MDX Step by Step 读书笔记(四) - Working with Sets (使用集合)
1. Set - 元组的集合,在 Set 中的元组用逗号分开,Set 以花括号括起来,例如:
{ ([Product].[Category].[Accessories]), ([Product].[Category].[Bikes]), ([Product].[Category].[Clothing]), ([Product].[Category].[Components]) }
从这个例子中可以看到Set的几个特点:
- 一个Set 中可以包含一个或者多个 Tuple 元组
- 在 Set 中的每一个元组所包含的Member 成员都对应的引用的是同一个层次结构,在这个例子中引用的是 [Product].[Category]
这种也是Set
{ ([Product].[Category].[Accessories],[Date].[Calendar]. [CY 2004]), ([Product].[Category].[Bikes],[Date].[Calendar].[CY 2002]), ([Product].[Category].[Clothing],[Date].[Calendar].[CY 2003]), ([Product].[Category].[Components],[Date].[Calendar].[CY 2001]) }
从这里可以看到 Set:
- 在包含的元组中,元组中的成员可以有一个或者多个,但是元组中的成员顺序和其它元组中成员的顺序应该相同。这里所讲的成员是指在Set中所有元组中第一个成员引用的层次结构都是 [Product].[Category] 并且第二个成员引用的都是 [Date].[Calendar] 属性层次结构。成员引用属性层次结构的顺序不能改变,必须相同。
2. 案例分析 – 查询 Accessories,Bikes,Clothing,Components 四类产品在2002-2004 财年美国的零售额。行轴为四类产品,列轴为 2002-2004 财年+美国
SELECT { ([Date].[Calendar].[CY 2002],[Geography].[Country].[United States]), ([Date].[Calendar].[CY 2003],[Geography].[Country].[United States]), ([Date].[Calendar].[CY 2004],[Geography].[Country].[United States]) } ON COLUMNS, { ([Product].[Category].[Accessories]), ([Product].[Category].[Bikes]), ([Product].[Category].[Clothing]), ([Product].[Category].[Components]) } ON ROWS FROM [Step-by-Step]

第一个 Set 中包含了三个元组,每一个元组都包含两个成员引用,第一个成员引用财年层次结构,第二个成员引用了地理纬度中的国家层次结构。第二个 Set 包含了四个元组,每一个元组都只包含一个成员,但是都引用到了同一个Category 层次结构。
错误的引用:
- 元组中的成员引用了不一致的层次结构
SELECT { ([Date].[Calendar].[CY 2002],[Geography].[Country].[United States]), ([Date].[Calendar].[CY 2003],[Geography].[Country].[United States]), ([Date].[Calendar].[CY 2004],[Geography].[Country].[United States]) } ON COLUMNS, { ([Product].[Category].[Accessories]), ([Product].[Category].[Bikes]), ([Product].[Category].[Clothing]), ([Product].[Category].[Components]), ([Product].[Subcategory].[Mountain Bikes]) } ON ROWS FROM [Step-by-Step]
错误消息: Executing the query...
Members,tuples or sets must use the same hierarchies in the function.
Execution complete
解释 - 第二个Set 中的元组 ([Product].[Subcategory].[Mountain Bikes]) 中的成员所引用的层次结构和其它元组中的成员所引用的层次结构不一致,导致错误。
2. 元组中的成员在引用层次结构时的顺序不一致
SELECT { ([Geography].[Country].[United States],[Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003],[Geography].[Country].[United States]), ([Date].[Calendar].[CY 2004],[Geography].[Country].[United States]) } ON COLUMNS, { ([Product].[Product Categories].[Accessories]), ([Product].[Product Categories].[Bikes]), ([Product].[Product Categories].[Clothing]), ([Product].[Product Categories].[Components]), ([Product].[Product Categories].[Mountain Bikes]) } ON ROWS FROM [Step-by-Step]
错误消息:
Executing the query...
Members,tuples or sets must use the same hierarchies in the function.
Execution complete
解释:第一个 Set 中的第一个元组中的成员引用的层次结构顺序和第二个第三个元组中的成员引用的属性层次结构不一致,顺序不能颠倒,必须保持完全一致。
3. 重复的元组是允许的,这样查询出来的结果就会多一条记录
SELECT { ([Geography].[Country].[United States],[Date].[Calendar].[CY 2004]), ([Geography].[Country].[United States],[Date].[Calendar].[CY 2003]), ([Geography].[Country].[United States],[Date].[Calendar].[CY 2002]) } ON COLUMNS, { ([Product].[Product Categories].[Accessories]), ([Product].[Product Categories].[Accessories]), ([Product].[Product Categories].[Bikes]), ([Product].[Product Categories].[Clothing]), ([Product].[Product Categories].[Components]), ([Product].[Product Categories].[Mountain Bikes]) } ON ROWS FROM [Step-by-Step]

