- Hibernate ORM 映射深度解析
后端
在Java持久层技术体系中,Hibernate作为经典的ORM(对象关系映射)框架,通过自动化对象与数据库表的映射关系,显著提升了数据访问层的开发效率。本文从核心映射机制、高级特性、性能优化及面试高频问题四个维度,结合源码与工程实践,系统解析Hibernate的ORM映射原理与最佳实践。一、核心映射机制1.1基础映射类型映射类型描述示例注解实体映射将Java类映射到数据库表@Entity,@Tab
- 提示工程入门指南:如何有效地与大语言模型交互
止观止
大语言模型语言模型人工智能
本文深入拆解提示工程的核心概念、最佳实践和实用技巧。作为AI领域的热点技术,提示工程(PromptEngineering)能显著提升大语言模型(LargeLanguageModel,LLM)如DeepSeek的响应质量。文档结构概览引言:为什么需要提示工程?提示的定义与结构:上下文、指令、约束的完整解析提示工程原则:6项核心技巧有效vs无效提示对比:案例驱动的实操分析用户提示与系统提示:行为控制的
- Python装饰器深度解析:提升代码可读性与复用性
天天进步2015
pythonpython开发语言
Python装饰器(Decorator)是提升代码可读性与复用性的强大工具。无论是日志记录、权限校验、性能分析还是缓存机制,装饰器都能让你的代码更加优雅、简洁和高效。本文将深入解析Python装饰器的原理、常见用法、进阶技巧与最佳实践,助你写出更具专业水准的Python代码。目录装饰器的基本原理函数装饰器的常见用法带参数的装饰器类装饰器与方法装饰器装饰器的嵌套与组合进阶技巧:保留元信息与类型提示装
- CSS 与 JavaScript 加载优化
甘露寺
cssjavascript前端
CSS与JavaScript加载优化指南:位置、阻塞与性能让你的网页飞起来!本文详细解析CSS和JavaScript标签的放置位置如何影响页面性能,涵盖阻塞原理、浏览器机制和最佳实践。掌握这些知识可显著提升用户体验和SEO排名!一、核心问题:为什么位置很重要?浏览器渲染页面时需经历:解析HTML→2.下载资源→3.执行脚本→4.渲染页面错误的位置会阻塞关键路径,导致:⚠️长时间白屏(脚本阻塞)样式
- 嵌入式环境下的C++最佳实践
is0815
c++开发语言
目标:学习嵌入式环境下的C++最佳实践内存管理优化:避免动态分配为什么避免动态分配?堆内存分配(如malloc,new)开销大,速度慢。堆内存容易导致碎片化,增加内存压力。动态分配增加内存泄漏、使用后未释放等风险。实时、高性能系统(嵌入式、游戏引擎)尤其需要优化内存管理。栈vs堆的性能对比特性栈(stack)堆(heap)分配/释放速度极快(O(1))较慢(需管理分配表,O(logn)或更慢)生命
- 简说 MISRA-C++
is0815
c++
MISRA-C++是嵌入式系统中广泛采用的C++编码规范,旨在提高代码安全性、可靠性和可维护性。以下是MISRA-C++的详细要求,涵盖核心规则分类、禁用特性及最佳实践:一、核心规则分类1.语言使用限制禁用动态内存分配(new/delete、std::malloc)风险:内存碎片、分配失败导致运行时崩溃替代:静态数组、对象池或定制内存分配器禁用异常处理(try/catch/throw)风险:异常展
- 后端技术:利用 MySQL 实现数据加密
大厂资深架构师
SpringBoot开发实战mysql数据库ai
后端技术:利用MySQL实现数据加密关键词:MySQL数据加密、AES加密、数据库安全、数据保护、加密算法、密钥管理、SQL注入防御摘要:本文深入探讨如何在MySQL数据库中实现数据加密,保护敏感信息免受未授权访问。我们将从加密的基本原理出发,详细讲解MySQL支持的多种加密方式,包括AES、SHA等算法的实现方法。文章包含完整的代码示例和最佳实践,帮助开发者在实际项目中应用数据加密技术,同时讨论
- 【Flutter】时间轴高度自适应最佳实践
Tech Ranger
FlutterAndroidflutter
1使用部件画圆圈:使用canvas.drawCircle和属性为_paint.style=PaintingStyle.fill;画笔画两个实心圆;画竖线:使用canvas.drawLine和属性为_paint.style=PaintingStyle.stroke;的画笔画直线,通过p1和p2两个端点使直线为竖线在Container中调用decoration组件使用BorderTimeLine类。d
- Flutter 网络栈入门,Dio 与 Retrofit 全面指南
依旧风轻
FlutterflutterretrofitDioSQIiOS
