Erlang gb_trees
gb_trees (General Balanced Trees) 通用二叉查找树,通常被用作有序字典.与普通未平衡二叉树相比没有额外的储存开销,这里所说的额外的存储开销是指是否使用额外的metadata记录节点相关的信息,dict和array的实现就使用了这样的描述信息,换句话说gb_trees是自描述的.性能优于AVL trees. 相关论文: General Balanced Trees
http://www.2007.cccg.ca/~morin/teaching/5408/refs/a99.pdf
和proplists,orddict相比它能够支持更大的数据量.
平衡二叉树(又称AVL树) ,左右子树的深度只差绝对值不超过1.这个插值称为平衡因子(balance factor),查找,插入和删除在平均和最坏情况下都是O(logn).节点的插入和删除平衡树失衡会触发重新平衡.重新平衡通过四种旋转实现:LL LR RR RL.gb_trees由于节点删除操作并不会增加树的高度,所以节点删除之后并没有进行再平衡.
注: gb_treess数据项比较使用的是相等==操作符.
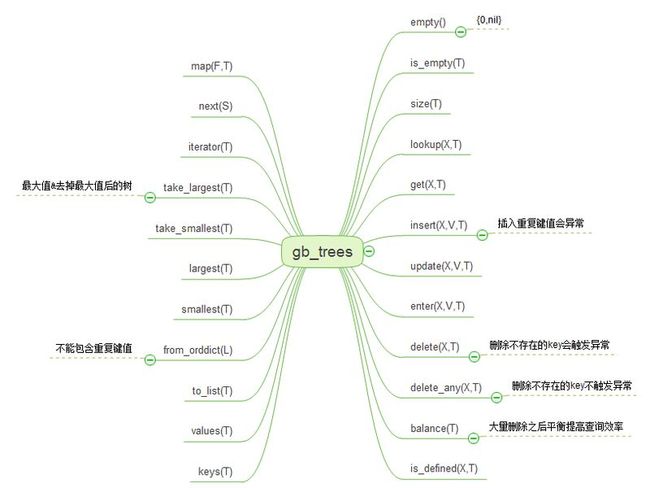
gb_trees数据结构
gb_trees={Size,Tree}Tree= {Key, Value, Smaller, Bigger} |nilSmaller=TreeBigger= Tree
gb_trees操作
Eshell V5.9.1 (abort with ^G) 1> G=gb_trees. gb_trees 2> G:empty(). {0,nil} 3> G:insert(k,v,G:empty()). {1,{k,v,nil,nil}} 4> G:insert(k1,v1,v(3)). {2,{k,v,nil,{k1,v1,nil,nil}}} 5> G:insert(k2,v3,v(4)). {3,{k,v,nil,{k1,v1,nil,{k2,v3,nil,nil}}}} 6> G:insert(k0,v0,v(4)). {3,{k,v,nil,{k1,v1,{k0,v0,nil,nil},nil}}} 7> G:insert(k0,v0,v(5)). {4,{k,v,nil,{k1,v1,{k0,v0,nil,nil},{k2,v3,nil,nil}}}} 8> G:insert(k0,v0,v(6)). ** exception error: {key_exists,k0} in function gb_trees:insert_1/4 (gb_trees.erl, line 321) in call from gb_trees:insert_1/4 (gb_trees.erl, line 283) in call from gb_trees:insert_1/4 (gb_trees.erl, line 300) in call from gb_trees:insert/3 (gb_trees.erl, line 280)
insert操作会触发重新平衡balance(T);删除操作并不触发重新平衡,重新平衡方法大多数时候并不需要显示调用,这个接口暴露出来的目的是元素大量删除之后,通过重新平衡减少查询时间. insert(X, V, T)如果插入重复Key会引发 {key_exists,Key}异常;由于节点删除操作并不会增加树的高度,所以节点删除之后并没有进行再平衡.注意下面的比较:
Eshell V5.9.1 (abort with ^G) 1> T={8,{k,v,nil,{k1,v1,{k0,v0,nil,nil},{k4,v4,{k3,v3,nil,nil},{k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}}}. {8, {k,v,nil, {k1,v1, {k0,v0,nil,nil}, {k4,v4, {k3,v3,nil,nil}, {k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}}} 2> gb_trees:delete(k1,T). {7,{k,v,nil,{k3,v3,{k0,v0,nil,nil}, {k4,v4,nil,{k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}}} 3> gb_trees:balance(v(2)). {7,{k4,v4,{k0,v0,{k,v,nil,nil},{k3,v3,nil,nil}}, {k6,v6,{k5,v5,nil,nil},{k7,v7,nil,nil}}}} 4>
下面lookup方法是gb_trees进行遍历的典型过程:
lookup(Key, {_, T}) -> lookup_1(Key, T). %% The term order is an arithmetic total order, so we should not %% test exact equality for the keys. (If we do, then it becomes %% possible that neither `>', `<', nor `=:=' matches.) Testing '<' %% and '>' first is statistically better than testing for %% equality, and also allows us to skip the test completely in the %% remaining case. lookup_1(Key, {Key1, _, Smaller, _}) when Key < Key1 -> lookup_1(Key, Smaller); lookup_1(Key, {Key1, _, _, Bigger}) when Key > Key1 -> lookup_1(Key, Bigger); lookup_1(_, {_, Value, _, _}) -> {value, Value}; lookup_1(_, nil) -> none.
