sitinspring(如坐春风)原创,转载请注明作者及出处.
要使用dom4j读写XML文档,需要先下载dom4j包,dom4j官方网站在 http://www.dom4j.org/
目前最新dom4j包下载地址:http://nchc.dl.sourceforge.net/sourceforge/dom4j/dom4j-1.6.1.zip
解开后有两个包,仅操作XML文档的话把dom4j-1.6.1.jar加入工程就可以了,如果需要使用XPath的话还需要加入包jaxen-1.1-beta-7.jar.
点击打开链接另一个介绍的比较全面的文章:http://www.360doc.com/content/08/0102/17/21290_941394.shtml
以下是相关操作:
一.Document对象相关
1.读取XML文件,获得document对象.
 SAXReader reader
=
new
SAXReader();
SAXReader reader
=
new
SAXReader();
Document document
=
reader.read(
new
File(
"
input.xml
"
));
2.解析XML形式的文本,得到document对象.
String text
=
"
<members></members>
"
;
Document document
=
DocumentHelper.parseText(text);
3.主动创建document对象.
Document document
=
DocumentHelper.createDocument();
Element root
=
document.addElement(
"
members
"
);
//
创建根节点
二.节点相关
1.获取文档的根节点.
Element rootElm
=
document.getRootElement();
2.取得某节点的单个子节点.
Element memberElm
=
root.element(
"
member
"
);
//
"member"是节点名
3.取得节点的文字
String text
=
memberElm.getText();
也可以用:
String text
=
root.elementText(
"
name
"
);
这个是取得根节点下的name字节点的文字.
4.取得某节点下名为"member"的所有字节点并进行遍历.
List nodes
=
rootElm.elements(
"
member
"
);
 for
(Iterator it
=
nodes.iterator(); it.hasNext();)
{
for
(Iterator it
=
nodes.iterator(); it.hasNext();)
{
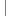 Element elm = (Element) it.next();
Element elm = (Element) it.next();
// do something
 }
}
5.对某节点下的所有子节点进行遍历.
for
(Iterator it
=
root.elementIterator();it.hasNext();)
{
Element element = (Element) it.next();
// do something
}
6.在某节点下添加子节点.
Element ageElm
=
newMemberElm.addElement(
"
age
"
);
7.设置节点文字.
ageElm.setText(
"
29
"
);
8.删除某节点.
parentElm.remove(childElm);
//
childElm是待删除的节点,parentElm是其父节点
9.添加一个CDATA节点.
Element contentElm
=
infoElm.addElement(
"
content
"
);
contentElm.addCDATA(diary.getContent());
三.属性相关.
1.取得某节点下的某属性
Element root
=
document.getRootElement();
Attribute attribute
=
root.attribute(
"
size
"
);
//
属性名name
2.取得属性的文字
String text
=
attribute.getText();
也可以用:
String text2
=
root.element(
"
name
"
).attributeValue(
"
firstname
"
);
这个是取得根节点下name字节点的属性firstname的值.
3.遍历某节点的所有属性
Element root
=
document.getRootElement();
for
(Iterator it
=
root.attributeIterator();it.hasNext();)
{
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
4.设置某节点的属性和文字.
newMemberElm.addAttribute(
"
name
"
,
"
sitinspring
"
);
5.设置属性的文字
Attribute attribute
=
root.attribute(
"
name
"
);
attribute.setText(
"
sitinspring
"
);
6.删除某属性
Attribute attribute
=
root.attribute(
"
size
"
);
//
属性名name
root.remove(attribute);
四.将文档写入XML文件.
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer
=
new
XMLWriter(
new
FileWriter(
"
output.xml
"
));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format
=
OutputFormat.createPrettyPrint();
format.setEncoding(
"
GBK
"
);
//
指定XML编码
XMLWriter writer
=
new
XMLWriter(
new
FileWriter(
"
output.xml
"
),format);
writer.write(document);
writer.close();
五.字符串与XML的转换
1.将字符串转化为XML
String text
=
"
<members> <member>sitinspring</member> </members>
"
;
Document document
=
DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader
=
new
SAXReader();
Document document
=
reader.read(
new
File(
"
input.xml
"
));
Element root
=
document.getRootElement();
String docXmlText
=
document.asXML();
String rootXmlText
=
root.asXML();
Element memberElm
=
root.element(
"
member
"
);
String memberXmlText
=
memberElm.asXML();
六.使用XPath快速找到节点.
读取的XML文档示例
<?
xml version="1.0" encoding="UTF-8"
?>
<
projectDescription
>
<
name
>
MemberManagement
</
name
>
<
comment
></
comment
>
<
projects
>
<
project
>
PRJ1
</
project
>
<
project
>
PRJ2
</
project
>
<
project
>
PRJ3
</
project
>
<
project
>
PRJ4
</
project
>
</
projects
>
<
buildSpec
>
<
buildCommand
>
<
name
>
org.eclipse.jdt.core.javabuilder
</
name
>
<
arguments
>
</
arguments
>
</
buildCommand
>
</
buildSpec
>
<
natures
>
<
nature
>
org.eclipse.jdt.core.javanature
</
nature
>
</
natures
>
</
projectDescription
>
使用XPath快速找到节点project.
public
static
void
main(String[] args)
{
SAXReader reader = new SAXReader();
 try{
try{
Document doc = reader.read(new File("sample.xml"));
List projects=doc.selectNodes("/projectDescription/projects/project");
Iterator it=projects.iterator();
while(it.hasNext()){
Element elm=(Element)it.next();
System.out.println(elm.getText());
 }
}
}
catch(Exception ex){
ex.printStackTrace();
}
}