Steins;Gate 主程序汉化流程
网上鲜有游戏汉化的教程,不知是技术封锁还是什么的,呵呵。
我自己摸索出了一些方法,拿来跟大家分享一下。
欢迎高手批评指正。
第一步,修改字符集。
要修改程序使原程序从支持shift-JIS编码变为支持GBK/GB2312编码,通常我们要修改游戏中调用的系统函数CreateFont或CreateFontIndirect所调用的参数中的字符集的值,具体函数原型可查阅MSDN。
日文游戏汉化常用到的字符集有SHIFTJI_CHARSET(日文)、GB2312_CHARSET(简中)、CHINESEBIG5_CHARSET(繁中)
所对应的值分别为128、134、136,转换成十六进制为 0x80、0x86、0x88。
因为是第一次做汉化,之前我曾推测利用更改游戏调用的字符集来实现中文的输出,所以我们的目的很简单,就是把游戏主程序中的字符集由80更改为86。
S;G把某几句对话放在同一个文本框里,而且游戏的机理是在每次生成文本框之前设置文字一系列的参数,
这里面就包括设置CharSet=0x80。
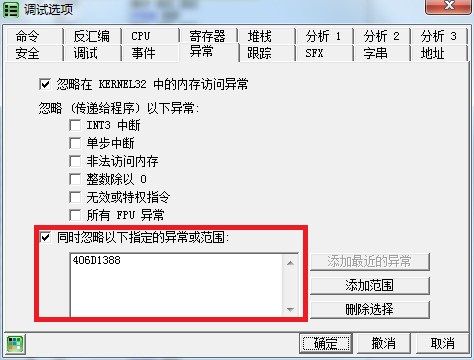
用Ollydbg打开STEINSGATE.exe,在调试选项里添加忽略异常406D1388,如下图。
在模块STEINSGA反汇编窗口右键查找->当前模块中的名称,并设置断点(三个)。

按F9运行游戏,不一会程序停在了0049A54E处,可以看出这里调用了函数CreateFontIndirectA。往上可以找到PUSH EBP这句,EBP的值是函数的参数。
在数据窗口中跟随EBP,数据窗口中的红色方框圈住的就是字符集的值,后面的“俵俽 僑僔僢僋”(绿色方框)是字体名称,
即shift-JIS编码的“MS ゴシック”,也就是MS Gothic ,为日文操作系统的默认字体。
继续往上查找,可以发现在0049A4ED处的 CALL STEINSGA.0053C12F。经测试发现当这条语句执行过后EBP即发生了改变。
仔细观察发现反汇编窗口中的红色方框圈住的这条语句执行后,数据窗口中的数据发生了变化,恰恰就是80,说明这句是设置字符集值的。

那么接下来就好办了直接在红色方框处直接把DL替换为86,但是汇编后发现出现了违规访问。仔细对比发现少了几条语句,再添加又很麻烦。
不如直接在蓝色方框处把DL赋值为86这样就不会出现异常了。

汇编后如下图:

灰色高亮处为无意义的语句,用NOP代替以免出错。
F9运行游戏,变成乱码了。哦也!!!
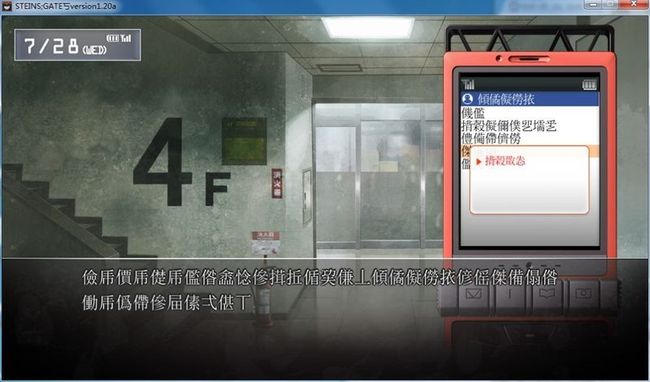
这说明第一步已经成功了。
PS:字体也能修改的说,我试了试,太麻烦,我懒得弄。
提供点线索:
0049A4ED处的语句CALL STEINSGA.0053C12F语句就是调用设置字体的子程序。按F7步入,下图即为设置字体的程序段
可以发现ESI指定了需要修改的数据偏移地址。
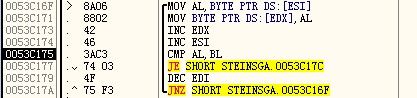
往上查找到这条语句即是修改ESI的

