红帽子RHCS套件安装与配置(二)
系统环境:
RHEL6.4 iptables 关闭 selinux is disabled
https://access.redhat.com/site/documentation/en-US 参照文档
注意:由于本实验环境是在RHEL系列,因此将使用红帽自己的yum源,配置如下:
[base]
name=yum
baseurl=ftp://192.168.2.22/pub/RHEL6.4
gpgcheck=0
[HA]
name=ha
baseurl=ftp://192.168.2.22/pub/RHEL6.4/HighAvailability
gpgcheck=0
[lb]
name=LB
baseurl=ftp://192.168.2.22/pub/RHEL6.4/LoadBalancer
gpgcheck=0
[Storage]
name=St
baseurl=ftp://192.168.2.22/pub/RHEL6.4/ResilientStorage
gpgcheck=0
[SFS]
name=FS
baseurl=ftp://192.168.2.22/pub/RHEL6.4/ScalableFileSystem
gpgcheck=0
实验将用到三台主机,一台安装luci进行配置管理RHCS集群,另外两台主机安装ricci,用来管理集群所用到的服务并且和luci进行通信。(ricci作为计算节点,必须进行时间同步)
luci管理端:
#yum update luci -y
#/etc/init.d/luci restart 将会提示登录一个地址,访问luci界面,默认为用户名和密码root用户
ricci计算节点端: (注意:所有节点之间必须用hostname进行解析)
#yum install ricci -y
#passwd ricci
#/etc/init.d/ricci restart
#chkconfig ricci on
在luci端进行创建集群,并且添加节点:(图)

创建一个集群,并添加node节点


添加成功,两个节点正常

查看node1详细信息
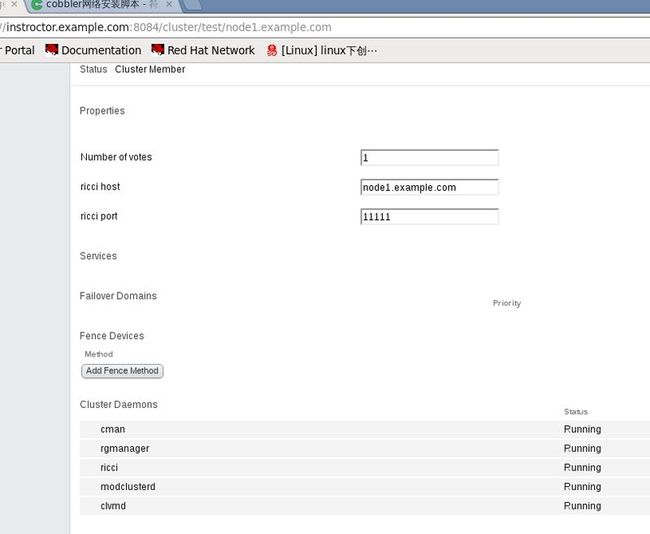
成功后,使用命令查看
# clustat 可以看到,有node1和node2节点
Cluster Status for test @ Sat May 17 12:01:23 2014
Member Status: Quorate
Member Name ID Status
node1.example.com 1 Online, Local
node2.example.com 2 Online
根据luci管理和配置界面的相关预设配置来进行配置红帽集群套件:(一次进行配置fence,failover,resources,services)

