Cowboy 源码分析(二十五)
大家好,之前想改改熬夜的习惯,无奈熬夜的习惯改不过来啊,毕竟熬了几年了,改起来确实费劲,那就继续学习吧,好几天没跟新这个系列了,今天接着上一篇未讲完的继续跟大家分享。
stream_body(Req=#http_req{body_state=waiting}) ->
case parse_header('Transfer-Encoding', Req) of
{[<<"chunked">>], Req2} ->
stream_body(Req2#http_req{body_state=
{stream, fun cowboy_http:te_chunked/2, {0, 0},
fun cowboy_http:ce_identity/1}});
{[<<"identity">>], Req2} ->
{Length, Req3} = body_length(Req2),
case Length of
0 ->
{done, Req3#http_req{body_state=done}};
Length ->
stream_body(Req3#http_req{body_state=
{stream, fun cowboy_http:te_identity/2, {0, Length},
fun cowboy_http:ce_identity/1}})
end
end;
这是上一篇,我们讲到了 cowboy_http_req:stream_body/1 函数,今天我们从 {Length, Req3} = body_length(Req2), 这一行开始,这里调用函数:
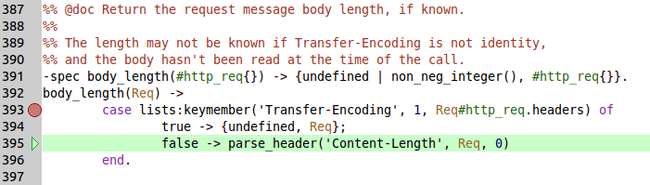
%% @doc Return the request message body length, if known. %% %% The length may not be known if Transfer-Encoding is not identity, %% and the body hasn't been read at the time of the call. -spec body_length(#http_req{}) -> {undefined | non_neg_integer(), #http_req{}}. body_length(Req) -> case lists:keymember('Transfer-Encoding', 1, Req#http_req.headers) of true -> {undefined, Req}; false -> parse_header('Content-Length', Req, 0) end.
这里:
Req#http_req.headers = [{'Cache-Control',<<"max-age=0">>},
{'Connection',<<"keep-alive">>},
{'Accept-Encoding',<<"gzip, deflate">>},
{'Accept-Language',<<"zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3">>},
{'Accept',<<"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8">>},
{'User-Agent',<<"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:13.0) Gecko/20100101 Firefox/13.0.1">>},
{'Host',<<"localhost">>}]
我们可以看到,这个列表中,并不存在第一个元素为 'Transfer-Encoding' 的成员,如果存在,则返回 {undefined, Req}; 否则调用 cowboy_http_req:parse_header/3 函数,我们从传递的参数可以获知调用该函数的第五个分支,代码如下:
parse_header(Name, Req, Default) when Name =:= 'Content-Length' -> parse_header(Name, Req, Default, fun (Value) -> cowboy_http:digits(Value) end);
cowboy_http_req:parse_header/4 这个函数之前讲过,我们重点看下这个匿名函数:
fun (Value) -> cowboy_http:digits(Value) end
这个匿名函数只有一行逻辑,调用了 cowboy_http:digits(Value) 我们看下这个函数的具体实现:
%% @doc Parse a list of digits as a non negative integer. -spec digits(binary()) -> non_neg_integer() | {error, badarg}. digits(Data) -> digits(Data, fun (Rest, I) -> whitespace(Rest, fun (<<>>) -> I; (_Rest2) -> {error, badarg} end) end). -spec digits(binary(), fun()) -> any(). digits(<< C, Rest/binary >>, Fun) when C >= $0, C =< $9 -> digits(Rest, Fun, C - $0); digits(_Data, _Fun) -> {error, badarg}. -spec digits(binary(), fun(), non_neg_integer()) -> any(). digits(<< C, Rest/binary >>, Fun, Acc) when C >= $0, C =< $9 -> digits(Rest, Fun, Acc * 10 + (C - $0)); digits(Data, Fun, Acc) -> Fun(Data, Acc).
