Mybatis分页插件2.0版本发布
项目地址:http://git.oschina.net/free/Mybatis_PageHelper
软件介绍:http://www.oschina.net/p/mybatis_pagehelper
分页插件示例: http://my.oschina.net/flags/blog/228700
v2.0更新内容:
- 支持Mybatis缓存,count和分页同时支持(二者同步)
- 修改拦截器签名,拦截Executor,签名如下:
@Intercepts(@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}))
- 将Page类移到外面,方便调用
有位朋友留言说插件不支持缓存,在使用缓存的情况下无法正常运行。
这个问题确实存在,因为缓存是CachingExecutor在v1.0版本中的拦截器之前进行的,也就是说,当查询结果被缓存后,使用缓存的时候是进不到分页插件中的,而且分页插件无法取得返回的结果,因而不能正常运行,既然找到了原因,而且Executor也可以被拦截,我就在想能否直接拦截Executor并且支持缓存。
通过查看源码以及调试,找到一种可行的方法,并且经过多项测试到最后完成,共计4小时,我测试的内容有缓存/不缓存两种情况,以及返回为resultType/resultMap两种情况,共计4种情况下的使用情况。测试仍然不算全面,所以我希望使用该插件的各位朋友遇到问题能及时反馈。
这次更新和前一个版本的实现方法毫无关联,而且也从来没人这么做过,所以有问题请及时反馈,下面说说具体的实现方法。
首先拦截器签名变了:
@Intercepts(@Signature(type = Executor.class,
method = "query",
args = {MappedStatement.class,
Object.class,
RowBounds.class,
ResultHandler.class}))
查看完整代码请点击这里,下面讲一些实现的细节:
List<SqlNode> contents = (List<SqlNode>) msObject.getValue("sqlSource.rootSqlNode.contents");
这段代码获取了SqlNode集合,Mybatis要执行的Sql从通过这个集合拼出来了,在第一个版本的中的BoundSql就是通过contents中的内容生成的, 所以这种分页方式绝对是意想不到的,获取这个对象后,做了如下处理:
//求count - 重写sql
contents.add(0, new TextSqlNode("select count(0) from ("));
contents.add(new TextSqlNode(")"));
往第一行插入了求count的sql,最后一行加了一个“)”,通过头尾添加的这两个,就让这一个正常的sql语句变成了一个求count的sql,下面这一句代码:
Class<?> resultType = (Class<?>) msObject.getValue("resultMaps[0].type");
这一句代码的作用是先把正常的返回值类型保存,然后做了如下修改:
msObject.setValue("resultMaps[0].type", int.class);
将返回值改为int类型,用于接收返回的count总数,还有一句很重要的代码:
List<ResultMapping> resultMappings = (List<ResultMapping>) msObject.getValue("resultMaps[0].resultMappings");
这里也是先把resultMappings备份,这个值在使用resultMap的情况会对返回结果造成干扰,所以这里先备份,然后用一个空的list去代替:
msObject.setValue("resultMaps[0].resultMappings", EMPTY_RESULTMAPPING);
然后就去执行这个修改后的sql:
//查询总数
Object result = null;
try {
result = invocation.proceed();
int totalCount = Integer.parseInt(((List) result).get(0).toString());
page.setTotal(totalCount);
int totalPage = totalCount / page.getPageSize() + ((totalCount % page.getPageSize() == 0) ? 0 : 1);
page.setPages(totalPage);
} finally {
//清理count sql
contents.remove(0);
contents.remove(contents.size() - 1);
//恢复类型
msObject.setValue("resultMaps[0].type", resultType);
msObject.setValue("resultMaps[0].resultMappings", resultMappings);
}
因为这里执行了result = invocation.proceed()方法,所以在开启缓存的情况下,该sql也会被缓存,这里将结果totalCount保存到Page,然后在finally中执行了清理sql的方法和恢复类型的方法,这样就又变成了原来的sql。
这里通过执行过程中的截图来看一下实际效果:
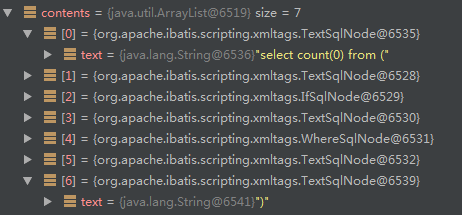
增加头尾的count语句

执行的sql
后面使用相同的原理修改为分页SQL:
//分页sql
contents.add(0, new TextSqlNode("select * from ( select temp.*, rownum row_id from ( "));
StringBuilder pageSql = new StringBuilder(200);
pageSql.append(" ) temp where rownum <= ").append(page.getEndRow());
pageSql.append(") where row_id > ").append(page.getStartRow());
contents.add(new TextSqlNode(pageSql.toString()));
执行过程图:
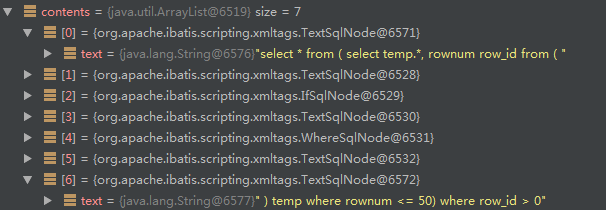
增加头尾的分页sql

执行的sql
最后执行修改后的sql,保存处理结果:
//将执行权交给下一个拦截器
try {
result = invocation.proceed();
} finally {
//清理分页sql
contents.remove(0);
contents.remove(contents.size() - 1);
}
//得到处理结果
page.setResult((List) result);
//返回结果
return result;
这里仍然不能忘记在finally中清理sql。
通过这种方法,完全使用了Mybatis的内容来操作,而且可以支持缓存,缓存对求count语句来说效果更明显,因为你查看下一页内容的时候不会重复执行count,会使用缓存。而且分页sql和count sql是同步缓存的,所以不用担心数据不一致的情况。而且这种分页方式不影响原方法的单独执行(不分页)。
如果对你有帮助,或者有什么建议欢迎留言!
转载请注明原文地址和作者!