转载请出自出处:http://eksliang.iteye.com/blog/2107002
http://eksliang.iteye.com/
概述:
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
安装zookeeper
上面也说了 SolrCloud是基于Solr和Zookeeper的分布式搜索方案,所有要部署solrCloud+tomcat+zookeeper的集群,必须先安装zookeeper
安装环境:
Liux: CentOS release 6.4
JDK:1.7.0_55
因为我研究的是solr最新的版本,所以研究的是solr4.8.0然后solr4.8.0必须跑在jdk1.7以上的版本
1、zookeeper是个什么玩意?
答:顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)的管理员, Apache Hbase和 Apache Solr 的分布式集群都用到了zookeeper;Zookeeper:是一个分布式的、开源的程序协调服务,是hadoop项目下的一个子项目;
2、zookeeper伪集群安装
因为我演示的这套安装是单机版的安装,所以采用伪集群的方式进行安装,如果是真正的生成环境,将伪集群的ip改下就可以了,步骤是一样的,学会了伪集群安装,真正生产的多环境安装不会,那是不可能的一件事情。
第一步:下载最新的zooper软件:http://www.apache.org/dyn/closer.cgi/zookeeper/
第二步:为了测试真实我在我linux上面部署三个zookeeper服务
创建zookeeper的安装目录 [root@localhost solrCloud]# mkdir /usr/solrcould
将下载的zookeeper-3.3.6.tar.gz复制到该目录下,同时在/usr/solrcould目录下新建三个文件夹:如下所示:
[root@localhost solrcoulud]# ls service1 service2 servive3 zookeeper-3.3.6.tar.gz
然后在每个文件夹里面解压一个zookeeper的下载包,并且还建了几个文件夹,总体结构如下:
[root@localhost service1]# ls data datalog logs zookeeper-3.3.6
首先进入data目录,创建一个myid的文件,里面写入一个数字,比如我这个是server1,那么就写一个 1,server2对应myid文件就写入2,server3对应myid文件就写个3然后进入zookeeper/conf目录,如果是刚下过来,会有3个文件,configuration.xml, log4j.properties,zoo_sample.cfg,我们首先要做的就是在这个目录下创建一个zoo.cfg的配置文件,当然你可以把zoo_sample.cfg文件改成zoo.cfg,配置的内容如下所示:
service1 的zoo.cfg:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=5 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=2 # the directory where the snapshot is stored. dataDir=/usr/solrcould/service1/data dataLogDir=/usr/solrcould/service1/datalog # the port at which the clients will connect clientPort=2181 server.1=192.168.238.133:2888:3888 server.2=192.168.238.133:2889:3889 server.3=192.168.238.133:2890:3890
service2 的zoo.cfg:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=5 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=2 # the directory where the snapshot is stored. dataDir=/usr/solrcould/service2/data dataLogDir=/usr/solrcould/service2/datalog # the port at which the clients will connect clientPort=2182 server.1=192.168.238.133:2888:3888 server.2=192.168.238.133:2889:3889 server.3=192.168.238.133:2890:3890
service3 的zoo.cfg:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=5 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=2 # the directory where the snapshot is stored. dataDir=/usr/solrcould/service3/data dataLogDir=/usr/solrcould/service3/datalog # the port at which the clients will connect clientPort=2183 server.1=192.168.238.133:2888:3888 server.2=192.168.238.133:2889:3889 server.3=192.168.238.133:2890:3890
参数说明:
tickTime:zookeeper中使用的基本时间单位, 毫秒值.
initLimit: zookeeper集群中的包含多台server, 其中一台为leader, 集群中其余的server为follower。 initLimit参数配置初始化连接时, follower和leader之间的最长心跳时间. 此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000=10000ms=10s.
syncLimit: 该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度. 此时该参数设置为2, 说明时间限制为2倍tickTime, 即4000ms.
dataDir: 数据存放目录. 可以是任意目录.但是我喜欢这么干
dataLogDir: log目录, 同样可以是任意目录. 如果没有设置该参数, 将使用和dataDir相同的设置
clientPort: 监听client连接的端口号.
server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口. 由于配置的是伪集群模式, 所以各个server的B, C参数必须不同.
