character set,utf 8, unicode, ansi
Character sets
Contributed by Ken Fowles, Personal Systems Division, Microsoft.
This page starts with a summary, then digs into ASCII, OEM, ANSI, DBCS, and Unicode character sets, and how character sets affect technology at Microsoft.
Summary
Character sets affect two fundamental parts of your code:
- How you store or transmit data, your file format.
- String processing, the logic with which you manipulate text.
Character sets do not solve:
- Locale-awareness, formatting preferences.
- Special input requirements, keyboard layouts, IMEs.
- Text layout, fonts and other display issues.
In the dark ages, developers generally ignored character sets. Since one ANSI character set can handle Western European languages like English, French, German, Italian and Spanish, other languages were considered special cases or not handled at all.
Many, but not all of the world's major writing systems can be represented within 256 characters, using individual 8-bit character sets. It's important to note there isn't an 8-bit character set which can represent all of these languages at once, or even just the languages required by the European Union.
Languages which require more than 256 characters include: Chinese (Traditional and Simplified), Japanese, and Korean (Hangeul). It is a requirement, not an option, that any application which touches text in these languages needs to correctly handle DBCS or Unicode string processing and data. Unless you enjoy throwing away a lot of code and algorithms, it's best to implement this from day one in all your text handling code.
ASCII
ASCII is contained within 2 to the 7th power, or 128 characters. There's room in ASCII for upper and lowercase English, American English punctuation, base 10 numbers, a few control characters and not much else. Although very primitive, it's important to note ASCII is the one common denominator contained in all the other common character sets - so the only means of interchanging data across all major languages (without risk of character mapping loss) is to use ASCII (or have all sides understand Unicode). For example, the safest way to store filenames on a typical network today is using the ASCII subset of characters. If you manually log into CompuServe, they require a 7-bit instead of 8-bit modem protocol, since their servers were originally ASCII-based.
OEM 8-bit characters
Back in the DOS days, separate Original Equipment Manufacturer code pages were created so that text-mode PCs could display and print line-drawing characters. They're still used today for direct FAT access, and for accessing data files created by MS-DOS based applications. OEM code pages typically have a 3-digit label, such as CP 437 for American English.
The emphasis with OEM code pages was linedraw characters. It was a good idea at the time, since the standard video for the original IBM PC was a monochrome text card with 2k RAM, connected to an attractive green monitor. However the drawing characters took up a lot of space in the 256 character map, leaving very little room for international characters. Since each hardware OEM was free to set their own character standards, some situations continue today where characters can be scrambled or lost even within the same language, if two OEM code pages have different character code points. For example a few characters were mapped differently between Russian MS-DOS and Russian IBM PC-DOS, so data movement is unreliable, or software has to be written to map between each special case.
Users aren't going to suddently erase all their old data and reformat all their disks. The raw data and FAT filenames created with OEM code pages will be around for a long time.
Windows ANSI
Since Windows GDI overrides the need for text-based line draw characters, the old OEM line-draw characters could be freed up for something more useful, like international characters and publishing symbols. An assortment of 256-character Windows ANSI character sets cover all the 8-bit languages targeted by Windows.
You can think of Windows ANSI as a lower 128, and an upper 128. The lower 128 is identical to ASCII, and the upper 128 is different for each ANSI character set, and is where the various international characters are parked.
| code page | 1250 | 1251 | 1252 | 1253 | 1254 | etc., |
| upper 128 |
Eastern Europe | Cyrillic | West Euro ANSI |
Greek | Turkish | etc., |
| lower 128 |
ASCII | ASCII | ASCII | ASCII | ASCII | etc., |
The European Union includes more languages than Code Page 1252 can cover - specifically Greek is missing, and there's no way to fit it all into 256 characters. Switching entirely to Unicode would allow coverage of all EU languages (and a lot more) in one character set, but that conversion is not automatic, and requires every algorithm which touches text is inspected or rewritten. So an interim solution available, which allows the spanning of multiple ANSI code pages within one document - Multilingual Content I/O. Remember this is for multilingual document content, not user interface - two separate issues.
DBCS
DBCS stands for Double Byte Character Sets but are actually multi-byte encodings, a mix of 8-bit and 16-bit characters. Modern writing systems used in the Far East region typically require a minimum of 3k-15k characters.
There are several DBCS character sets supported by Far East editions of Microsoft Windows. Leadbytes signal that the following byte is a trailbyte of the 16-bit character unit, instead of the start of the next character. Each DBCS code page has a different leadbyte and trailbyte range. No leadbytes fall within the lower 127 (ASCII) range, but some trailbytes do.
