【高性能web开发】 SQL Server入门(一)用户表
本文只是一个入门级别的数据库案例。
希望能通过一些经典案例的分析,大家能共同讨论和分享。
数据库案例(一)简单的用户表。
业务假设:
用户表,10个列,无外键, 200万数据 (如果数据量再大一般就考虑分表了)
以下是假设的操作分布 (仅供参考)
50% 按照用户Id查询
40%按照用户名查询
8%按照Email查询
1.5%修改用户的数据,例如状态,最后登录时间
0.5%添加用户数据
操作特征:一般都只有单条数据的查询
(如果有分析和统计,一般弄一个同步库出来,在那个单独的库上做较大数据量的分析)
(某些操作,例如用户排名,最近用户操作等,一般是用其他的方式实现,而不是直接压在用户表上)
(当然,如果数据量要求不大。。。。其实你做什么都没关系)
软硬件环境:
CPU: I5
内存:4GB
OS:Windows 7 x64 旗舰版
SqlServer 2008R2 企业版
(不是服务器环境,有些配置没有达到最优化)
先创建用户表,插入200万+数据 (Id为聚集索引,而且连续分布,经常删除数据会导致数据不连续降低性能,所以有些时候选择通过状态位假删数据)
CREATE TABLE [dbo].[User](
[Id] [int] IDENTITY(1,1) NOT NULL,
[UserName] [varchar](255) NOT NULL,
[Password] [varchar](255) NOT NULL,
[Email] [varchar](255) NOT NULL,
[Age] [smallint] NULL,
[Gender] [smallint] NULL,
[Signature] [varchar](255) NULL,
[CreatedTime] [date] NOT NULL,
[LastActivityTime] [date] NOT NULL,
[Status] [int] NULL,
[UserNameCode] [binary](16) NULL,
CONSTRAINT [PK_User] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
由于只有3个列支持条件查询,而Id列是默认的聚集索引,所以只要新建两个索引,分别在UserName列和Email列 (一般来说所有可能出现在where语句中的列 都应该建立索引)
总所周知,过多的索引会降低修改性能,而该案例中查询远比修改来的多
第一:按照Id查询 (聚集索引,Id连续)
Declare @Stopwatch datetime
declare @number int
Set @Stopwatch=GetDate()
set @number=0
while (@number<1000)
begin
select * from [user] where id=cast(rand()*2000000 as int)
set @number=@number+1
end
Print DateDiff(ms, @Stopwatch, GetDate()); -- 查询1000次 输出结果为 22773 毫秒
第二:按照用户名查询 (Email是一样的)
1.无索引,无数据缓存,(查询1次 15秒左右)
DBCC DROPCLEANBUFFERS --这句清除数据的缓存
select * from [user] where username = 'user_'+cast(cast(rand()*2000000 as int) as varchar) --用户名的规则是 user_id 实在不好找其他的高命中率的例子了 勉强用吧
2.无索引 ,有数据缓存 (1000次随机查询,71473毫秒)
Declare @Stopwatch datetime
declare @number int
Set @Stopwatch=GetDate()
set @number=0
while (@number<1000)
begin
select * from [user] where username = 'user_'+cast(cast(rand()*2000000 as int) as varchar)
set @number=@number+1
end
Print DateDiff(ms, @Stopwatch, GetDate());
-- 查询1000次 输出结果为71473 毫秒
Sql Server,自动给这个列建立了非聚集索引,看以下截图
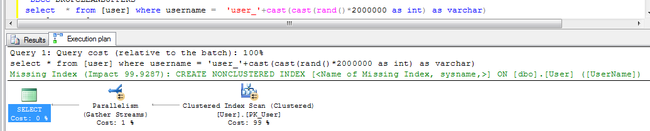
3.有非聚集索引
在UserName列上建立从立非聚集索引 (整表占用的索引空间从1M增加到80M,表本身空间还是461M,索引大小和列里面数据的大小有直接关系)
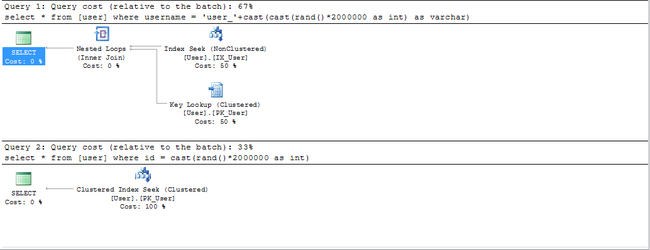
以下是执行计划,使用username 查询和使用id查询的对比, 可以看使用username的查询大约比id查询多消耗一倍的资源,实际情况恶劣的多,因为用户名无规律而且长度还高
有的解决方案是为username生成一个HashCode,哈希值经过优化以后可以实现较小体积 (32/64位) 和均匀分布上等优化 (Hash可是号称0(1)的查询时间复杂度。。)
第三种:修改用户状态,密码,最终登录时间和余额等
本例中,只有UserName和Email建立了索引,但是这两个列在逻辑中都考虑为不可修改的
所有可以修改的列都没有建立索引 (主要是修改的成本太高了)
考虑了修改粒度尽可能小,SQL Server 2005版本和以上支持行锁
第四:添加新用户数据
要注意的是添加新数据加的是表锁。。。
第五:混合操作
这东西一靠基本功,例如了解锁类型,锁粒度,隔离级别等概念,这篇文章应该是比较有用处的,http://msdn.microsoft.com/en-us/library/ms190615.aspx
二靠工具模拟和测试,压力测试工具,性能测试工具,SqlServer Profiler
附录:
1.清除缓存
DBCC FREEPROCCACHE - plan cache, removes a specific plan from the plan cache by specifying a plan handle or SQL handle, or removes all cache entries associated with a specified resource pool. -- This can be used for freeing procedure cahce
DBCC DROPCLEANBUFFERS - Removes all clean buffers from the buffer pool. -- Memory cache
2.重建索引
ALTER INDEX ALL ON [User] REBUILD
ALTER INDEX ALL ON [user] REORGANIZE
3.SQL Server数据库生成HashKey的函数
HashBytes('md5', Username)
4.查询目前的lock: sp_lock (sp_who, sp_who2也是很有用的,还有object_name()获取对象名)