EBP+10 = 0012F920 处为0012FA40

0012FA40指向的堆栈数据区域的数据为826C 8272 20 826F 8353 8356 8362 834E,即“俵俽 僑僔僢僋”。

但是堆栈中的数据是从哪来的暂时就不知道了。
第二步,修改字符范围判定。
Shift-JIS
半角片假名:单字节
第一个字节0xA1 - 0xDF(63个)
JIS x 0208字符:双字节(47 x 188 = 8836)
第一个字节范围0x81 - 0x9F,0xE0 - 0xEF(47个)
第二个字节范围0x40 - 0x7E,0x80 - 0xFC(188个)
GBK/2: GB2312 汉字
双字节(72 x 94 = 6768 )
高位字节范围0xB0 - 0xF7(72个)
低位字节范围0xA1 - 0xFE(94个)
GBK/3: 扩充汉字
双字节(32 x 191 = 6112)
高位字节范围0x81 - 0xA0(32个)
低位字节范围0x40 - 0xFE(191个)
GBK/4: 扩充汉字
双字节(85 x 97 = 8245)
高位字节范围0xAA - 0xFE(85个)
低位字节范围0x40 - 0xA0(97个)
修正:早上把符号给忘了。。 :P
GBK/1: GB2312非汉字符号
双字节(9 x 95 = 855)
高位字节范围0xA1 - 0xA9(9个)
低位字节范围0xA0 - 0xFE(95个)
GBK/5: 扩充非汉字
双字节(2 x 97 = 194)
高位字节范围0xA8 - 0xA9(2个)
低位字节范围0x40 - 0xA0(97个)
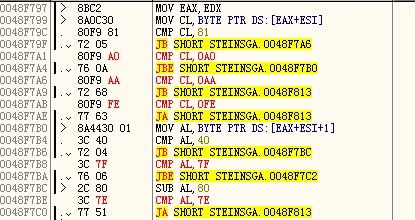
分别查找命令:CMP AL,81 CMP BL,81 CMP CL,81 CMP DL,81
找到三处:
1.0041E646 CMP AL,81
2.004B2C52 CMP AL,81
3.0048F79C CMP CL,81
经过测试,
第一,二处为检验日语汉字上面标注的平假名
第三处检验下面的字符
程序只有在本句话中有注音时才跳转到第一,二处。
按照最大范围修改如下。
0x81 - 0xA0,0xAA - 0xFE
0x40 - 0x7F, 0x80 - 0xFE
0x81 - 0xA9, 0xAA - 0xFE
0x40 - 0x7F, 0x80 - 0xFE
即下图的0048F7A1处应为 CMP CL, 0A9
修改一下字幕文件,运行游戏

至此,游戏的主程序汉化就大致完成了。
至于第一处就不用修改了,除非你想在汉字上面加些拼音玩玩。
游戏在.nsb中用类似以下的语句来实现注音的
<RUBY text="側偐偽偪">拞敨</RUBY>
另外*.nsb文件结构目前也已经搞懂了,最近几天就会写出一个程序来实现文字的录入。
有了文字录入程序,剩下的就是体力活了,那就是把大量的文字打出来。
然后打包就可以实现游戏的字幕汉化了,修图也比较随意。
还有一些细节没有解决,比如手机短信的文字存放在何处还不确定。
附:汉化补丁(基于1.10)http://u.115.com/file/dn6f7j8s
PS
CMP AL,81处的修改方法

8月6日补充:
由于某些原因,我目前已经不再进行汉化工作了,辜负了大家的热情,我把一些我用到的东西都打包放在了 这篇日志 的最后。
这篇日志也是早就有了,可是大家都没有发现……故做个链接。
另关于字体方面的修改,上面的描述并不准确,具体见汉化工具包。
至于汉化补丁,我建议大家期待KFC特创组吧。