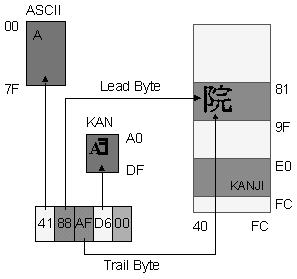
Sample Shift-JIS String
4 Code Range
- ASCII
-
1st lead byte range - Kana
-
2nd lead byte range
The main rules for DBCS-enabling are:
- Always move entire characters, not bytes. Never let a 16-bit character get split up, don't allow an edit/insertion point in the middle of a 16-bit character. Check all your string algorithms for this.
- Never code to specific leadbyte/trailbyte ranges - that will lock your code into one FE language. Instead, ask Windows for the answer using GetCPInfo (generic across all encodings) or IsDBCSLeadByte (DBCS systems)
- p+ + and p- - will march your pointer right into the center of a DBCS character and break. Use CharPrev and Charnext instead. Charprev/next is the best way to go, since it behaves consistently across ANSI, DBCS and Unicode.
What is Unicode / ISO 10646 ?
Unicode is a 16-bit character set which contains all of the characters commonly used in information processing. Approximately 1/3 of the 64k possible code points are still unassigned, to allow room for adding additional characters in the future.
Unicode is not a technology in itself. Sometimes people misunderstand Unicode and expect it to 'solve' international engineering, which it doesn't. Unicode is an agreed upon way to store characters, a standard supported by members of the Unicode Consortium.
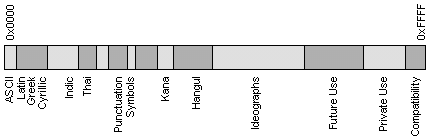
The fundamental idea behind Unicode is to be language-independent, which helps conserve space in the character map - no single character is assumed to identify a language in itself. Just like a character "a" can be a French, German or English "a" even if they have different meanings, a particular Han ideograph might map to a character used in Chinese, Japanese and Korean. Sometimes native speakers of these languages misunderstand Unicode as not "looking" correct in Japanese for example, but that's intentional - appearance should reside in the font as an artistic issue, not the code point as an engineering issue. Although it's technically possible to ship one font which covers all Unicode characters, it would have very limited commercial use, since end-users in Asia will expect fonts dedicated and designed to look correct in their language.
This language-independence also means Unicode does not imply any sort order. The older 8-bit and DBCS character sets usually contain a sort order, but this means they had to create a new character set to change the sort order, which makes a mess out of data interchange between languages. Instead, Unicode expects the host operating system to handle sorting, as the Win32 NLS APIs do.
Data interchange between languages
This is where Unicode has the clearest advantage compared to code pages. Unicode is essentially a superset of every Windows ANSI, Windows DBCS and DOS OEM character set. So for example an Unicode-based Internet browser could let its user simultaneously view Web pages which contained text in practically any language, as long as they have the appropriate fonts on their machine.
Unicode is even useful for products which don't rely on Unicode for string processing, since it makes a good common denominator for mapping characters between code pages. Instead of manually creating an almost infinite set of possible mapping tables between every code page, it's easier to map from one codepage to Unicode, and then back over to the other codepage. The Win32 SDK sample UCONVERT shows how to use the system's *.nls tables to accomplish part of this task.
Impact on your project
Unicode-enabling is not an automatic process - since it requires 16-bit characters, many of the same ANSI coding assumptions which will break on DBCS will also break on Unicode - for example your pointer math can't assume 8 bit characters, and you will need to test to verify correct string handling, in every place your code directly touches text. Fortunately there are some shortcuts.
Twelve steps to Unicode-enabling【熊猫注:这几条不错啊】
from Developing International Applications pages 109-111, Microsoft Press:
- Modify your code to use generic data types.
Determine which variables declared as char or char* are text, and not pointers to buffers or binary byte arrays. Change these types to TCHAR and TCHAR*, as defined in the Win32 file windows.h, or to _TCHAR as defined in the VC++ file tchar.h. Replace LPSTR and LPCH with LPTSTR and LPTCH. Make sure to check all local variables and return types. Using generic data types is a good transition strategy because you can compile both ANSI and Unicode versions of your program without sacrificing the readability of the code. Don't use generic data types, however, for data that will always be Unicode or always ANSI. For example, one of the string parameters of MutliByteToWideChar and WideCharToMultiByte should always be in ANSI and the other should always be in Unicode. - Modify your code to use generic function prototypes.
For example, use the C run-time call _tclen instead of strlen, and use the Win32 API GetLocaleInfo instead of GetLocaleInfoA. If you are also porting from 16 bits to 32 bits, most Win32 generic function prototypes conveniently have the same name as the corresponding Windows 3.1 API calls (TextOut is one good example). Besides, the Win32 API is documented using generic types. If you plan to use Visual C++ 2.x or higher, become familiar with the available wide-character functions so that you'll know what kind of function calls you need to change. Always use generic data types when using generic function prototypes. - Surround any character or string literal with the TEXT macro.