面向多年iOS开发者的零阻力上手写在前面你在iOS项目中也许习惯了URLSession、Alamofire或Moya。换到Flutter后,等价的「组合拳」就是Dio+Retrofit。本文将带你一次吃透两套库的安装、核心API、进阶技巧与最佳实践。1.Dio:Flutter里的「Alamofire」特性作用iOS类比BaseOptions全局配置(超时、基址等)URLSessionConfigu
- Flutter ListTile 徽章宽度自适应的真正原因与最佳实践
依旧风轻
FlutterSQIiOSfluttermainAxisSizeListTileRow
在IM、社交等App的会话列表中,未读消息数常常以绿色圆形或胶囊形徽章的形式展示在每一项的右侧。实现这个效果时,很多开发者会遇到一个令人困惑的问题:无论徽章内的数字是“99”还是“99+”,徽章的宽度都没有变化,甚至调整padding也无效。本文将深入剖析这个问题的根本原因,并给出最优雅、最健壮的Flutter解决方案。1.问题的真正原因在Flutter中,很多人会用ListTile组件来实现会话
- GORM深度解析:模型定义与数据库迁移最佳实践
Golang编程笔记
数据库oracleai
GORM深度解析:模型定义与数据库迁移最佳实践关键词:GORM、模型定义、数据库迁移、最佳实践、Go语言摘要:本文深入探讨了GORM这一强大的Go语言ORM库,详细介绍了模型定义的方法和技巧,以及数据库迁移的最佳实践。通过通俗易懂的语言和丰富的实例,帮助读者理解GORM的核心概念,掌握如何利用GORM高效地进行数据库操作。背景介绍目的和范围在Go语言开发中,与数据库进行交互是一项常见的任务。GOR
- 深入理解 Flutter GetX 框架中的视图组件:GetView、GetWidget、GetxView 与 StatefulWidget
目录深入理解FlutterGetX框架中的视图组件:GetView、GetWidget、GetxView与StatefulWidget一、GetX框架简介二、基础对比三、详细实现与使用场景1.GetView/GetWidget:无状态展示组件2.GetxView:响应式数据视图3.StatefulWidget:管理本地状态四、混合使用示例五、最佳实践建议六、总结在Flutter开发中,合理组织视图
- AI原生应用性能优化:混合推理的7个最佳实践
AI天才研究院
计算AI大模型企业级应用开发实战AI人工智能与大数据AI-native性能优化ai
AI原生应用性能优化:混合推理的7个最佳实践关键词:AI原生应用、性能优化、混合推理、最佳实践、推理效率摘要:本文主要探讨了AI原生应用性能优化中混合推理的相关内容。首先介绍了文章的背景、目的、预期读者和文档结构等信息,接着对混合推理的核心概念进行了通俗易懂的解释,并阐述了各核心概念之间的关系,给出了核心概念原理和架构的文本示意图以及Mermaid流程图。详细讲解了核心算法原理和具体操作步骤,用数
- C++中对象传参的几种方式
递归书房
c++
在C++中传递对象作为函数参数有多种方式,每种方式都有不同的语义、性能特点和适用场景。以下是全面的分析和最佳实践指南:1.按值传递(PassbyValue)voidprocessObject(MyClassobj){//操作obj的副本}MyClassoriginal;processObject(original);//复制构造新对象特点:创建对象的完整副本函数内修改不影响原始对象调用时发生复制构
- Nuitka 打包Python程序
Humbunklung
学海泛舟python开发语言nuitka
文章目录Nuitka打包Python程序**一、Nuitka核心优势**⚙️**二、环境准备(Windows示例)****三、基础打包命令****单文件脚本打包****带第三方库的项目**️**四、高级配置选项****示例:完整命令**⚠️**五、常见问题与解决****六、Nuitkavs其他工具****七、最佳实践建议****八、使用举例**总结Nuitka打包Python程序需要把Python
- MySQL事务深度解析:原理、优化及最佳实践
木木丰
mysqlmysql数据库javawindows
MySQL中的事务(Transaction)是数据库操作的基本单位,它代表着一组逻辑上相互关联的操作,要么全部成功,要么全部失败。这种“要么全做,要么全不做”的特性确保了数据库的完整性和一致性。事务在MySQL中扮演着至关重要的角色,特别是在处理复杂业务逻辑和并发访问时。下面将详细探讨MySQL事务的概念、使用方法、注意事项以及在实际应用中的最佳实践。一、事务的概念事务是一个不可分割的工作逻辑单元
- Go插件性能优化:如何减少内存占用和提升加载速度
Golang编程笔记
golang性能优化网络ai