3. Distinct 函数
在一个有着复杂逻辑的MDX 查询中很有可能在一个 Set 中出现重复的元组,可以通过Distinct 函数去掉重复的元组 Distinct({Set})
SELECT { ([Geography].[Country].[United States],[Date].[Calendar].[CY 2004]), ([Geography].[Country].[United States],[Date].[Calendar].[CY 2003]), ([Geography].[Country].[United States],[Date].[Calendar].[CY 2002]) } ON COLUMNS, DISTINCT( { ([Product].[Product Categories].[Accessories]), ([Product].[Product Categories].[Accessories]), ([Product].[Product Categories].[Bikes]), ([Product].[Product Categories].[Clothing]), ([Product].[Product Categories].[Components]), ([Product].[Product Categories].[Mountain Bikes]) } ) ON ROWS FROM [Step-by-Step]
查询结果

4. 理解 SELECT Understanding the SELECT statement
SELECT 语句的目的是定义新的 Cube 空间,新的Cube 空间是由类似于 COLUMNS或者ROWS 这样的轴组成,在这些轴上的点都是由Set里元组中的成员或者成员的组合组成的。
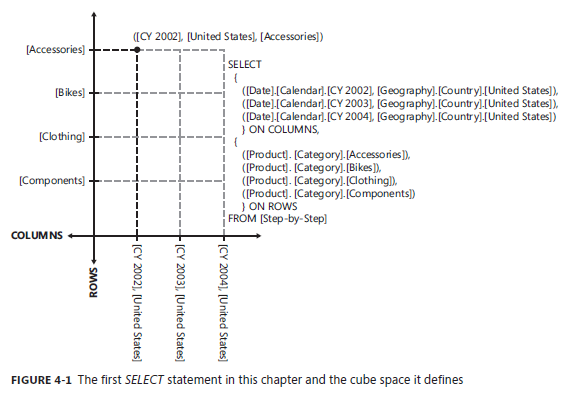
在这个图中,由 Calendar Year 和 Country 两个层次结构中的成员构成了一个元组 Tuple,三个这样的Tuple 构成了一个 SET,用这个 SET 描述了一个 COLUMNS 的轴。 这个轴其实是一个平面,是由Calendar Year 和 Country 两个属性层次结构形成的平面。另外的一个 SET 中,由四个 Category 成员元组形成了另外的一个 ROWS 轴。这两个轴形成了一个两维空间,而这个空间平面上的点都是由这两个轴交叉的点组成的。
之前第三章我们描述这样的交叉都是在元组Tuple 中定义的,例如像本示例提到的 构成COLUMNS 轴上的 [CY2002]和[United States] 再加上 ROWS 轴上的 [Accessories] 实际上就这一个交叉点用元组 Tuple 来表示的话就应该是:
([CY2002],[United States],[Accessories])
那么这个元组实际上还是一个局部元组,按照第三章的理解(请查看第三章我的学习笔记 http://www.cnblogs.com/biwork/archive/2013/04/09/3010199.html)
SSAS还会对这个局部元组还会对其它未能显示列出的轴自动按照一定规则自动补齐,所以上面的示例中哪些交叉点不仅仅是这三个轴的交叉点,而且也应该包含了其它属性层次结构作为轴时的交叉点,比如默认的 Reseller Sales 度量值纬度。
就这个例子,可以忽略这种局部元组的说法,可以认为两个轴 [Date].[Calendar] 和 [Geography].[Country] 合起来构成了一个面,而这个面又作为一个新的轴存在并以 COLUMNS 的形式出现,[Product].[Category] 这一个属性层次结构构成了一个单独的轴以 ROWS 的形式出现。很自然的理解,COLUMNS 出现在查询结果的列的位置,而 ROWS 出现在行的位置,行和列的交集就形成了各个 Tuple ,然后按照第三章的规则获取各个Tuple 最终定位的值。
通过这个例子可以发现:
有三个属性层次结构被显示写出,[Date].[Calendar] 属性层次结构有3个成员,[Geography].[Country] 有1个成员,所以3*1 这两个轴先构成了一个面。然后再加上 [Product].[Category] 轴有4个成员,所以 3*4 就构成了12个点,这12个点构成了一个查询集合。
5. 带有Where 条件的 Slicer Axis (切片轴)

