自己圈养小爬虫(一)——下载页面
因为要转到Java阵营,最近开始系统的看Java方面的书籍,正好自己需要大量的图片,所以就有了写一个爬虫,把自己设定的几个网站上所有的图片抓取下来,顺便练习Java。
对爬虫程序一直都比较好奇,但没有过任何经验,在参考前辈的理念基础上尽量自己发挥。
爬虫完成前都是边写边改,可能后期的设计和现在的不太一样,但是也反映了思维的变化,觉得也是不错的事情。
根据自己的需求,这个爬虫的基本流程暂设定为:
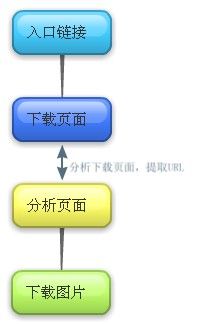
流程设定的比较简单,而且数据流不会过于庞大,所以也没下载下来保存成了文本文件,而没有存入数据库。
首先建立一个XML文件用来保存保存的路径等信息,这些东西不应该写死,config.xml:
<spider>
<sleeptime> 100</sleeptime>
<saveFilePath>E:/www/tmp/</saveFilePath>
<saveImagePath>E:/www/ img/</saveImagePath>
< data>E:/www/ data/</ data>
</spider>
<sleeptime> 100</sleeptime>
<saveFilePath>E:/www/tmp/</saveFilePath>
<saveImagePath>E:/www/ img/</saveImagePath>
< data>E:/www/ data/</ data>
</spider>
下面就是读取XML类Config.java:
package com.catcoder.config;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers. *;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class Config {
public static int SLEEP_TIME = 100;
public static String FILE_PATH = "";
public static String IMAGE_PATH = "";
public static String DATA_PATH = "";
private Document document;
public Config() throws ParserConfigurationException,
import org.xml.sax.SAXException;
public class Config {
public static int SLEEP_TIME = 100;
public static String FILE_PATH = "";
public static String IMAGE_PATH = "";
public static String DATA_PATH = "";
private Document document;
public Config() throws ParserConfigurationException,
SAXException,
IOException{
DocumentBuilderFactory documentBF = DocumentBuilderFactory.newInstance();
DocumentBuilder db = documentBF.newDocumentBuilder();
document = db.parse( new File( "src/com/catcoder/config/config.xml"));
}
public void Load(){
NodeList nl1 = document.getElementsByTagName( "sleeptime");
NodeList nl2 = document.getElementsByTagName( "saveFilePath");
NodeList nl3 = document.getElementsByTagName( "saveImagePath");
NodeList nl4 = document.getElementsByTagName( "data");
if( nl1.getLength() > 0 &&
DocumentBuilderFactory documentBF = DocumentBuilderFactory.newInstance();
DocumentBuilder db = documentBF.newDocumentBuilder();
document = db.parse( new File( "src/com/catcoder/config/config.xml"));
}
public void Load(){
NodeList nl1 = document.getElementsByTagName( "sleeptime");
NodeList nl2 = document.getElementsByTagName( "saveFilePath");
NodeList nl3 = document.getElementsByTagName( "saveImagePath");
NodeList nl4 = document.getElementsByTagName( "data");
if( nl1.getLength() > 0 &&
nl2.getLength()
>
0
&&
nl3.getLength()
>
0
&&
nl4.getLength()
>
0){
SLEEP_TIME = Integer.parseInt(nl1.item( 0).getTextContent());
FILE_PATH = nl2.item( 0).getTextContent();
IMAGE_PATH = nl3.item( 0).getTextContent();
DATA_PATH = nl4.item( 0).getTextContent();
} else{
System.out.println( "配置文件不完整。");
}
}
}
SLEEP_TIME = Integer.parseInt(nl1.item( 0).getTextContent());
FILE_PATH = nl2.item( 0).getTextContent();
IMAGE_PATH = nl3.item( 0).getTextContent();
DATA_PATH = nl4.item( 0).getTextContent();
} else{
System.out.println( "配置文件不完整。");
}
}
}