Go插件性能优化:如何减少内存占用和提升加载速度关键词:Go插件、性能优化、内存占用、加载速度、编译优化、动态链接、插件架构摘要:本文将深入探讨Go语言插件的性能优化策略,从内存管理和加载速度两个核心维度出发,详细分析插件系统的运行机制,并提供一系列实用的优化技巧和最佳实践。通过本文,您将学会如何诊断插件性能瓶颈,应用有效的优化手段,并构建高效可靠的Go插件系统。背景介绍目的和范围本文旨在为Go开
- Golang Fiber框架最佳实践:如何构建企业级应用
Golang编程笔记
Golang编程笔记Golang开发实战golang开发语言后端ai
GolangFiber框架最佳实践:如何构建企业级应用关键词:Golang、Fiber框架、企业级应用、最佳实践、Web开发摘要:本文聚焦于GolangFiber框架在企业级应用构建中的最佳实践。详细介绍了Fiber框架的背景、核心概念、算法原理、数学模型等基础知识,通过具体的代码案例展示了如何搭建开发环境、实现和解读源代码。同时探讨了Fiber框架在实际应用场景中的应用,推荐了相关的学习资源、开
- HarmonyOS从入门到精通:WebView开发
逻极
harmonyos华为鸿蒙webviewUI前端实战
引言WebView是现代移动应用中不可或缺的组件,它使应用能够显示Web内容,实现混合开发。本文将详细介绍鸿蒙系统中WebView的开发技术,包括基本使用、性能优化和最佳实践。WebView基础知识1.WebView类型鸿蒙系统支持多种WebView实现:系统WebView自定义WebViewWeb组件2.WebView权限配置在开发WebView应用前,需要在配置文件中添加相关权限:{"modu
- SnowConvert:自动化数据迁移的技术解析与最佳实践
weixin_30777913
迁移学习数据库运维
SnowConvert是Snowflake生态系统的关键迁移工具,专为将传统数据仓库(如Oracle、Teradata、SQLServer等)的代码资产高效、准确地转换为Snowflake原生语法而设计。以下基于官方文档对其技术原理、工作流程及最佳实践进行深入分析:一、SnowConvert核心技术解析精准的语法映射引擎语言支持:深度解析源系统特有语法(OraclePL/SQL,TeradataB
- Spring Cloud 微服务架构部署模式
Java技术栈实战
架构springcloud微服务ai
SpringCloud微服务架构部署模式:从单体到云原生的进化路径关键词:SpringCloud、微服务架构、部署模式、容器化、Kubernetes、服务网格、DevOps摘要:本文系统解析SpringCloud微服务架构的核心部署模式,涵盖传统物理机部署、容器化部署、Kubernetes集群编排、服务网格集成等技术栈。通过技术原理剖析、实战案例演示和最佳实践总结,揭示不同部署模式的适用场景、技术
- 高可用与低成本兼得:全面解析 TDengine 时序数据库双活与双副本
TDengine (老段)
TDengine案例分析时序数据库tdengine大数据涛思数据数据库物联网iot
在现代数据管理中,企业对于可靠性、可用性和成本的平衡有着多样化的需求。为此,TDengine在3.3.0.0版本中推出了两种不同的企业级解决方案:双活方案和基于仲裁者的双副本方案,以满足不同应用场景下的特殊需求。本文将详细探讨这两种方案的适用场景、技术特点及其最佳实践,让大家深入了解这两大方案如何帮助企业在高效可靠的数据存储和管理中取得成功。TDengine双副本(+仲裁者)为了满足部分客户在保证
- 9 个 GraphQL 安全最佳实践
先行者-阿佰
graphql安全后端
GraphQL已被最大的平台采用-Facebook、Twitter、Github、Pinterest、Walmart-这些大公司不能在安全性上妥协。但是,尽管GraphQL可以成为您的API的非常安全的选项,但它并不是开箱即用的。事实恰恰相反:即使是最新手的黑客,所有大门都是敞开的。此外,GraphQL有自己的一套注意事项,因此如果您来自REST,您可能会错过一些重要步骤!2024年,有关Hack
- C# 中 EventWaitHandle 实现多进程状态同步的深度解析
Leon@Lee
c#开发语言
在现代软件开发中,多进程应用场景日益普遍。无论是分布式系统、微服务架构,还是传统的客户端-服务器模型,进程间的状态同步都是一个关键挑战。C#提供了多种同步原语,其中EventWaitHandle是一个强大的工具,特别适合处理跨进程的同步需求。本文将深入探讨EventWaitHandle的工作原理、使用场景及最佳实践。一、EventWaitHandle基础原理EventWaitHandle是.NET