书上通过两个例子来讲解其中的区别:
SELECT { ([Date].[Calendar].[CY 2002],[Geography].[Country].[United States]), ([Date].[Calendar].[CY 2003],[Geography].[Country].[United States]), ([Date].[Calendar].[CY 2004],[Geography].[Country].[United States]) } ON COLUMNS, { ([Product].[Category].[Accessories]), ([Product].[Category].[Bikes]), ([Product].[Category].[Clothing]), ([Product].[Category].[Components]) } ON ROWS FROM [Step-by-Step]

SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, { ([Product].[Category].[Accessories]), ([Product].[Category].[Bikes]), ([Product].[Category].[Clothing]), ([Product].[Category].[Components]) } ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])

从这两个对比能够看出他们之间相同的地方和区别:
相同的地方就是查询结果都是一样的。
不同的地方就是第一个查询中,由于([Geography].[Country].[United States])是第一个 SET 中组成Tuple的一个元素,因此会作为 COLUMNS 的一部分显示在列头。
6. SELECT 语句中的轴
SELECT 语句最多可以支持 128 个轴,轴的序号从 0 ~ 127,但是基本上我们不会使用的到那么多,一般只使用前两个,即我们常用的 COLUMNS 和 SETS。因为大多数客户端工具只能支持到二维即显示行和列。并且是使用这些轴的名称的时候,他们的顺序必须是连续的. 即如果写了 ROWS,那么COLUMNS 也必须存在 ,不能只使用 ROWS 而不使用COLUMNS。
下图中显示了前5个轴的正式名称,短名称和别名。

这样写不会有问题,但是为了方便阅读最好还是使用 COLUMNS 和 ROWS 的形式
SELECT { ([Date].[Calendar].[CY 2002],[Geography].[Country].[United States]) } ON AXIS(0), { ([Product].[Category].[Bikes]) }ON 1 FROM [Step-by-Step];
7. Members 函数的使用
Members 函数使用的频率非常高,又没有任何参数,使用它主要是为了从属性层次结构或者属性层次结构某一层中取出所有的成员。
[Dimension].[Hierarchy].Members
[Dimension].[Hierarchy].[Level].Members
如果某一个Hierarchy 层次结构没有指定特别的Level时,Members 函数就会返回包含 ALL 以内的所有成员。如果指定了特定的Level,那么就只有这个层次结构Level 上的成员被返回。
另外要注意的是,Members 函数返回的是一个成员的集合(Set) {…},集合本身是由 Tuple 元组(..),(..)构成的,而元组里面的内容是成员[…].[…].[…]. 那么在Members 返回这些成员时,会为每一个成员自动的包装到一个一个的Tuple中,最后所有的Tuple 组成一个集合。
Members 函数查询一示例
SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, { ([Product].[Category].[Accessories]), ([Product].[Category].[Bikes]), ([Product].[Category].[Clothing]), ([Product].[Category].[Components]) } ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])

在这个查询中,ROWS 轴上引用了 Product纬度的 Category层次结构中的四个成员,看看这个结构,先把这些概念分清楚。这也是我之前一直不能理解的东西,分不清楚为什么在 Members 下面能看到 Accessories,Bikes,Clothing,Components 然后在Category 下面也看到这些东西。
Product 维度的层次结构与成员
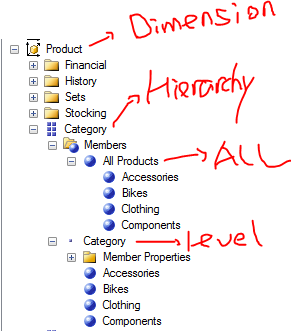
首先看 Product,这个是纬度的名称,通常就说做 Product 纬度。
六个方格表示的 Category 是属性层次结构,换个空间表述它,它就是多维空间中的一个轴。在这里,我们提到的纬度中的属性层次结构一般包含有两个级别,第一个级别是 ALL,第二个级别是具体的成员。
ALL 的作用就是保存聚合了 Accessories,Bikes,Clothing,Components这些成员 的值,所以能看到 [All Products] 这个元素在其它四个子成员之上而位于Category hierarchy 之下。
最下面的Category 表示一个Level,这个Level 很显然在层次结构中位于 ALL 之下,那么所有 ALL 之下的成员就归到这个Level 中在下面一一列出来。所以这里的 Category 不能像 All Products一样表示的是一个成员,而应该是一个Level。
了解了这些之后,我们通过以下这些例子来看看Members 函数使用的效果。
Members 函数查询二示例
SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, { --[Product].[Category].[Category] [Product].[Category].[Category].MEMBERS } ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])
这个查询等同于 Members 函数查询一示例,将这个引用分解下 [Product].[Category].[Category].MEMBERS
[Product 维度].[Category 层次结构].[Category Level].MEMBERS 那么对应上面的Product维度树 Category Level 下的所有成员就是示例一中的那些成员。
也可以写成 [Product].[Category].[Category] 默认情况下也访问到 Category Level 下的所有成员。

