使用Python获取Wikipedia 的url时出现“ERR_ACCESS_DENIED”怎么办?
最近想用中文维基百科的一些文章进行文本分析,于是想爬一些有用的网页下来。起初找了个叫teleport pro的软件,但几经周折还是没找到方法下载指定层的文本(图片可以),而且下下来很多没用的插件,甚是复杂(网上有人说可以实现,但至今未研究明白,还请高手指点!)。于是用python写了段代码获取指定url的网页。这也是第一次接触urllib等库的使用。
代码如下(Linux 下 Python 2.6):
1 # coding=utf-8
2
3 import urllib
4
5 url='http://zh.wikipedia.org/wiki/Wikipedia:%E5%84%AA%E8%89%AF%E6%A2%9D%E7%9B%AE'
6 loca='/home/yxl/work/crawingpage/wiki.html'
7
8 urllib.urlretrieve(url,loca)
但每次获得的网页都是无法进入该网页的错误信息,返回的网页内容如下:

于是在网上找到了这样一个产生类似问题的帖子,解答说可以用urllib2 加上headers可以解决:
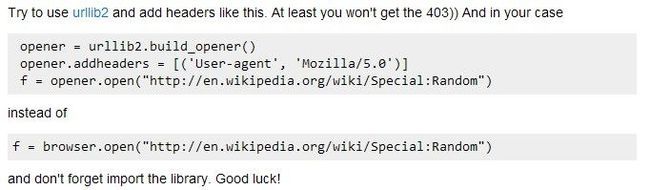
于是我把代码修改后:
1 # coding=utf-8
2
3 import urllib2
4
5 url='http://zh.wikipedia.org/wiki/Wikipedia:%E5%84%AA%E8%89%AF%E6%A2%9D%E7%9B%AE'
6 loca='/home/yxl/work/crawingpage/wiki.html'
7
8 opener = urllib2.build_opener()
9 opener.addheaders = [('User-agent', 'Mozilla/5.0')]
10 urldata = opener.open(url)
11 f=file(loca,'w')
12 m=urldata.read()
13 print>>f,m
可以正确获取该网页了!哦耶!
但是我仍然很困惑之前的程序到底是什么问题造成的?(尚未搞清楚,求高手赐教)
urllib和urllib2到底什么区别呢?
http://www.cnblogs.com/yuxc/archive/2011/08/01/2124073.html中介绍:
Python:urllib 和urllib2之间的区别
You might be intrigued by the existence of two separate URL modules in Python -urllib and urllib2. Even more intriguing: they are not alternatives for each other. So what is the difference between urllib and urllib2, and do we need them both?
urllib and urllib2are both Python modules that do URL request related stuff but offer different functionalities. Their two most significant differences are listed below: urllib 和urllib2都是接受URL请求的相关模块,但是提供了不同的功能。两个最显著的不同如下:
urllib2can accept aRequestobject to set the headers for a URL request,urllibaccepts only a URL. That means, you cannot masquerade your User Agent string etc.urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。这意味着,你不可以伪装你的User Agent字符串等。
urllibprovides theurlencodemethod which is used for the generation of GET query strings,urllib2doesn't have such a function. This is one of the reasons whyurllibis often used along withurllib2.urllib提供urlencode方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
urllib and
urllib2 refer to their documentations, the links are given in the References section.
相关资料
Python Docs