安装fence(解决多个节点间因为互相争夺资源而产生的脑裂问题,当某节点出现问题,会将节点立即拔电重启)
本节实验将采用KVM提供的虚拟fence
在luci端:
# yum install fence-virt.x86_64 fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64 -y
#/etc/fence_virt.conf fence配置文件,默认不是规则的
# fence_virtd -c 交互式配置fence文件
Interface [none]: br0 在选择接口时选择br0,其余都默认
#mkdir /etc/cluster 默认不存在cluster目录来存放key文件,自己建立
#dd if=/dev/urandom of=/etc/cluster/fence.xvm.key bs=128 count=1
1+0 records in
1+0 records out
128 bytes (128 B) copied, 0.000378488 s, 338 kB/s
# ll /etc/cluster/fence.xvm.key
# scp /etc/cluster/fence.xvm.key node1:/etc/cluster/ 拷贝到两个节点,用来通信的
# scp /etc/cluster/fence.xvm.key node2:/etc/cluster/
# /etc/init.d/fence_virtd restart 开启fence服务(生产环境中自动开启哦)
# netstat -anulp |grep fence*
udp 0 0 0.0.0.0:1229 0.0.0.0:* 18904/fence_virtd
登录luci管理界面,增加fence设备,并且为每个node添加fence设置
# fence_xvm -H node1 测试fence功能
注意:如果不能node节点不能启动,注意查看rgmanager,cman ricci,clvm等服务的自动启动
# tail -f /var/log/cluster/fenced.log
May 17 11:59:55 fenced fenced 3.0.12.1 started
May 17 12:19:15 fenced fenced 3.0.12.1 started
May 17 15:25:58 fenced fencing node node1
May 17 15:26:00 fenced fence node1 success
May 17 15:28:24 fenced fenced 3.0.12.1 started
3.配置故障转换域
故障切换域是一个命名的集群节点子集,它可在节点失败事件中运行集群服务
在由几个成员组成的集群中,使用限制故障切换域可最大程度降低设置集群以便运行集群服务的工作(比如
httpd),它要求您在运行该集群服务的所有成员中进行完全一致的配置。您不需要将整个集群设置为运行
该集群服务,只要设置与该集群服务关联的限制故障切换域中的成员即可。
故障转移域,权值越低,优先级越高
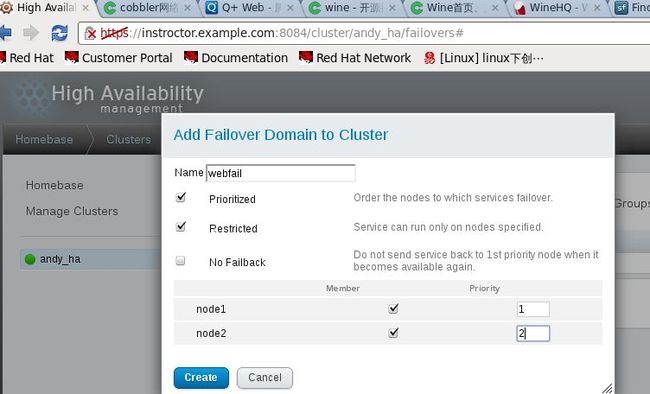
4.配置全局集群资源
增加VIP,apcache,服务(通过script完成)


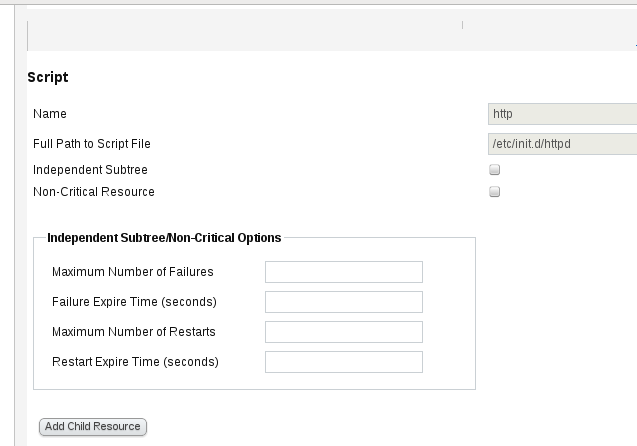

5.配置资源组

为webserver分别添加子资源:VIP,httpd服务,以及共享磁盘
# clustat 查看资源现在在node1上运行
Member Name ID Status
------ ---- ---- ------
node1 1 Online, Local, rgmanager
node2 2 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:webserver node1 started
测试:
(配置了故障转移域的默认只开启优先级高node1的httpd服务,主机httpd异常关闭后在开启优先级低的node2)
注意:在测试中,httpd服务不需要启动和重启,资源完全被luci接管
访问ip资源(VIP)192.168.2.88 访问的使node1发布的资源(http)
测试:关闭服务和关闭网卡,测试服务的发布
(高可用性的性能测试99)
1.关闭node1的httpd服务,发现会自动被node2接管(故障转移域)
2.发现,当关闭node2网卡的时候,由于配置了fence设备,node2会自动重启,资源会由node1接管
3.# echo c > /proc/sysrq-trigger
在node1上给内核导入参数,测试崩溃效果。node2会自动接管资源,node1会必fence自动重启,之后node1会重新接管资源(faildomain的自动回切功能)
clusvcadm -d httpd 手动关闭服务组
clusvcadm -e httpd 开启服务组
clusvcadm -r httpd -m node1 将服务定位到node1
详细命令查看官网
使用RHCS套件构建一个简单的web集群已经完成。