- Golang cron 定时任务完全指南:从入门到精通
Golang编程笔记
Golang编程笔记Golang开发实战golangwpf开发语言ai
Golangcron定时任务完全指南:从入门到精通关键词:Golang、cron、定时任务、任务调度、并发处理、分布式任务、最佳实践摘要:本文将全面介绍Golang中实现cron定时任务的各个方面,从基础概念到高级应用,涵盖标准库使用、第三方库对比、并发处理、分布式任务调度等核心内容。我们将通过详细的代码示例、架构图解和实际应用场景分析,帮助开发者掌握在Golang中构建可靠、高效的定时任务系统的
- XSL-FO 块:深入解析与最佳实践
沐知全栈开发
开发语言
XSL-FO块:深入解析与最佳实践概述XSL-FO(XSLFormattingObjects)是一种用于生成格式化文档的语言,它允许开发者将XML数据转换成PDF、HTML、PostScript等格式。在XSL-FO中,块(Block)是一个重要的概念,它定义了文档中的矩形区域,包括文本、图像、表格等。本文将深入解析XSL-FO块的相关知识,并分享一些最佳实践。XSL-FO块的定义与属性定义XSL
- 16.2 Docker多阶段构建实战:LanguageMentor镜像瘦身40%,支持500+并发1.2秒响应!
少林码僧
dockerlangchainwindows人工智能语言模型llama运维
LanguageMentorAgent容器化部署与发布:Docker镜像创建与测试关键词:Docker容器化部署,多阶段构建,镜像分层优化,环境一致性,私有化模型集成1.Dockerfile最佳实践架构设计通过多阶段构建策略实现开发与生产环境分离:
- DeepSeek-V3混合精度推理(FP8/BF16)原理与实战全解析
CarlowZJ
DEEPSEEK-V3
目录摘要混合精度推理的背景与意义DeepSeek-V3混合精度架构设计FP8与BF16核心原理详解混合精度推理核心实现实践案例:FP8权重转BF16与推理部署常见问题与注意事项最佳实践与扩展建议总结参考资料附录:可视化图表1.摘要本文系统梳理DeepSeek-V3在FP8/BF16混合精度推理方面的架构设计与工程实现,结合源码与实际案例,帮助开发者深入理解其混合精度推理原理、工程落地方法与性能优化
- Java项目RestfulAPI设计最佳实践
java1234_小锋
javajava开发语言
大家好,我是锋哥。今天分享关于【Java项目RestfulAPI设计最佳实践】面试题。希望对大家有帮助;Java项目RestfulAPI设计最佳实践超硬核AI学习资料,现在永久免费了!设计一个高效、易维护的Java项目中的RESTfulAPI涉及到一系列的最佳实践。以下是一些常见的Java项目RESTfulAPI设计最佳实践:1.使用HTTP方法GET:用于获取资源(不应有副作用,应该是安全的和幂
- MCP-安全(代码实例)
goodfornothing-s
MCP安全
安全最佳实践安全性对于MCP实施至关重要,尤其是在企业环境中。务必确保工具和数据免受未经授权的访问、数据泄露和其他安全威胁。介绍在本课中,我们将探讨MCP实施的安全最佳实践。我们将涵盖身份验证和授权、数据保护、安全工具执行以及数据隐私法规合规性。学习目标学完本课后,您将能够:为MCP服务器实施安全的身份验证和授权机制。使用加密和安全存储保护敏感数据。通过适当的访问控制确保工具的安全执行。应用数据保
- java解析APK
3213213333332132
javaapklinux解析APK
解析apk有两种方法
1、结合安卓提供apktool工具,用java执行cmd解析命令获取apk信息
2、利用相关jar包里的集成方法解析apk
这里只给出第二种方法,因为第一种方法在linux服务器下会出现不在控制范围之内的结果。
public class ApkUtil
{
/**
* 日志对象
*/
private static Logger
- nginx自定义ip访问N种方法
ronin47
nginx 禁止ip访问
因业务需要,禁止一部分内网访问接口, 由于前端架了F5,直接用deny或allow是不行的,这是因为直接获取的前端F5的地址。
所以开始思考有哪些主案可以实现这样的需求,目前可实施的是三种:
一:把ip段放在redis里,写一段lua
二:利用geo传递变量,写一段
- mysql timestamp类型字段的CURRENT_TIMESTAMP与ON UPDATE CURRENT_TIMESTAMP属性
dcj3sjt126com
mysql
timestamp有两个属性,分别是CURRENT_TIMESTAMP 和ON UPDATE CURRENT_TIMESTAMP两种,使用情况分别如下:
1.
