《Java编程思想》之I/O系统
《Java编程思想》之I/O系统 - #include - 博客频道 - CSDN.NET
1、Java中“流“类库让人迷惑的主要原因:创建单一的结果流,却需要创建多个对象。
2、使用层叠的数个对象为单个对象动态地、透明地添加职责的方式,称作“修饰器“模式。修饰器必须与其所修饰的对象具有相同的接口,这使得修饰器的基本应用具有透明性——我们可以想修饰过或没有修饰过的对象发送相同的消息。
3、为什么使用修饰器?
在直接使用扩展子类的方法时,如果导致产生了大量的、用以满足所需的各种可能的组合的子类,这是通常就会使用修饰器——处理太多的子类已经不太实际。
4、修饰器的缺点:增加代码的复杂性。
5、JavaI/O类库操作不便的原因在于:我们必须创建许多类——“核心”I/O类型加上所有的修饰器,才能得到我们所希望的单个I/O对象。
6、FilterInputStream和FilterOutputStream是用来提供修饰器类接口以控制特定输入流和输出流的俩个类。它们分别继承自I/O类库中的基类InputStream和OutputStream。
7、DataInputStream是FilterInputStream的直接子类,它允许我们读取不用的基本类型数据以及String对象。
8、InputStream和OutputStream是面向字节的,而Reader和Writer是面向字符与兼容Unicode。
9、在InputStream和OutputStream的继承层次结构仅支持8位的字节流,并且不能很好地处理16位的Unicode。由于Unicode用用于字符国际化,所以添加Reader和Write继承结构就是为了在所有的I/O操作中都支持Unicode。另外添加了Reader和Write的I/O流类库使得它的操作比旧类库更快。
10、但是,Reader和Write并不是用来取代nputStream和OutputStream的,因为InputStream和OutputStream在面向字节形式的I/O中仍然提供了极有价值的功能。
11、有时,我们需要把来自于“字节”层次结构的类和“字符”层次结构的类结合起来使用。这时,需要使用“适配器(adapter)”类:InputStreamReader可以把InputStream转换为Reader,而OutputStreamWriter可以把OutputStream转换为Writer。
12、当我们使用DataOutputStream时,写字符串并且让DataInputStream能够恢复它的唯一可靠的做法就是使用UTF-8编码。UTF-8是Unicode的变体,后者把所有字符都存储成两个字节的形式。而我们使用的只是ASCII或者几乎是ASCII字符(只占7位),这么做就显得极其浪费空间和宽带,所以UTF-8将ASCII字符编码成单一字节的形式,而非ASCII字符则编码成两到三个字节的形式。另外,字符串的长度存储在两个字节中。
13、System.in是一个没有被加工过的InputStream,所以在读取System.in之前必须对其进行加工。
14、标准I/O重定向:如果我们突然开始在显示器上创建大量输出,而这些输出滚动得太快以至于无法阅读是,重定向输出就显得极为有用。重定向有一下方法:
- SetIn(InputStream)
- SetOut(InputStream)
- SetErr(InputStream)
注意:重定向操作的是字节流(InputStream、OutputStream),而不是字符流。
15、JDK1.4的java.nio.*包引入了新的JavaI/O类库,其目的在于提高速度。速度的提高来自于所使用的结构更接近操作系统的I/O的方式:通道和缓冲器。
我们可以把它想象成一个煤矿,通道是一个包含煤层(数据)的矿藏,而缓冲器则是派送到矿藏的卡车。卡车载满煤炭而归,我们再从卡车上获得煤炭。也就是说,我们并没有直接和通道交互;只是和缓冲器交互,并把缓冲器派送到通道。通道要么从缓冲器获得数据,要么向缓冲器发送数据。
唯一直接与通道交互的缓冲器是ByteBuffer——也就是说,可以存储未加工字节的缓冲器。ByteBuffer是一个相当基础的类:通过告知分配多少存储空间来创建一个ByteBuffer对象,并且还有一个方法选择集,用以原始的字节形式或基本数据类型输出和读取数据。
16、FileInputStream、FileOutputStreaam以及用于既读又写的RandomAccessFile被使用nio重新实现过,都有一个getChannel()方法返回一个FileChannel(通道)。通道是一种相当基础的东西:可以向它传送用于读写的ByteBuffer,并且可以锁定文件的某些区域用于独占式访问。Reader和Writer这种字符模式类不能产生通道;但是java.nio.channels.Channels类提供了实用方法,用以在通道中产生Reader和Wirter。
以下
17、转换数据:缓冲器容纳的是普通的字节,为了把它们转化成字符,我们要么在输入它们的时候对其进行编码,要么在将其从缓冲器输出时对它们进行解码。请参看下面例子:
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import java.nio.ByteBuffer;
- import java.nio.channels.FileChannel;
- import java.nio.charset.Charset;
- public class GetChannel{
- public static void main(String[] args) throws Exception{
- //写入data.txt
