从头开始建立一个关注者模型
Pinterest 工程师一定很牛逼,而且很骚包,不信你把鼠标放他照片上看看。
Building a follower model from scratch
我们的关注者图里面有数以百万计的节点和数以亿计的边,这让我的M属性发挥到了极致,充满了欲望来挑战维护和扩展数据,因此我们建立了兴趣图。这和 Twitter 或者 Facebook 很像,不过我们基于兴趣的账号在产品研发和设计阶段,和他们有些关键的不同。
最终版 Pinterest 关注者服务用了,一个全职工程师,2-3个兼职工程师的8周左右时间开发完成,迁移和发布。
现在我们讲解一下我们是如何设计面向服务的架构,以便帮助我们开发和维护该服务。
Pinterest 关注者模型和兴趣图
Facebook 的主要关注关系是两个用户之间相互的,而 Twitter 则是典型的一对多关系。在 Pinterest 上,关注可以是单方的,出于他们独立的或者扩展兴趣。当用户关注越来越多的人或事的时候,他们的主面板会变得越来越符合他们的兴趣,然后,我们将会依次创建兴趣图。
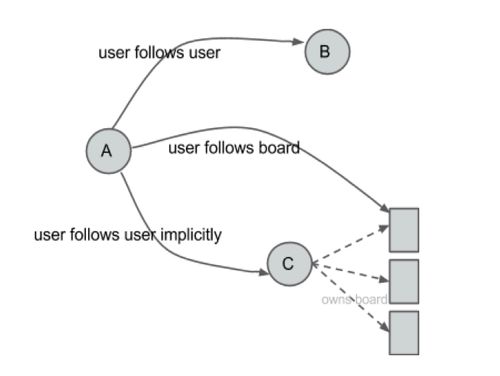
比如说,如果安德烈关注了鲍勃,她会关注他所有的兴趣点,并且如果他创建一个新的兴趣点,她会自动的关注该兴趣点。如果安德烈关注的是鲍勃的吃货兴趣,那她将会在她的主面板上看到他所有加星的项目。安德烈同样会被列在吃货关注者列表里面。我们称这是隐式关注者(而之前的用户对用户的关注者是显式关注者)。
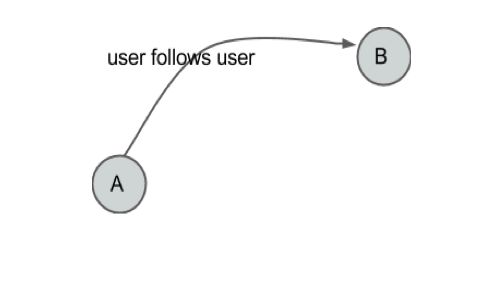
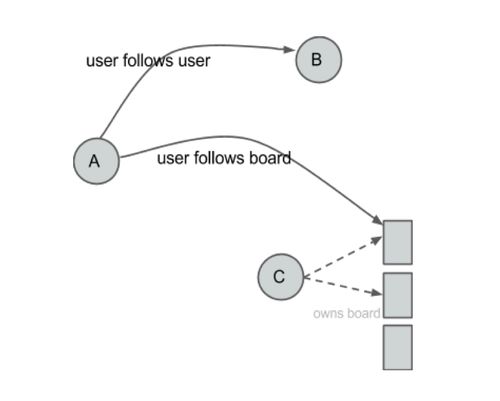
Action: 关注用户
Action: 关注兴趣
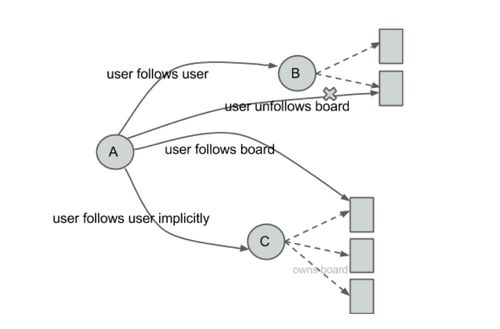
Action: 取消关注兴趣
隐式关系 (反转方向)
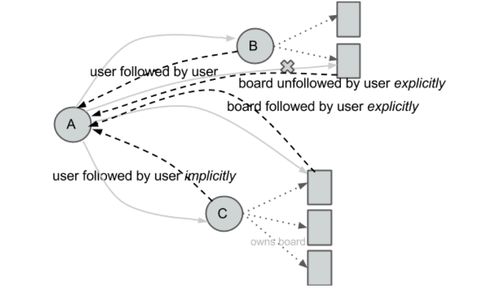
关注模型看起来很复杂的样子,但是对于用户来说非常简单。
低延迟的通用查询,比如"是否用户 A 关注了用户 B?“,以及可接受的延迟,比如对数百万的粉丝进行分页。是需要的。UI 显示了准确的数目,以及对用户的粉丝和关注用户列表以及兴趣点关注者列表进行分页。我们需要可接受的延时,因为这跟离线工作的抽出兴趣点关注一样。
几乎所有的页面都要显示关注/被关注的计数,或者检查已登陆用户是否关注了该兴趣点或者用户是否在浏览。这需要关注服务处理站点的吞吐量和规模。理想情况下,服务需要留有一定空间来支持内部实验。就像分布式系统模式那样:可以水平扩展,高可用性,无数据丢失,无单点异常(SPOF)。
最大的挑战
- 我们没有找到任何现成的满足我们需求的开源工程(比如说这种规模的高效图形操作)。
- 保存在 MySQL 和用 memcached 缓存的传统的模型已经到达极限。
- 缓存图数据非常困难,因为只有当用户的整个子图都缓存起来之后,它才是能用的数据。于是,这就变成要求缓存整个关系图!