CURRENT_TIMESTAMP
当要向数据库执行insert操作时,如果有个timestamp字段属性设为
CURRENT_TIMESTAMP,则无论这
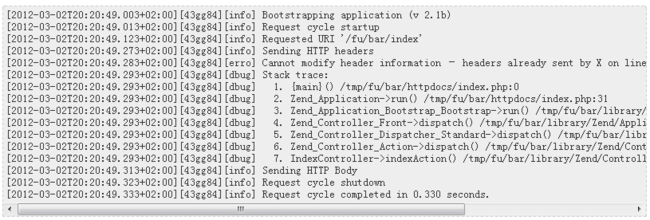
- struts2+spring+hibernate分页显示
171815164
Hibernate
分页显示一直是web开发中一大烦琐的难题,传统的网页设计只在一个JSP或者ASP页面中书写所有关于数据库操作的代码,那样做分页可能简单一点,但当把网站分层开发后,分页就比较困难了,下面是我做Spring+Hibernate+Struts2项目时设计的分页代码,与大家分享交流。
1、DAO层接口的设计,在MemberDao接口中定义了如下两个方法:
public in
- 构建自己的Wrapper应用
g21121
rap
我们已经了解Wrapper的目录结构,下面可是正式利用Wrapper来包装我们自己的应用,这里假设Wrapper的安装目录为:/usr/local/wrapper。
首先,创建项目应用
&nb
- [简单]工作记录_多线程相关
53873039oycg
多线程
最近遇到多线程的问题,原来使用异步请求多个接口(n*3次请求) 方案一 使用多线程一次返回数据,最开始是使用5个线程,一个线程顺序请求3个接口,超时终止返回 缺点 测试发现必须3个接
- 调试jdk中的源码,查看jdk局部变量
程序员是怎么炼成的
jdk 源码
转自:http://www.douban.com/note/211369821/
学习jdk源码时使用--
学习java最好的办法就是看jdk源代码,面对浩瀚的jdk(光源码就有40M多,比一个大型网站的源码都多)从何入手呢,要是能单步调试跟进到jdk源码里并且能查看其中的局部变量最好了。
可惜的是sun提供的jdk并不能查看运行中的局部变量
- Oracle RAC Failover 详解
aijuans
oracle
Oracle RAC 同时具备HA(High Availiablity) 和LB(LoadBalance). 而其高可用性的基础就是Failover(故障转移). 它指集群中任何一个节点的故障都不会影响用户的使用,连接到故障节点的用户会被自动转移到健康节点,从用户感受而言, 是感觉不到这种切换。
Oracle 10g RAC 的Failover 可以分为3种:
1. Client-Si
- form表单提交数据编码方式及tomcat的接受编码方式
antonyup_2006
JavaScripttomcat浏览器互联网servlet
原帖地址:http://www.iteye.com/topic/266705
form有2中方法把数据提交给服务器,get和post,分别说下吧。
(一)get提交
1.首先说下客户端(浏览器)的form表单用get方法是如何将数据编码后提交给服务器端的吧。
对于get方法来说,都是把数据串联在请求的url后面作为参数,如:http://localhost:
- JS初学者必知的基础
百合不是茶
js函数js入门基础
JavaScript是网页的交互语言,实现网页的各种效果,
JavaScript 是世界上最流行的脚本语言。
JavaScript 是属于 web 的语言,它适用于 PC、笔记本电脑、平板电脑和移动电话。
JavaScript 被设计为向 HTML 页面增加交互性。
许多 HTML 开发者都不是程序员,但是 JavaScript 却拥有非常简单的语法。几乎每个人都有能力将小的
- iBatis的分页分析与详解
bijian1013
javaibatis
分页是操作数据库型系统常遇到的问题。分页实现方法很多,但效率的差异就很大了。iBatis是通过什么方式来实现这个分页的了。查看它的实现部分,发现返回的PaginatedList实际上是个接口,实现这个接口的是PaginatedDataList类的对象,查看PaginatedDataList类发现,每次翻页的时候最
- 精通Oracle10编程SQL(15)使用对象类型
bijian1013
oracle数据库plsql
/*