- FileChannel fc = new FileOutputStream("data.txt").getChannel();
- fc.write(ByteBuffer.wrap("Some text".getBytes()));
- fc.close();
- //读取data.txt
- fc = new FileInputStream("data.txt").getChannel();
- ByteBuffer buff = ByteBuffer.allocate(1024);
- fc.read(buff);
- buff.flip();
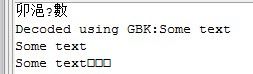
- System.out.println(buff.asCharBuffer());
- //使用系统默认的字符集进行解码(输出时对其进行解码)
- buff.rewind();/返回数据开始的部分
- String encoding = System.getProperty("file.encoding");
- System.out.println("Decodedusing " + encoding + ":"
- + Charset.forName(encoding).decode(buff));
- //再次写入(输入时对其进行编码)
- fc = new FileOutputStream("data.txt").getChannel();
- fc.write(ByteBuffer.wrap("Some text".getBytes("UTF-16BE")));
- fc.close();
- //再次读取
- fc = new FileInputStream("data.txt").getChannel();
- buff = ByteBuffer.allocate(1024);
- fc.read(buff);
- buff.flip();
- System.out.println(buff.asCharBuffer());
- //再次写入(输入时对其进行编码)
- fc = new FileOutputStream("data.txt").getChannel();
- buff = ByteBuffer.allocate(24);
- buff.asCharBuffer().put("Some text");
- fc.write(buff);
- fc.close();
- //再次读取
- fc = new FileInputStream("data.txt").getChannel();
- buff.clear();
- fc.read(buff);
- buff.flip();
- System.out.println(buff.asCharBuffer());
- }
- }
运行结果:
18、获取基本类型:尽管ByteBuffer只能保存字节类型的数据,但是它具有从其所容纳的字节中产生出各种不同的类型值的方法。
- import java.nio.ByteBuffer;
- public class GetData{
- private final static int BSIZE = 1024;
- public static void main(String[] args){
- ByteBuffer bb = ByteBuffer.allocate(BSIZE);
- int i = 0;
- while(i++ < bb.limit()){
- if(bb.get() != 0){
- System.out.println("nonzero");
- }
- }
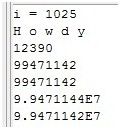
- System.out.println("i = " + i);
- bb.rewind();
- //char
- bb.asCharBuffer().put("Howdy");
- char c;
- while((c = bb.getChar()) != 0){
- System.out.print(c + " ");
- }
- System.out.println();
- bb.rewind();
- //short。是一个特例,必须加上(short)进行类型转换
- bb.asShortBuffer().put((short)471142);
- System.out.println(bb.getShort());
- bb.rewind();
- //int
- bb.asIntBuffer().put(99471142);
- System.out.println(bb.getInt());
- bb.rewind();
- //long
- bb.asLongBuffer().put(99471142);
- System.out.println(bb.getLong());
- bb.rewind();
- //float
- bb.asFloatBuffer().put(99471142);
- System.out.println(bb.getFloat());
- bb.rewind();
- //double
- bb.asDoubleBuffer().put(99471142);
- System.out.println(bb.getDouble());
- bb.rewind();
- }
- }
运行结果:
19、视图缓冲器:可以让我们通过某个特定的基本数据类型的视窗查看其底层的ByteBuffer。
- ByteBuffer bb = ByteBuffer.allocate(BSIZE);