The TEXT macro conditionally places an L in front of a character literal or a string literal. The C run-time equivalents are _T and _TEXT. Be careful with escape sequence specifying a 16-bit Unicode double-quote character, not as the beginning of a Unicode string. Visual C++ 2 treats anything within L" " quotes as a multibyte string and translates it to Unicode byte by byte, based on the current locale, using mbtowc. One possible way to create a string with Unicode hex values is to create a regular string and then coerce it to a Unicode string (while paying attention to byte order).
char foo[4] = 0x40,0x40,0x40,0x41;
wchar_t *wfoo = (wchar_t *)foo; - Create generic versions of your data structures.
Type definitions for string or character fields in structure should resolve correctly based on the UNICODE compile-time flag. If you write your own string-handling and character-handling functions, or functions that take strings as parameters, create Unicode versions of them and define generic prototypes for them. - Change your make process.
When you want to build a Unicode version of your application, both the Win32 compile-time flag -DUNICODE and the C run-time compile-time flag -D_UNICODE must be defined. - Adjust pointer arithmetic.
Subtracting char* values yields an answer in terms of bytes; subtracting wchar_t values yields an answer in terms of 16-bit chunks. When determining the number of bytes (for example, when allocating memory), multiply by sizeof(TCHAR). When determining the number of characters from the number of bytes, divide by sizeof(TCHAR). You can also create macros for these two operations, if you prefer. C makes sure that the + + and - - operators increment and decrement by the size of the data type. - Check for any code that assumes a character is always 1 byte long.
Code that assumes a character's value is always less than 256 (for example, code that uses a character value as an index into a table of size 256) must be changed. Remember that the ASCII subset of Unicode is fully compatible with 7-bit ASCII, but be smart about where you assume that character will be limited to ASCII. Make sure your definition of NULL is 16 bits long. - Add Unicode-specific code if necessary.
In particular, add code to map data "at the boundary" to and from Unicode using the Win32 functions WideCharToMultiByte and MutliByteToWideChar, or using the C run-time functions mbtowc, mbstowcs, wctomb, and wcstombs. Boundary refers to systems such as Windows 95, to old files, or to output calls, all of which might expect or provide non-Unicode encoded characters. - Add code to support special Unicode characters.
These include Unicode character in the compatibility zone, character in the private-use zone, combining characters, and character with directionality. Other special characters include the private-use-zone non-character U+FFFF, which can be used as a sentinel, and the byte order marks U+FEFF and U+FFFE, which can serve as flags that indicate a file is stored as Unicode. The byte order marks are used to indicate whether a text stream is little-Endian or big-Endian - that is, whether the high-order byte is stored first or last. In plaintext, the line separator U+2028 marks an unconditional end of line. Inserting a paragraph separator, U+2029, between paragraphs makes it easier to lay out text at different line widths. - Determine how using Unicode will affect file I/O.
If your application will exist in both Unicode and non-Unicode variations, you'll need to consider whether you want them to share a file format. Standardizing on an 8-bit character set data file will take away some of the benefits of having a Unicode application. Having different file formats and adding a conversion layer so each version can read the other's files is another alternative. Even if you choose a Unicode file format, you might have to support reading in old non-Unicode files or saving files in non-Unicode format for backward compatibility. Also, make sure to use the correct printf-style format specifiers for Visual C++, shown here:Specifier printf Expects wprintf expects
%s SBCS or MBCS Unicode
%S Unicode SBCS or MBCS
%hs SBCS or MBCS SBCS or MBCS
%ls Unicode Unicode - Double-check the way in which you retrieve command line arguments.
Use the function GetCommandLine rather than the lpCmdLine parameter (an ANSI string) that is passed to WinMain. WinMain cannot accept Unicode input because it is called before a window class is registered. - Debug your port by enabling your compiler's type-checking.
Do this (using W3 on Microsoft compilers) with and without the UNICODE flag defined. Some warnings that you might be able to ignore in the ANSI world will cause problems with Unicode. If your original code compiles cleanly with type-checking turned on, it will be easier to port. The warnings will help you make sure that you are not passing the wrong data type to code that expects wide-character data types. Use the Win32 NLSAPI or equivalent C run-time calls to get character typing and sorting information. Don't try to write your own logic - your application will end up carrying very large tables!
For samples on Unicode-enabled programming, UCONVERT shows character conversion using the system's *.nls tables, and GRIDFONT shows how font enumeration and display needs to keep track of character encoding.