*使用对象类型
*/
--建立和使用简单对象类型
--对象类型包括对象类型规范和对象类型体两部分。
--建立和使用不包含任何方法的对象类型
CREATE OR REPLACE TYPE person_typ1 as OBJECT(
name varchar2(10),gender varchar2(4),birthdate date
);
drop type p
- 【Linux命令二】文本处理命令awk
bit1129
linux命令
awk是Linux用来进行文本处理的命令,在日常工作中,广泛应用于日志分析。awk是一门解释型编程语言,包含变量,数组,循环控制结构,条件控制结构等。它的语法采用类C语言的语法。
awk命令用来做什么?
1.awk适用于具有一定结构的文本行,对其中的列进行提取信息
2.awk可以把当前正在处理的文本行提交给Linux的其它命令处理,然后把直接结构返回给awk
3.awk实际工
- JAVA(ssh2框架)+Flex实现权限控制方案分析
白糖_
java
目前项目使用的是Struts2+Hibernate+Spring的架构模式,目前已经有一套针对SSH2的权限系统,运行良好。但是项目有了新需求:在目前系统的基础上使用Flex逐步取代JSP,在取代JSP过程中可能存在Flex与JSP并存的情况,所以权限系统需要进行修改。
【SSH2权限系统的实现机制】
权限控制分为页面和后台两块:不同类型用户的帐号分配的访问权限是不同的,用户使
- angular.forEach
boyitech
AngularJSAngularJS APIangular.forEach
angular.forEach 描述: 循环对obj对象的每个元素调用iterator, obj对象可以是一个Object或一个Array. Iterator函数调用方法: iterator(value, key, obj), 其中obj是被迭代对象,key是obj的property key或者是数组的index,value就是相应的值啦. (此函数不能够迭代继承的属性.)
- java-谷歌面试题-给定一个排序数组,如何构造一个二叉排序树
bylijinnan
二叉排序树
import java.util.LinkedList;
public class CreateBSTfromSortedArray {
/**
* 题目:给定一个排序数组,如何构造一个二叉排序树
* 递归
*/
public static void main(String[] args) {
int[] data = { 1, 2, 3, 4,
- action执行2次
Chen.H
JavaScriptjspXHTMLcssWebwork
xwork 写道 <action name="userTypeAction"
class="com.ekangcount.website.system.view.action.UserTypeAction">
<result name="ssss" type="dispatcher">
- [时空与能量]逆转时空需要消耗大量能源
comsci
能源
无论如何,人类始终都想摆脱时间和空间的限制....但是受到质量与能量关系的限制,我们人类在目前和今后很长一段时间内,都无法获得大量廉价的能源来进行时空跨越.....
在进行时空穿梭的实验中,消耗超大规模的能源是必然
- oracle的正则表达式(regular expression)详细介绍
daizj
oracle正则表达式
正则表达式是很多编程语言中都有的。可惜oracle8i、oracle9i中一直迟迟不肯加入,好在oracle10g中终于增加了期盼已久的正则表达式功能。你可以在oracle10g中使用正则表达式肆意地匹配你想匹配的任何字符串了。
正则表达式中常用到的元数据(metacharacter)如下:
^ 匹配字符串的开头位置。
$ 匹配支付传的结尾位置。
*
- 报表工具与报表性能的关系
datamachine
报表工具birt报表性能润乾报表
在选择报表工具时,性能一直是用户关心的指标,但是,报表工具的性能和整个报表系统的性能有多大关系呢?