这里cowboy_http:whitespace/2 这个函数之前在Cowboy 源码分析(十三) Cowboy 源码分析(十四) 详细介绍过,这里又遇到这种嵌套的匿名函数,可读性实在是太不好了,所以不推荐大家编写这样的代码,下图是这个函数之前的测试例子,我贴过来,大家回忆下:
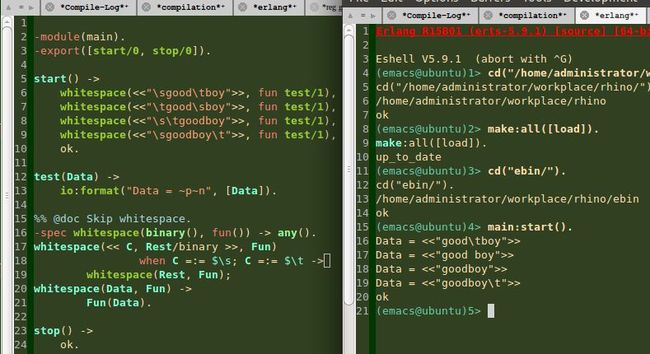
对于 digits 相关的函数,我写了测试代码如下图:
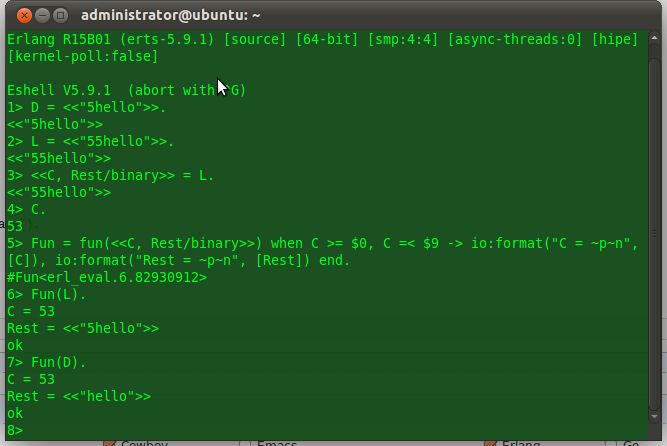
有了图中的例子,相信大家对下面这两个函数就会加深一定的了解:
-spec digits(binary(), fun()) -> any(). digits(<< C, Rest/binary >>, Fun) when C >= $0, C =< $9 -> digits(Rest, Fun, C - $0); digits(_Data, _Fun) -> {error, badarg}. -spec digits(binary(), fun(), non_neg_integer()) -> any(). digits(<< C, Rest/binary >>, Fun, Acc) when C >= $0, C =< $9 -> digits(Rest, Fun, Acc * 10 + (C - $0)); digits(Data, Fun, Acc) -> Fun(Data, Acc).
其实,在读Erlang代码时,对于二进制数据的处理,相对于其他语言,理解上需要大家多加强下,多用用就好了。
接下来我们就可以看下cowboy_http_req:parse_header/4 这个函数:
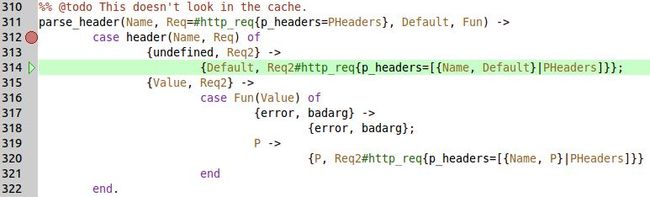
%% @todo This doesn't look in the cache. parse_header(Name, Req=#http_req{p_headers=PHeaders}, Default, Fun) -> case header(Name, Req) of {undefined, Req2} -> {Default, Req2#http_req{p_headers=[{Name, Default}|PHeaders]}}; {Value, Req2} -> case Fun(Value) of {error, badarg} -> {error, badarg}; P -> {P, Req2#http_req{p_headers=[{Name, P}|PHeaders]}} end end.
这个函数之前也讲过,具体看下Cowboy 源码分析(十五) 这里跟之前差别不大,参数不同,相信大家能够理解。
好了,我们通过下面四个图整理下函数的执行顺序以及各个函数的具体执行过程。
图一:
图二:
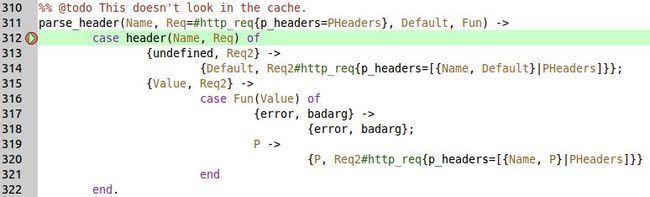
图三:
< Req2#http_req{p_headers = [{'Content-Length',0},
{'Transfer-Encoding',[<<"identity">>]},
{'Connection',[<<"keep-alive">>]}]
图四:

好了,今天就到这里,一不小心,又快2点了。下一篇,我们继续图四断点处下一行继续跟大家分享。
最后,依然谢谢大家的支持。