lookup与get的返回值不同:
6> gb_trees:lookup(k1,T). {value,v1} 7> gb_trees:get(k1,T). v1 8>
update方法就执行类似的遍历过程完成了gb_trees的重建:
update(Key, Val, {S, T}) -> T1 = update_1(Key, Val, T), {S, T1}. %% See `lookup' for notes on the term comparison order. update_1(Key, Value, {Key1, V, Smaller, Bigger}) when Key < Key1 -> {Key1, V, update_1(Key, Value, Smaller), Bigger}; update_1(Key, Value, {Key1, V, Smaller, Bigger}) when Key > Key1 -> {Key1, V, Smaller, update_1(Key, Value, Bigger)}; update_1(Key, Value, {_, _, Smaller, Bigger}) -> {Key, Value, Smaller, Bigger}.
enter 是一个复合操作,相当于update_or_insert,存在就更新,不存在就插入:
enter(Key, Val, T) -> case is_defined(Key, T) of true -> update(Key, Val, T); false -> insert(Key, Val, T) end.
is_defined/2,lookup/2,get/2 都是尾递归操作, keys(T) values(T) 两个操作实现并非尾递归:
keys({_, T}) -> keys(T, []). keys({Key, _Value, Small, Big}, L) -> keys(Small, [Key | keys(Big, L)]); keys(nil, L) -> L. values({_, T}) -> values(T, []). values({_Key, Value, Small, Big}, L) -> values(Small, [Value | values(Big, L)]); values(nil, L) -> L.
smallest(T) largest(T) 顾名思义,取最小最大键值对,smallest/1,largest/1是尾递归实现.
take_smallest(T): returns {X, V, T1} X,V是最小值对应的键值对,T1是去掉最小值后的新树.take_largest(T): returns {X, V, T1}也类似.
18> gb_trees:largest(T). {k7,v7} 19> gb_trees:take_largest(T). {k7,v7, {7, {k,v,nil, {k1,v1,{k0,v0,nil,nil}, {k4,v4,{k3,v3,nil,nil},{k5,v5,nil,{k6,v6,nil,nil}}}}}}} 20> gb_trees:smallest(T). {k,v} 21> gb_trees:take_smallest(T). {k,v, {7, {k1,v1, {k0,v0,nil,nil}, {k4,v4, {k3,v3,nil,nil}, {k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}}} 22>
看take_largest的实现:
take_largest({Size, Tree}) when is_integer(Size), Size >= 0 ->
{Key, Value, Smaller} = take_largest1(Tree),
{Key, Value, {Size - 1, Smaller}}.
take_largest1({Key, Value, Smaller, nil}) ->
{Key, Value, Smaller};
take_largest1({Key, Value, Smaller, Larger}) ->
{Key1, Value1, Larger1} = take_largest1(Larger),
{Key1, Value1, {Key, Value, Smaller, Larger1}}.
要遍历整个树怎么办?gb_trees提供了迭代器
12> gb_trees:next(gb_trees:iterator(T)). {k,v, [{k0,v0,nil,nil}, {k1,v1, {k0,v0,nil,nil}, {k4,v4, {k3,v3,nil,nil}, {k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}]} 13> {Key,Value,I}=gb_trees:next(gb_trees:iterator(T)). {k,v, [{k0,v0,nil,nil}, {k1,v1, {k0,v0,nil,nil}, {k4,v4, {k3,v3,nil,nil}, {k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}]} 14> {Key2,Value2,I2}=gb_trees:next(I). {k0,v0, [{k1,v1, {k0,v0,nil,nil}, {k4,v4, {k3,v3,nil,nil}, {k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}]} 15> 15> gb_trees:iterator(T). [{k,v,nil, {k1,v1, {k0,v0,nil,nil}, {k4,v4, {k3,v3,nil,nil}, {k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}}] 16> I. [{k0,v0,nil,nil}, {k1,v1, {k0,v0,nil,nil}, {k4,v4, {k3,v3,nil,nil}, {k5,v5,nil,{k6,v6,nil,{k7,v7,nil,nil}}}}}] 18>
iterator({_, T}) -> iterator_1(T). iterator_1(T) -> iterator(T, []). %% The iterator structure is really just a list corresponding to %% the call stack of an in-order traversal. This is quite fast. iterator({_, _, nil, _} = T, As) -> [T | As]; iterator({_, _, L, _} = T, As) -> iterator(L, [T | As]); iterator(nil, As) -> As.
mochiweb_headers
mochiweb项目的mochiweb_headers就使用了gb_trees实现:
%% @spec enter(key(), value(), headers()) -> headers() %% @doc Insert the pair into the headers, replacing any pre-existing key. enter(K, V, T) -> K1 = normalize(K), V1 = any_to_list(V), gb_trees:enter(K1, {K, V1}, T). %% @spec insert(key(), value(), headers()) -> headers() %% @doc Insert the pair into the headers, merging with any pre-existing key. %% A merge is done with Value = V0 ++ ", " ++ V1. insert(K, V, T) -> K1 = normalize(K), V1 = any_to_list(V), try gb_trees:insert(K1, {K, V1}, T) catch error:{key_exists, _} -> {K0, V0} = gb_trees:get(K1, T), V2 = merge(K1, V1, V0), gb_trees:update(K1, {K0, V2}, T) end. %% @spec delete_any(key(), headers()) -> headers() %% @doc Delete the header corresponding to key if it is present. delete_any(K, T) -> K1 = normalize(K), gb_trees:delete_any(K1, T).
晚安!


分类:
Erlang