- //asIntBuffer() 创建此字节缓冲区的视图,作为 int 缓冲区。
- IntBuffer ib = bb.asIntBuffer();
20、不同机器可能会有不同的字节排序方法来存储数据。默认的ByteBuffer是以高位优先的顺序存储数据的。考虑下面两个字节:
如果我们以short(ByteBuffer.asShortBuffer)高位优先读出的是97(0000000001100001),若更改ByteBuffer更改为地位优先,则读出的是24832(0110000100000000)。再看下面例子:
- import java.nio.ByteBuffer;
- import java.nio.ByteOrder;
- import java.util.Arrays;
- public class Endians{
- public static void main(String[] args){
- ByteBuffer bb = ByteBuffer.wrap(new byte[12]);
- bb.asCharBuffer().put("abcdef");
- System.out.println(Arrays.toString(bb.array()));
- bb.rewind();
- bb.order(ByteOrder.BIG_ENDIAN);//设置为高位排序
- bb.asCharBuffer().put("abcdef");
- //array()只能对有数组支持的缓冲器调用
- System.out.println(Arrays.toString(bb.array()));
- bb.rewind();
- bb.order(ByteOrder.LITTLE_ENDIAN);//设置为低位排序
- bb.asCharBuffer().put("abcdef");
- System.out.println(Arrays.toString(bb.array()));
- }
- }
运行结果:
21、如果想把一个字节数组写到文件中去,那么应该使用ByteBuffer.wrap()方法把字节数组包装起来,然后用getChannel()方法在FileOutputStream上打开一个通道,接着将来自于ByteBuffer的数据写到FileChannel中去。
22、存储器映射文件:允许我们创建和修改那些因为太大而不能放入内存的文件。有了存储器映射文件,我们就可以假定整个文件都在内存中,而且可以完全把它当作非常大的数组来访问。
尽管“旧”的I/O在用nio实现后性能有所提高,但是“映射文件访问”往往可以更加显著地加快速度。
23、文件加锁机制:允许我们同步访问某个作为共享资源的文件。文件锁对其它操作系统进程是可见的,因为Java的文件加锁之间映射到本地操作系统的加锁工具。另外,利用对映射文件的部分加锁,可以对巨大的文件进行部分加锁,以便其他进程可以对修改文件中未被加锁的部分。
24、压缩:Java压缩类库是按字节方式的,它们继承自InputStream和OutputStream。
1).GZIP:如果只想对单个数据流(而不是一系列互异数据)进行压缩,那么它是比较适合的选择。下面是对单个文件进行压缩的例子:
- import java.io.BufferedOutputStream;
- import java.io.BufferedReader;
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.util.zip.GZIPInputStream;
- import java.util.zip.GZIPOutputStream;
- public class GZIPcompress{
- public static void main(String[] args) throws IOException{
- //InputStreamReader中设置字符编码为GBK
- BufferedReader in = new BufferedReader(new InputStreamReader(new
- FileInputStream("test.txt"), "GBK"));
- BufferedOutputStream out = new BufferedOutputStream((
- new GZIPOutputStream(new FileOutputStream("test.txt.gz"))));
- System.out.println("Writingfile");
- int c;
- while((c = in.read()) != -1){
- //使用GBK字符编码将此 String编码到 out中
- out.write(String.valueOf((char) c).getBytes("GBK"));
- }
- in.close();
- out.close();
- System.out.println("ReadingFile");
- BufferedReader in2 = new BufferedReader((new InputStreamReader
- (new GZIPInputStream(new FileInputStream("test.txt.gz")))));
- String s;
- while((s = in2.readLine()) != null){
- System.out.println(s);
- }
- }
- }
2).用Zip进行多文件压缩:对于每一个要加入压缩档案的文件,都必须调用putNextEntry(),并将其传递给一个ZipEntry对象。
