在将日志文本解析成结构化数据时时,常会遇到记录由数量不定的多行组成的情况。这种变换存在一定的复杂性,实现复杂度较高。集算器支持正则表达式、字串拆分、隔行取数、横向拼接等灵活的结构化计算函数,适合处理此类文本。下面通过例子来看一下具体作法。
日志文件reportXXX.log存储着若干记录,每条记录由多行构成,包括14个数据项(字段)。记录以字符串“Object Type”开头。我们的目标是把该日志整理为结构化数据,并将结果写入文本文件。部分源数据如下:

集算器代码:
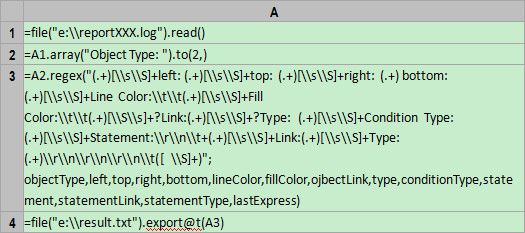
A1=file("e:\\reportXXX.log").read()
这句代码用来将日志文件全部读入内存,结算结果如下:
![]()
A2=A1.array("Object Type: ").to(2,)
这句代码可以分解为两部分。第一部分:将A1按照”Object Type”分割为多个字符串,代码为A1.array("Object Type: "),计算结果如下:
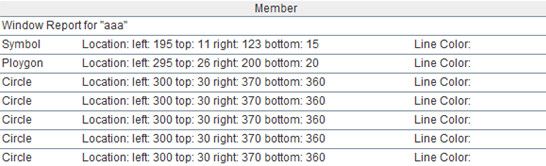
第一条数据无用,之后的每条数据都是一条有效记录,to(2,)表示取出第二条直至最后一条数据。A2的计算结果如下:
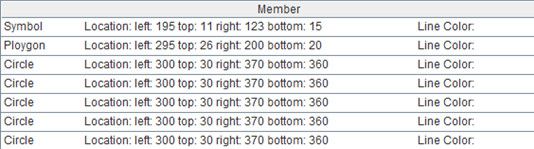
A3= regex(正则表达式;字段名列表),这句代码对A3中的每个成员应用同样的正则表达式,并取出14个字段,字段名以逗号分割。下面列出计算结果中的前几个字段:
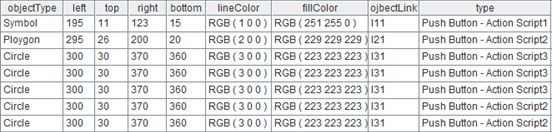
A4=file("e:\\result.txt").export@t(A3)
上面的代码用来将计算结果写入文件,默认的分割符是tab,选项@t表示将字段名做为文件的第一行。打开result.txt,可以看到下面的数据:

上面代码的正则表达式有些复杂难懂,如果想更直观地解决问题,也可以使用集算器的内置函数。比如:ObjectType字段其实是每条记录的第一行,因此可以先将每条记录按照换行符分,再取第一行。再比如left\top\right\bottom其实是将每条记录的第2行按照空格分割,分别取出第3、5、7、9项。
下面用集算器内置函数来解决本案例:

上述代码中,函数pjoin可将多个集合横向拼接起来,函数array可将字符串按指定分隔符分成多段,并形成一个集合,其中(~.array("\r\n")表示对每条记录按照回车换行拆分。
在前面的案例中,我们假设文件比较小,可以全部读入内存计算,但有时日志文件太大,必须分批读取,分批解析,分批写入文件,开发难度因此会显著提高。由于记录的行数不定,一批数据中总会出现半条记录的情况,处理起来会更加复杂。
集算器支持文件游标,适合处理这类不定行的大日志,代码如下:
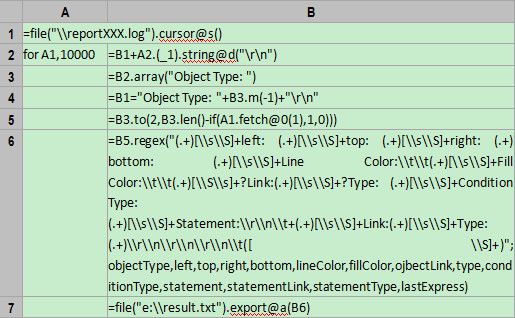
A1=file("\\reportXXX.log").cursor@s()
这句代码以游标的方式打开日志文件。函数cursor表示根据文件对象返回游标对象,默认分隔符是tab,默认列名是_1,_2…_n。选项@s表示忽略分割符并将文件内容读成单列字符串,列名是_1。值得注意的是,这句代码只是建立游标对象,并没有读入数据,实际的读入动作会在遇到语句for或函数fetch时触发。
A2: for A1,10000
A2是个循环语句,表示每次从A1读入一批数据(10000行)并送入循环体,直到日志末尾。可以看到,集算器使用直观的缩进来表示循环体,而不是括号或begin/end等标识符。B3-B7就是A2的循环体,其处理过程是:将当前批次的数据按照回车换行符还原成文本,再按照“Object Type:”重新拆分成记录,将最后一条不完整的部分存储在临时变量B1中,并删除第一条和最后一条无用的记录,对剩下的每条记录进行正则表达式解析,形成的二维表追加到文件result.txt中。下面看详细说明:
B2=B1+A2.(_1).string@d("\r\n")
这句代码将临时变量B1和当前批次的文本拼在一起。第一次循环时B1为空,以后每次循环时B1会存储上个批次的半条记录,B1和当前批次的文本拼在一起,就会使半条记录变完整。
函数string可以把集合成员按照指定的分割符拼成一个大字符串,选项@d表示不在成员的两边加引号。比如第一次循环时,A2的前几行为:
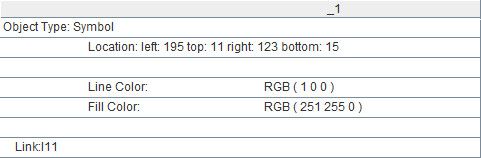
A2.(_1)表示A2的字段_1形成的集合,即:
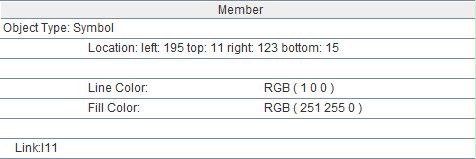
A2.(_1).string@d("\r\n")表示将上述集合拼成一个大字符串,即:Object Type: Symbol Location: left: 195 top: 11 right: 123 bottom: 15 Line Color: RGB ( 1 0 0 ) Fill Color: RGB ( 251 255 0 ) Link:l11….
B3=B2.array("Object Type: ")
这句代码将B2中的大文本按照“Object Type”分割为多个字符串。B3在第一次循环时计算结果如下:

