal_keep_segments=1000 #(设置log file 的段大小)
synchronous_standby_names = 'synccluster1' #(同步复制的节点名称,slave节点会被指定在这里)
#开启详细日志:
log_destination = 'stderr'
log_directory = 'pg_log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_rotation_size = 64MB
client_min_messages = info
log_min_messages = info
log_min_error_statement = info
log_error_verbosity = verbose
log_statement = 'all'
配置(主节点Master的)pg_hba.conf
1.增加从库的访问权限:(192.168.4.205是我开发机器的ip、192.168.4.33是从库的ip)
host all all 192.168.4.205/32 md5 #增加远程访问权限
host all rep 192.168.4.33/32 md5 #增加rep用户的远程访问
host replication rep 192.168.4.33/32 md5#增加rep的复制权限
Host all all 127.0.0.1/32 trust
#这个是后来需要用pgpool才增加本地链接直接信任不需要输入密码
(replication是虚拟的数据库,用于standby来复制)
【注意:在主库配置完并把data目录拷贝到从库的时候,这个绿色部分将被删除】
启动主节点:pg_ctl start(注意启动的时候可能没有/tmp的权限,chown -R postgres /tmp)

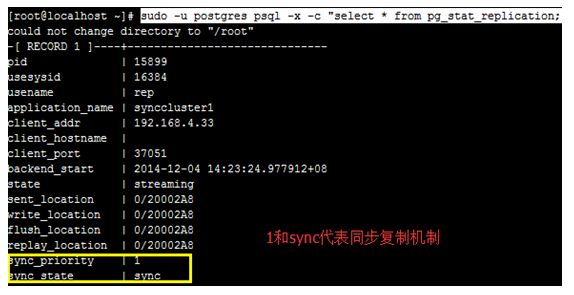
可以看到LOG: standby "node1" is now the synchronous standby with priority 1 模式为同步复制。
standby "synccluster1" is now the synchronous standby with priority 1(这里如果从节点配置好后这里会显示在线的从节点同步的数量)
主库做一次基础备份:
su postgres
psql
select pg_start_backup('/home/postgres/data/backup_test');
等待基础备份完毕后用
scp data/* postgres@slave :/home/postgres/data/.
设置步骤(3、4)的环境变量
【注意:不需要执行initdb,增加步骤9中主库的信任,如下:】
host all all 192.168.4.205/32 md5 #增加远程访问权限
host all rep 192.168.4.33/32 md5 #增加rep用户的远程访问
#host replication rep 192.168.4.33/32 md5#增加rep的复制权限(这个可以删除)
#增加:
Host all all 192.168.4.121/32 trust #直接信任主库来ide链接
Host all all 127.0.0.1/32 trust
更改从库的postgresql.conf下:
port=5432
hot_standby=on
删除postmaster.pid文件
为从节点增加recovery.conf配置文件,做法如下
(1)拷贝/opt/pgsql/share/recovery.conf.sample 到data目录下并且命名为recovery.conf
(2)更改配置:
【注意:
1.archive_cleanup_command默认没有,需要在/data/postgresql-9.3.5/contrib/pg_archivecleanup
目录下进行make和make install安装,自动会复制到pgsql/bin目录下
2./home/postgres/data/pg_xlog是xlog复制的日志目录】
archive_cleanup_command = '/opt/pgsql/bin/pg_archivecleanup /home/postgres/data/pg_xlog %r'
standby_mode=on
primary_conninfo='host=主库ip192.169.4.121 port=5432 user=rep复制流的用户 password=123456
application_name=node1这里很重要,这里是从服务器指定的同步复制节点名称之一先不写,等待都启动完毕成功后加入同步复制的节点名称'
trigger_file = '/home/postgres/trigger_active.5432' #这里还没弄懂
启动子节点slave:pg_ctl start(注意启动的时候可能没有/tmp的权限,chown -R postgres /tmp)
用户客户端进行插入来观察同步的情况,从主节点查看所有从节点同步的情况:
Psql 查看select * from pg_stat_replication;节点情况
设置服务和自动启动:
1.进入源码目录cd /data/postgresql-9.3.5/contrib/start-scripts/
2.把linux文件赋予执行权限chmod a+x linux
3.复制到/etc/init.d cp linux /etc/init.d/postgresql
4.chkconfig --add postgresql
备库节点故障导致主节点事务无法提交的排除方法
采用同步复制模式后,如果备库节点服务器出现故障,将会导致主节点的事务无法提交,会一直等下去,这样一般有二种解决方法:
(1)屏掉主节点的synchronous_standby_names,即前面加上#,如
synchronous_standby_names = 'synccluster1,synccluster2'
修改成
#synchronous_standby_names = 'synccluster1,synccluster2'
修改后保存,再reload一下,这时复制模式全部会转换成异步复制模式,如下所示
(2)把备库开起来,不过这个出故障,可能一时半会故障问题不一定能解决
备注:目前只能支持同一时刻只有1个同步角色,并且同步角色是可以切换的
安装PGpool:http://pgpool.projects.pgfoundry.org/pgpool-II/doc/pgpool-zh_cn.html
下载PGPool
http://www.pgpool.net/mediawiki/index.php/Downloads
http://www.pgpool.net/download.php?f=pgpool-II-3.4.0.tar.gz
安装PGPool
./configure --prefix=/opt/pgpool --with-pgsql=/opt/pgsql
配置PGPool
拷贝:pgpool.conf.sample 为pgpool.conf
配置pgpool.conf
listen_addresses = '*'
backend_hostnameX = 'localhost' #(X索引为0~N为数据库台数)
# Host name or IP address to connect to for backend 0
backend_portX = 5432