- 缓存,也就意味着像查询"用户A是不是关注了用户B?“是否也要放在缓存,但是往往答案是"不"的话,这会导致查询持久层的更大的开销。
关注者图的内部运作
Pinterest 的关注者图实际上比较小,因此把整个图加载到内存中是可行的。
Redis 保存关系图,通过用户ID进行分片,用 Redis 的 AOF 功能随时更新硬盘内容,避免数据丢失。因为 Redis 是单线程模型,因此我们执行多个 Redist 实例以充分利用 CPU 。每个 Redis 实例提供一个虚拟分片,这使得当一台机器打到上限的时候,很容易进行再分裂。
深挖数据模型
在我们开始理解我们选择的数据模型之前,让我们总结一下,关注服务所需要的常用操作。我们需要响应诸如"用户 A 是否关注了用户 B"这样的查询。在检索页面支持过滤查询,比如"哪25个用户关注了我?“,或者获取这帮人关注的那帮人,或者给粉丝推送新事件。为了响应这些查询,我们需要为每个用户提供这样一个关系:
- 查询指定用户显式关注(所谓显式的意思是,所有的现在和未来的兴趣点都会被关注)
- 查询指定用户隐式关注,比如一个或多个兴趣点被用户关注
- 查询指定用户的粉丝列表(所有显式粉丝)
- 查询指定用户的兴趣点的粉丝列表(所有隐式粉丝)
- 查询指定用户的兴趣点列表
- 查询指定用户非兴趣点列表(许多用户关注别人但是不关注对方的一部分兴趣点,因为他们不感兴趣)
- 查询兴趣点的粉丝列表
- 查询兴趣点的非粉列表
Redis 数据结构用来实现这些关系(每用户):
- Redist SortedSet,时间戳为权重,用来存储显式关注。我们用 SortedSet 有两个原因:第一,产品需求用户以时间反序排列,第二,我们可以通过 id 列表来分页
- Redis SortedSet,时间戳为权重,用来存储隐式关注
- Redis SortedSet,时间戳为权重,用来存储用户的粉丝列表
- Redis SortedSet,时间戳为权重,用来存储用户的兴趣点粉丝列表
- Redis Set,用来存储兴趣点列表
- Redis Set,用来存储非兴趣点列表
- Redis Hash,用来存储兴趣点的粉丝列表
- Redis Set,用来存储非粉列表
整个用户id控件被分成8129个虚拟分片。我们把每个分片放在一个 Redis DB 上,在每台机器上运行多个 Redis 实例(范围大约是 8 到 32 个),这根据分片在这个实例中,消耗的的内存和 CPU 来定 。同样,我们在每个 Redis 实例上运行多个 Redis DB。
当 Redis 机器到达内存和 CPU 极限的时候,我们再把它水平或者垂直切分。垂直分片,只是简单的把一台机器上运行的 Redis 实例的个数减半。我们弄一个新的 master 作为已经存在的 master 的 slave,我们让新的 master 管一半 Redis 实例,原来老的 master 管另外一半。
我们使用 Zookeeper 来保存分片配置。因为 Redis 是单线程服务,所以能够水平拆分实例,对充分利用所有的机器内核非常重要。
紧急措施:备份和失败
我们以 Redis 的 master-slave 配置运行我们的群集,slave 执行热备份。如果 master 失败,我们失效转移,把 slave 作为新的 master,并且立刻创建一个新的 slave 或者把老的 master 作为新的 slave。我们用 ZooKeeper 很快就实现了这一需求。
每个 master Redis 实例(以及每个 slave 实例)在 Amazon EBS 上被配置到 AOF。这保证了 Redis 实例被异常中断而丢失数据的范围可以限制到 1 秒为单位的更新。 slave Redis 实例被每小时 BGsave,保存到持久层(Amazon S3)。这个拷贝同样也被用到了 MapReduce 上。
作为一个产品系统,我们需要更多的异常模式来保护自己。如上述,如果 master host 挂了,我们需要手工失败转移到 slave。如果一个 master Redis 实例重启了,然后从 AOF 中重载数据,意味着在该实例上的分片丢失了 1 秒的数据。如果 slave host 挂了,我们做一个替换的。如果一个 slave Redis 实例挂了,我们依靠从 AOF 中重载数据。由于我们有可能遇到 AOF 或者 BGsave 文件损坏,我们 BGSave 和拷贝文件备份到 S3.注意,由于大文件可能导致 BGSave 延迟,在我们的系统中,我们依靠缩小数据来缓解。
教训
- 长时间的广度和深度覆盖的单元测试让我们节约了不少时间。同样,这也是对运行这样一个服务的长时间的考验的方法。
- 我们从语言框架出发,使用原生支持异步调用的框架来防止bug
- 我们用 Redis 的 LUA 特性,在一个小众功能上维护写一致性。我们预期会遇到这样一个小 Set,它会导致 CPU
高使用率(strcpy),在一个小功能上,当出现有用户有超乎寻常的多非关注兴趣点的时候。
基于 master-slave 的解决案意味着,当 master 挂掉的时候,一部分分片就不能写了。之后我们可能改进这点,让 master/slave 自动进行异常转移,以降低当 master 不可用时候带来的影响。理想情况下,我们希望关注一下当发生灾难性异常时,我们可以从 S3 的备份中恢复数据。另外一个领域是,改善我们可怜的客户端的链接负载平衡。
最后,当我从现存的 MySQL 中把数据迁移过来之后,我们节约了 30% IOps。
更快的开发,建立基盘,可扩展的开发,是工作里面最爽的一部分。我们希望我们在这里学到的东西可以帮助更多的人。
Abhi Khune 是 Pinterest 的工程师,专职搭建基盘。(而且很骚包)