由于B3中的最后一个字符串往往只有记录的一部分,无法参与完整计算,应该将它存在临时变量中,下次循环时再把它和新批次的字符串拼在一起。B4中的代码可以将该字符串存入临时变量B1。
B4=B1="Object Type: "+B3.m(-1)+"\r\n"
函数m表示正向或逆向取集合中的成员,取第一个可以写作m(1),取前三个写作m([1,2,3]),倒数第一个写作m(-1)。也可以直接用B3(1)来正向取第一个成员。另外,前面字符串拆分时已经去掉了每条记录开头的“Object Type”,所以这里要恢复原样。从cursor按行读文件时会去掉回车换行,这里补一个“\r\n”。
B3的第一个成员是空行,最后一个成员是半条记录,这两行都无法参与计算,可以使用下面的代码删除这两个成员:
B5=B3.to(2,B3.len()-if(A1.fetch@0(1),1,0)))
这句代码用来取出B3中的有效数据。如果当前批次不是最后一批,则第一条是空记录,最后一条是半条记录,应当取出第二条直至倒数第二条。如果当前批次是最后一批,则第一条是空记录,最后一条是完整记录,应当取出第二条直至最后一条。
函数B3.to(m,n)表示取出B3中序号在m和n之间的记录。B3.len()表示B3的记录数,相当于当前批次最后一条记录的序号。A1.fetch(n)表示取出游标A1中的n条行,选项@0表示只查看数据,游标位置并不移动。函数if有三个参数,分别是布尔表达式、表达式为true时返回的结果、表达式为false返回的结果。当前批次不是最后一批时,A1.fetch@0(1)为有效记录,函数if返回1;当前批次是最后一批时,A1.fetch@0(1)为空,函数if返回0。
B6=B5.regex(正则表达式;字段名列表),这句代码对B5中的每个成员应用同样的正则表达式,并取出14个字段,字段名以逗号分割。下面列出计算结果中的前几个字段:

B7=file("e:\\result.txt").export@a(B6)
这句代码将B6追加到result.txt中,每次循环追加一批记录,直到日志结尾。打开大文件result.txt可以看到本案例的最终计算结果:

上述算法中在循环中进行正则表达式解析,但正则表达式的编译性能较差,尽量不要在循环中使用,这时可以使用两个集算器脚本配合函数pcursor来实现流式分拆和解析。
首先是主程序main.dfx,代码如下:
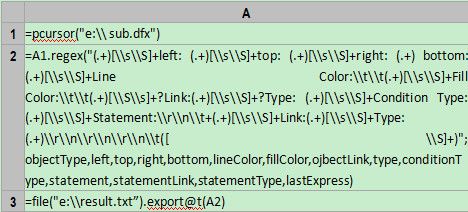
函数pcursor调用了一个子程序,用来返回单列记录形成的游标。A2格对A1中的每条记录进行正则表达式解析,返回结构化数据。注意:A2的计算结果是游标,而不是内存中的数据,执行函数export时,游标A2才会被分批读入内存并进行计算,而这个分批的动作是自动完成的。
子程序sub.dfx的作用是返回游标,写法和前面的案例类似,不同之处是:无需写文件,直接返回单列记录,如下:
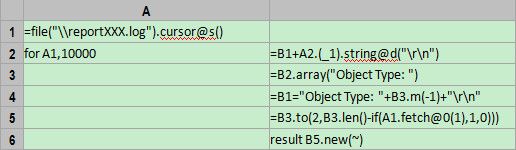
B6中的result可以将B5转为单列序表,并以游标的形式返回给调用者(main.dfx中的函数pcursor)。
通过函数pcursor,主程序main.dfx可以将子程序sub.dfx当做普通游标来取数,而不用管数据的生成过程。Main.dfx需要数据的时候,pcursor函数会根据缓冲区剩余的数据来判断是否继续执行sub.dfx中的循环,或是从缓冲区直接返回数据,整个过程自动完成。