这些数据应该是整个项目通用,所以几个参数使用static来修饰。简单的配置之后,开始第一步,给出一个入口地址,然后下载页面。在Java中使用HttpURLConnection来建立HTTP请求并下载页面,根据返回的状态,如果状态为200则说明请求成功,将请求到的数据进行处理并保存。处理数据是,为了减少数据量,将网页中的script、link、style等标签全部去除,去除标签的style属性。全部代码,DownPage.java:package com.catcoder.down;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Date;
import java.text.SimpleDateFormat;
import com.catcoder.config.Config;
public class DownPage {
private URL url;
private int responseCode;
private HttpURLConnection urlConnection;
private BufferedReader reader;
private String line;
private String savePath = "";
private String fileName = "";
private SimpleDateFormat sdf;
private FileOutputStream fos;
private BufferedOutputStream bos;
public DownPage(String urls){
setURL(urls);
}
/**
* 下载页面
*/
public void getPage(){
try {
System.out.println( "---------------------------\n开始下载");
urlConnection = (HttpURLConnection)url.openConnection();
responseCode = urlConnection.getResponseCode();
if(responseCode == 200){
reader = new BufferedReader( new InputStreamReader(urlConnection.getInputStream(), "UTF-8"));
StringBuilder sbPage = new StringBuilder();
while((line =reader.readLine()) !=null){
sbPage.append(line);
}
System.out.println( "下载结束\n保存页面");
saveDownPage(sbPage.toString());
} else{
System.out.println( "未找到网页。");
}
} catch (IOException e) {
// TODO Auto-generated catch block
System.out.println(e.toString());
e.printStackTrace();
}
}
/**
* 根据String类型的URL下载页面
* @param urls
*/
public void getPage(String urls){
setURL(urls);
getPage();
}
/**
* 根据URL下载页面
* @param urls
*/
public void getPage(URL urls){
url = urls;
getPage();
}
/**
* 保存下载下来的网页
*/
private void saveDownPage(String code){
code = removeExcess(code);
try{
savePath = Config.FILE_PATH;
sdf = new SimpleDateFormat( "yyyy-MM-dd-HH-mm-ss-SS");
fileName = sdf.format( new Date()) + ".txt";
fos = new FileOutputStream( new File(savePath, fileName));
bos = new BufferedOutputStream(fos);
bos.write(code.getBytes());
bos.flush();
bos.close();
fos.close();
System.out.println(fileName + "保存完成\n---------------------");
} catch(Exception e){
System.out.println(e);
}
}
/**
* 删除无用的标签
* @param code
* @return
*/
private String removeExcess(String code){
code = code.replaceAll( "<script[^>]*?>.*?</script>", "");
code = code.replaceAll( "<style[^>]*?>.*?</style>", "");
code = code.replaceAll( "<link(.*?)/>", "");
code = code.replaceAll( "style=\"(.*?)\"", "");
return code;
}
/**
* 设置将要下载的URL
*/
private void setURL(String urls){
try{
url = new URL(urls);
} catch (Exception e) {
// TODO: handle exception
System.out.println(e.toString());
}
}
}
去除标记选用正则匹配。在正则匹配的时候由于要匹配例如:<a href="#" style="border:0;">这样的标记中的style属性,最初用的正则是:style=\".*\"。后来发现这样做,会把第一个style属性之后到最后一个引号之前的全部数据都清楚掉,不知道当时怎么脑袋想出这么XX的正则来,不过正则一直也算是短板,用万能的google得知了一个有用的方式:(.*?)。这是正则中的分组,这样就把表达两个相邻引号中的所有数据了,就不用一直匹配到最后一个引号。同样的,简单的匹配IP地址格式的数字可以用:(\d{1,3}\.){3}\d{1,3}。这个正则前面的(\d{1,3}\.)就是一个分组,加上后面的{3}就表示这个分组重复3次。分组中的内容表示一到三位数字后面跟一个点。当然,这种匹配对IP地址来说是有问题的,因为它可以匹配出999.999.999.999这样的数据,所以这里只是举例说明分组,并不是真正的IP匹配。真正的IP匹配正则是:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)