配置说明:
需要注意的是clientPort这个端口如果你是在1台机器上部署多个server,那么每台机器都要不同的clientPort,比如我server1是2181,server2是2182,server3是2183,dataDir和dataLogDir也需要区分下。
最后几行唯一需要注意的地方就是 server.X 这个数字就是对应 data/myid中的数字。你在3个server的myid文件中分别写入了1,2,3,那么每个server中的zoo.cfg都配server.1,server.2,server.3就OK了。因为在同一台机器上,后面连着的2个端口3个server都不要一样,否则端口冲突,其中第一个端口用来集群成员的信息交换,第二个端口是在leader挂掉时专门用来进行选举leader所用。
到这里zookeeper的配置就这么配玩了,你没有看错,就是这么简单!
第四步:当然是启动zookeeper
进入zookeeper-3.3.2/bin 目录中,./zkServer.sh start启动一个server,这时会报大量错误?其实没什么关系,因为现在集群只起了1台server,zookeeper服务器端起来会根据zoo.cfg的服务器列表发起选举leader的请求,因为连不上其他机器而报错,那么当我们起第二个zookeeper实例后,leader将会被选出,从而一致性服务开始可以使用,这是因为3台机器只要有2台可用就可以选出leader并且对外提供服务(2n+1台机器,可以容n台机器挂掉)。
[root@bogon bin]# sh zkServer.sh start #启动 JMX enabled by default Using config: /usr/solrcould/service3/zookeeper-3.3.6/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@bogon bin]# sh zkServer.sh status #查看当前状态,他会报异常,不要紧,因为是集群,其他两台没有起来,无法进行相互连接,当然报错,启动另外两台就不会报错了! JMX enabled by default Using config: /usr/solrcould/service3/zookeeper-3.3.6/bin/../conf/zoo.cfg Error contacting service. It is probably not running
进入不同的zookeeper的bin,分别启动,常用命令如下
启动ZK服务: sh zkServer.sh start 查看ZK服务状态: sh zkServer.sh status 停止ZK服务: sh zkServer.sh stop 重启ZK服务: sh zkServer.sh restart
3、补充单机配置,和实际集群配置
单机部署:进入zookeeper/conf目录,如果是刚下过来,会有3个文件,configuration.xml, log4j.properties,zoo_sample.cfg,这3个文件我们首先要做的就是在这个目录下创建一个zoo.cfg的配置文件,当然你可以把zoo_sample.cfg文件改成zoo.cfg,配置的内容如下所示:
tickTime=2000 dataDir=/Users/apple/zookeeper/data dataLogDir=/Users/apple/zookeeper/logs clientPort=4180
进入zookeeper-3.3.2/bin 目录中,./zkServer.sh start启动,单机便完成安装
实际集群部署:集群模式的配置和伪集群基本一致,由于集群模式下, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样.
下面是一个示例:
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/home/zookeeper/data dataLogDir=/home/zookeeper/datalog clientPort=4180 server.43=10.1.39.43:2888:3888 server.47=10.1.39.47:2888:3888 server.48=10.1.39.48:2888:3888 需要注意的是, 各server的dataDir目录下的myid文件中的数字必须不同.
solr集群部署
我的理解,其实安装solrCloud非常的简单,就是先安装zookeeper然后安装solr 最后将zookeeper和tomcat进行关联就ok了,如此的简单。
第一步:准备软件
Jdk、tomcat这些安装在我的文档里面是省略的,如果这两个东西都不会安装,你来安装solr集群,那就是非常扯淡的一件事情
再次提醒,如果是solr4.8或者以上的版本,记得把jdk升级到1.7以上,否则tomcat起不来。
第二步:在tomcat部署solr,可以参考我的另外一篇博客地址如下:
http://eksliang.iteye.com/blog/2096478,参考上面的企业级安装
你可以参考下我的目录结构
[root@bogon solrcould]# ls service1 service2 service3 tomcat1 tomcat2 tomcat3 tomcat4
这一步就是简单的在4个tomcat上面部署solr,没有做其他任何操作,因为是在同一台机子上面的部署,请记得修改tomcat的端口号。
第三步:配置zookeeper和各个tomcat进行关联