更进一步看这个查询
SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, { [Product].[Category].[All Products] -- [Product].[Category] } ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])
这里的 [All Products] 指的不是 Category 下的包括 ALL 的所有成员,而是指 ALL 这一个成员。
也可以省略掉 [All Products] 而直接写成 [Product].[Category] 因为这样只有 维度.层次结构 的情况下默认也是访问 ALL 这个成员,除非 ALL 这个成员被设置为隐藏不可见。
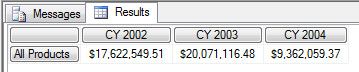
SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, { [Product].[Category].MEMBERS } ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])
[Product].[Category].MEMBERS 才表示包括了 ALL 这个成员的所有成员

8. MeasureGroupMeasures 函数的使用
返回某一个 Measure 组中所有的度量值(非计算)
SELECT {[Product].[Category].Members} ON COLUMNS, {MeasureGroupMeasures("Reseller Sales")} ON ROWS FROM [Step-by-Step]

9. CrossJoin 函数
CrossJoin 函数的作用是可以让一个Set中的所有元祖Tuple 与另外的一个Set中的所有元祖形成一个交叉组合。
语法 - Crossjoin( {Set1},{Set2} [,. . . {Setn} )
CrossJoin 里可以有两个或者两个以上的 SET 作为参数,并且在 SSAS 中可以使用 * 来代替 Crossjoin这个关键字。
SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, Crossjoin( {[Product].[Category].[Category].Members},-- 1 Member Cross Join 2 Measures { ([Measures].[Reseller Sales Amount]), ([Measures].[Reseller Order Quantity]) } ) ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])
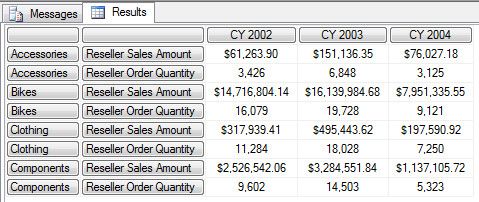
Category Level 下有四个成员 Accessories,Bikes,Clothing,Components 通过与 [Measures] 下的两个成员 Reseller Sales Amount 和 Reseller Order Quantity 交叉连接后,其实就变成了这样的 MDX 查询,查询的结果和上面的示例是一样的。
注意这里的 Measures 也是一个维度,但这个维度比较特殊,它是度量值维度也叫事实维度,它不同于其它的维度,度量值维度是没有 ALL 这个成员的。
SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, { ([Product].[Category].[Accessories],[Measures].[Reseller Sales Amount]), ([Product].[Category].[Accessories],[Measures].[Reseller Order Quantity]), ([Product].[Category].[Bikes],[Measures].[Reseller Sales Amount]), ([Product].[Category].[Bikes],[Measures].[Reseller Order Quantity]), ([Product].[Category].[Clothing],[Measures].[Reseller Sales Amount]), ([Product].[Category].[Clothing],[Measures].[Reseller Order Quantity]), ([Product].[Category].[Components],[Measures].[Reseller Sales Amount]), ([Product].[Category].[Components],[Measures].[Reseller Order Quantity]) } ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])
上面的代码又可以回到第三章的 Partial Tuple 局部元组,理解一下它们在空间中的定位。
CROSSJOIN 也可以用 * 运算符代替,语法是 {SET1} * {SET 2} * {SET..}
SELECT { ([Date].[Calendar].[CY 2002]), ([Date].[Calendar].[CY 2003]), ([Date].[Calendar].[CY 2004]) } ON COLUMNS, {[Product].[Category].[Category].MEMBERS } -- SET 1 * { ([Measures].[Reseller Sales Amount]), ([Measures].[Reseller Order Quantity]) } -- SET 2 ON ROWS FROM [Step-by-Step] WHERE ([Geography].[Country].[United States])
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章.