25、对象的序列化:将那些实现Serializable接口的对象转换成一个字节序列,并能够在以后将这个字节序列完全恢复为原来的对象。利用它可以实现“轻量持久性”。
1).“持久化”:意味一个对象的生存周期并不取决于程序是否正在执行。通过将一个序列化对象写入磁盘,然后再重新调用程序时恢复该对象,就能够实现持久性的效果。
2).“轻量级”:因为它不能用某种“persistent”(持久)关键字来简单定一个对象,并让系统自动维护其他细节问题。相反,对象必须在程序中显示地序列化和反序列化还原。
26、对象序列化的概念加入到语言中是为了支持两种主要特性:
1).Java的“远程方法调用”(Remote Method Invocation,RMI)。
2).Java Beans。
27、
1).序列化:创建OutputStream对象,封装到ObjectOutputStream,再调用writeObject()
2).反序列化:创建InputStream对象,封装到ObjectInputStream,再调用readObject()
3).Serializable的对象在还原的过程中,没有调用任何构造器。
28、对象序列化是面向字节的,因此采用InputStream和OutputStream层次结构。
29、序列化的控制:
1).实现Externalizable接口,接口继承自Serializable,添加了writeExternal()和readExternal()两个方法,它们会在序列化和反序列化还原的过程中被自动调用。
2).反序列过程中,对于Serializable对象,对象完全以它存储的二进制位为基础来构造,而不是调用构造器。而Externalizeble对象,普通的缺省构造函数会被调用。
3).transient(瞬时)关键字:只能和Serializable对象一起使用。
- private transient String password;
password将不会被保存到磁盘中。
30、序列化/反序列化static成员:显示调用serializeStaticState()和deserializeStaticState()
31、Preferences:用于存储和读取用户的偏好(preferences)以及程序配置项的设置。只能用于小的、受限的数据集合——我们只能保存基本数据类型和字符串,并且每个字符串的存储类型长度不能超过8K(不是很小,单我们也不想用它来创建任何重要的东西)。它是一个键-值集合(类似映射),存储在一个节点层次结构中。
- import java.util.Arrays;
- import java.util.Iterator;
- import java.util.prefs.BackingStoreException;
- import java.util.prefs.Preferences;
- public class PreferencesDemo{
- public static void main(String[] args) throws BackingStoreException{
- Preferences prefs = Preferences.userNodeForPackage(PreferencesDemo.class);
- prefs.put("日期", "2012年02月05日");
- prefs.put("天气", "晴");
- prefs.putInt("放假多少天了?", 24);
- prefs.putBoolean("现在在家?", true);
- int usageCount = prefs.getInt("寒假还剩多少天?", 16);
- usageCount--;
- prefs.putInt("寒假还剩多少天?", usageCount);
- Iterator<String> it = Arrays.asList(prefs.keys()).iterator();
- while(it.hasNext()){
- String key = it.next().toString();
- //null作为缺省
- System.out.println(key + ":" + prefs.get(key, null));
- }
- System.out.println("放假多少天了?" + prefs.getInt("放假多少天了?", 0));
- }
- }
注意:每次运行,usageCount的值没都减少1。即每次打印出“寒假还剩多少天?”后面的数字都减少1。然而,在程序第一次运行之后,并没有任何本地文件出现。Preferences API利用合适的系统资源完成了这个任务,并且这些资源会随操作系统的不同而不同。例如在windows里,就使用注册表。
32、正则表达式:
1).
在Java ,“\\”意味“我正在插入一个正则表达式反斜杠”,那么随后的字符具有特殊意义。若想插入一个字面意义上的反斜杠,得这样子表示“\\\\”。2).量词:
·贪婪的:竟可能的模式发现尽可能的匹配。
·勉强的:用问号来指定,匹配满足模式所需的最少字符数。
·占有的:只有在Java语言中才可用,并且它也更高效,常常用于防止正则表达式失控,因此可以是正则表达式执行起来更有效。
3).注意abc+与(abc)+的不同。
4).在java中,正则表达式是通过java.util.regex包里面的Pattern和Matcher类来实现的。
·Pattern对象表示一个正则表达式的编译版本。静态的complie()方法将一个正则表达式字符串编译成Pattern对象。
·Matcher对象有matcher()方法和输入字符串编译过的Pattern对象中产生Matcher对象。
5).split()分裂操作将输入字符串断开成字符串对象数组。