修改solr的所在tomcat所在服务器,在${tomcat_home}/bin/目录下修改catalina.sh
在第一行添加:
这是我的实例:
tomcat1:配置如下:
JAVA_OPTS="$JAVA_OPTS -DzkHost=192.168.238.133:2181,192.168.238.133:2182,192.168.238.133:2183 -Dbootstrap_confdir=/usr/solrcould/tomcat1/display/solrhome/collection1/conf -Dcollection.configName=myconf -DnumShards=3"
其他tomcat:配置如下:
JAVA_OPTS="$JAVA_OPTS -DzkHost=192.168.238.133:2181,192.168.238.133:2182,192.168.238.133:2183 -DnumShards=3"
参数说明:
-DzkRun 在Solr中启动一个内嵌的zooKeeper服务器,该服务会管理集群的相关配置。单机版(测试)使用,如果是集群,用下面的-DzkHost来替换,含义一样
例如:
JAVA_OPTS="$JAVA_OPTS -DzkRun -Dbootstrap_conf=true -DnumShards=2"
-DzkHost 跟上面参数的含义一样,允许配置一个ip和端口来指定用那个zookeeper服务器进行协调
例如:
JAVA_OPTS = "$JAVA_OPTS -DzkHost=192.168.56.11:2181,192.168.56.12:2181,192.168.56.13:2181 -Dbootstrap_conf=true -DnumShards=2"
-Dbootstrap_confdir :zooKeeper需要准备一份集群配置的副本,所以这个参数是告诉SolrCloud这些 配置是放在哪里。同时作为整个集群共用的配置文件
-Dcollection.configName 是在指定你的配置文件上传到zookeeper后的名字,建议和你所上传的核心名字一致,这样容易识别,当然你也可以在满足规范的情况下自己起名。
-bootstrap_conf=true将会上传solr/home里面的所有数据到zookeeper的home/data目录,也就是所有的core将被集群管理
-DnumShards=2 配置你要把你的数据分开到多少个shard中
-Djetty.port =8080 这个端口跟你所在端口保持一致,这个就是jetty的监听端口,实现集群之间进行通信的,如果这个端口不这样配置,那么就是搜索不到数据
当然这个参数也可以再solr/home/solr.xml下面配置:如下所示
<solrcloud>
<str name="host">${host:}</str>
<int name="hostPort">${jetty.port:8080}</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
默认是8983,如果在catalina.sh中指定了,会覆盖上图solr.xml中配置的
注意:
-DnumShards, -Dbootstrap_confdir和-Dcollection.configName参数只需要在第一次将Solr运行在SolrCloud模式的时候声明一次。它们可以把你的配置加载到 zooKeeper中;如果你在日后重新声明了这些参数重新运行了一次,将会重新加载你的配置,这样你在原来配置上所做的一些修改操作可能会被覆盖。所以官方推荐只在第一个tomcat里面加入这几个参数,其他集群的tomcat里面不加,启动的第一个Solr的端口号,它是你的SolrCloud集群的overseer节点
第四步:修改jetty的监听端口
修改solr.xml,该文件在你部署solr时自己定的工作目录,例如我的配置在如下地址:
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>usr/solrcould/tomcat4/display/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
改动如下:
<int name="hostPort">${jetty.port:8983}</int>
改为跟你所在tomcat的端口改成一样
<int name="hostPort">${jetty.port:8080}</int>
这个端口的作用:-Djetty.port =8080 这个端口跟你所在端口保持一致,这个就是jetty的监听端口,实现集群之间进行通信的,如果这个端口不这样配置,那么就是搜索不到数据
然后依次启动tomcat
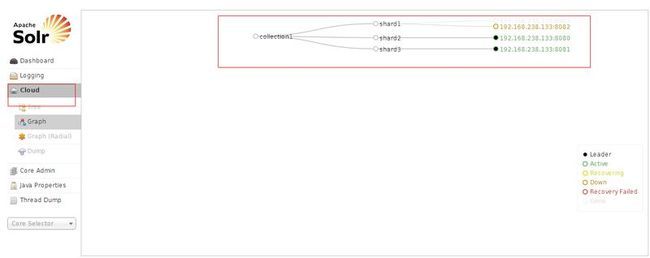
看到了没有,这就是启动了,一个有三个节点的集群
参考文献:
--官网实例
http://wiki.apache.org/solr/SolrCloud/
--官网的文档翻译
http://my.oschina.net/zengjie/blog/197960#OSC_h2_1
http://www.cnblogs.com/phinecos/archive/2012/02/10/2345634.html
http://phinecos.cnblogs.com/
--Zookeeper参考
http://www.blogjava.net/BucketLi/archive/2010/12/21/341268.html