要回答这个问题,首先要分析一下报表的处理过程包含哪些环节,哪些环节容易出现性能瓶颈,如何优化这些环节。
一、报表处理的一般过程分析
1、用户选择报表输入参数后,报表引擎会根据报表模板和输入参数来解析报表,并将数据计算和读取请求以SQL的方式发送给数据库。
2、
- 初一上学期难记忆单词背诵第一课
dcj3sjt126com
wordenglish
what 什么
your 你
name 名字
my 我的
am 是
one 一
two 二
three 三
four 四
five 五
class 班级,课
six 六
seven 七
eight 八
nince 九
ten 十
zero 零
how 怎样
old 老的
eleven 十一
twelve 十二
thirteen
- 我学过和准备学的各种技术
dcj3sjt126com
技术
语言VB https://msdn.microsoft.com/zh-cn/library/2x7h1hfk.aspxJava http://docs.oracle.com/javase/8/C# https://msdn.microsoft.com/library/vstudioPHP http://php.net/manual/en/Html
- struts2中token防止重复提交表单
蕃薯耀
重复提交表单struts2中token
struts2中token防止重复提交表单
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年7月12日 11:52:32 星期日
ht
- 线性查找二维数组
hao3100590
二维数组
1.算法描述
有序(行有序,列有序,且每行从左至右递增,列从上至下递增)二维数组查找,要求复杂度O(n)
2.使用到的相关知识:
结构体定义和使用,二维数组传递(http://blog.csdn.net/yzhhmhm/article/details/2045816)
3.使用数组名传递
这个的不便之处很明显,一旦确定就是不能设置列值
//使
- spring security 3中推荐使用BCrypt算法加密密码
jackyrong
Spring Security
spring security 3中推荐使用BCrypt算法加密密码了,以前使用的是md5,
Md5PasswordEncoder 和 ShaPasswordEncoder,现在不推荐了,推荐用bcrpt
Bcrpt中的salt可以是随机的,比如:
int i = 0;
while (i < 10) {
String password = "1234
- 学习编程并不难,做到以下几点即可!
lampcy
javahtml编程语言
不论你是想自己设计游戏,还是开发iPhone或安卓手机上的应用,还是仅仅为了娱乐,学习编程语言都是一条必经之路。编程语言种类繁多,用途各 异,然而一旦掌握其中之一,其他的也就迎刃而解。作为初学者,你可能要先从Java或HTML开始学,一旦掌握了一门编程语言,你就发挥无穷的想象,开发 各种神奇的软件啦。
1、确定目标
学习编程语言既充满乐趣,又充满挑战。有些花费多年时间学习一门编程语言的大学生到
- 架构师之mysql----------------用group+inner join,left join ,right join 查重复数据(替代in)
nannan408
right join
1.前言。
如题。
2.代码
(1)单表查重复数据,根据a分组
SELECT m.a,m.b, INNER JOIN (select a,b,COUNT(*) AS rank FROM test.`A` A GROUP BY a HAVING rank>1 )k ON m.a=k.a
(2)多表查询 ,
使用改为le
- jQuery选择器小结 VS 节点查找(附css的一些东西)
Everyday都不同
jquerycssname选择器追加元素查找节点
最近做前端页面,频繁用到一些jQuery的选择器,所以特意来总结一下:
测试页面:
<html>
<head>
<script src="jquery-1.7.2.min.js"></script>
<script>
/*$(function() {
$(documen
- 关于EXT
tntxia
ext
ExtJS是一个很不错的Ajax框架,可以用来开发带有华丽外观的富客户端应用,使得我们的b/s应用更加具有活力及生命力。ExtJS是一个用 javascript编写,与后台技术无关的前端ajax框架。因此,可以把ExtJS用在.Net、Java、Php等各种开发语言开发的应用中。
ExtJs最开始基于YUI技术,由开发人员Jack
- 一个MIT计算机博士对数学的思考
xjnine
Math
在过去的一年中,我一直在数学的海洋中游荡,research进展不多,对于数学世界的阅历算是有了一些长进。为什么要深入数学的世界?作为计算机的学生,我没有任何企图要成为一个数学家。我学习数学的目的,是要想爬上巨人的肩膀,希望站在更高的高度,能把我自己研究的东西看得更深广一些。说起来,我在刚来这个学校的时候,并没有预料到我将会有一个深入数学的旅程。我的导师最初希望我去做的题目,是对appe