# Port number for backend 0
backend_weightX = 1
# Weight for backend 0 (only in load balancing mode)
backend_data_directoryX = '/home/postgres/data'
# Data directory for backend 0
backend_flagX = 'ALLOW_TO_FAILOVER'
# Controls various backend behavior
# ALLOW_TO_FAILOVER or DISALLOW_TO_FAILOVER
backend_hostname1 = '192.168.4.33' #下面为第二台服务器配置
backend_port1 = 5433
backend_weight1 = 1
backend_data_directory1 = '/home/postgres/data'
backend_flag1 = 'ALLOW_TO_FAILOVER
pool_passwd = 'pool123456' #pgpool 9999端口的链接密码
enable_pool_hba = on 开启pool_hba验证
pool_passwd = 'pool_passwd' 验证文件(pool_passwd格式为,客户端连接到pgpool的账户名 root:md5生成的密码)
master_slave_mode = on #开启主备模式
master_slave_sub_mode = 'stream' #开启流模式
load_balance_mode = on #开启负载模式
拷贝:pcp.conf.sample 为pcp.conf
配置pgpool.conf
更改管理账户和密码,采用/opt/pgpool/bin/pg_md5 -p 生成密码#(这里主要用来管理pgpoll的账户,可以在主动新增节点的时候进行用到账户和密码)
pgpool:e10adc3949ba59abbe56e057f20f883e #(123456)
更改pool_hba.conf
增加控制如下:
host all all 192.168.4.205(客户端)/32 trust
host all all 192.168.4.33(从数据库)/32 trust
host all all 192.168.4.121(主数据库)/32 trust
启动pgpool
建议启动脚本写入/opt/pgpool/bin/start.sh中:
./pgpool -n -d > /tmp/pgpool.log 2>&1 &
用控制台进入pgpool的客户端界面
psql -h localhost -p 9999
常用管理语法:
show pool_version;查看pool的版本
show pool_nodes;查看pool的节点
节点状态注意:

Status 由数字 [0 - 3]来表示。0 - 该状态仅仅用于初始化,PCP从不显示它。1 - 节点已启动,还没有连接。2 - 节点已启动,连接被缓冲。3 - 节点已关闭。
在节点关闭或者为0的时候可以用pgpool的pcp_attach_node命令来动态增加节点,包括以后动态扩充节点也可以:
./pcp_attach_node -d 5 localhost 9898 pgpool 123456 1
-d 是debug的模式,5是级别,
localhost是代表pgpool的ip地址
9898是pgpool的默认管理pcp端口
pgpool 123456是刚刚建立在pcp.conf的管理用户名和密码
1:代表是查询到的pool_nodes的序号
show pool_status;查看pool的状态
show pool_processes;查看pool中正在执行的进程
1
安装pgbench
/data/postgresql-9.3.5/contrib/pgbench
make和make install
准备一个select查询例如:select * from tables;然后放入select.sql文件中。在源码中找到
/opt/pgsql/bin/pgbench -c 25 -j 25 -M prepared -n -s 500 -T 60 -f select.sql -h localhost -p 9999 -U postgres postgres
自己测试情况:
开启pgpool后,主、从正常情况下采用命令可以进行select分发(主要测试并发情况)
在事务中具有隔离性,事务的所有语句都在主库上
Pgbench可以测试tps
如果主库停止后所有的插入无法插入,仅仅可进行查询(由于从库无法改变角色,因为只是only read)
如果从库停止后所有的插入、update、delete和查询走主库,但是非查询语句会hold住,此时恢复从库启动后可插入成功【备注:程序一定要有检查事务超时机制】,并且从库需要2台以上,还需要测试2太从库,如果有一台宕掉服务后的情况????
开启同步模式的风险
若开启同步模式,第一个standby 节点的状态直接影响到主库,若第一个 standby 节点 crash ,而又没有其它
standby 节点顶上,那么主库上的所有操作将会被 HANG 住,直到从点恢复;主库才恢复正常,如果是很重要的业务,
建议至少配置两个 standby 节点,提高高可用性。
理论上开启了同步功能会对主库的性能有所影响,今天没有详细地测试。
做hot standby时要注意的一些地方:
<1>、做hot_standby基础备份时做vacuum full有时会导致执行失败
<2>、wal_keep_segments参数值最小17
<3>、如果在做基础备份时,wal没传输前就被复盖就是导致启动salve时失败,会提示xxxxxxxxxxxxxxxxxxx WAL已经被移徐所以wal_keep_segments要设置到足够做完基础备份的时间才行
<4>、遇见trigger文件出现时,salve主机会无条件重启(-m immediate),并且从这时开始不能再放入一个recovery.conf来进行流复制(那怕你能slave什么运作都没做),只能通过再做一次基础备份来实现流复制
<5>、在同一台机子上两个不同的集群同步,如果master删除表空间,并且把表空间目录一起删除的话,而slave此时还没有同步过来,则slave启动时老会提示表空间目录已经不存在,并且会导致启动失败,解决办法是把目录重新建立回来,等待slave做完同步后再把目录删除就没问题
<6>、hot standby无法实现Linux平台和windows平台下的两个节点数据同步
问题:
PostgreSQL服务启动时报错:FATAL: could not create lock file "/tmp/.s.PGSQL.5432.lock": 权限不够
http://hi.baidu.com/11haiou/item/66e75c21d32f2f1d72863e14
http://hi.baidu.com/11haiou/item/bd883bd47be29bedcb0c390b
测试:
http://blog.163.com/czg_e/blog/static/4610456120111186721528/
postgresql9.1准实时同步测试
http://blog.163.com/czg_e/blog/static/4610456120111186721528/
Postgresql 恢复一例
http://francs3.blog.163.com/blog/static/40576727201081810497150/?suggestedreading