JPA即Java Persistence Architecture,Java持久化规范,从EJB2.x版本中原来的实体Bean分离出来的,EJB3.x中不再有实体Bean,而是将实体Bean放到JPA中来实现。可以说,JPA借鉴了Hibernate的设计,JPA的设计者就是Hibernate框架的作者。
JPA的底层实现是一些流行的ORM框架,比如Hibernate,EclipseLink,OpenJPA等实现方式。
(参考
http://blog.javachen.com/2014/12/02/some-usages-of-jpa/,并根据实际使用进行了总结)
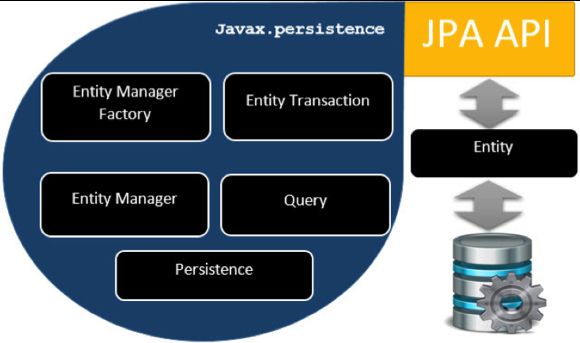
EntityManagerFactory作为EntityManager的工厂类,创建并管理多个EntityManager实例;EntityManager接口管理持久化操作的对象,其中包含了对实体(Entity,存储在数据库中的记录对象表示)的所有增删改查操作。

EntityManagerFactory是一个spi实现的工厂类,可以创建多个不同的EntityManager;每个EntityManager中只有一个EntityTransaction实例,但可以创建多个不同的Query实例,并执行查询,管理多个Entity实体。
JPA中比较核心的配置文件是persistence.xml文件,基本样式如下:
<?xml version="1.0"?> <persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd" version="1.0"> <persistence-unit name="hsqldb-unit" transaction-type="RESOURCE_LOCAL"> <provider>org.hibernate.ejb.HibernatePersistence</provider> <properties> <property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect"/> <property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver"/> <property name="hibernate.connection.username" value="sa"/> <property name="hibernate.connection.password" value=""/> <property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost/test"/> <property name="hibernate.max_fetch_depth" value="3"/> <property name="hibernate.hbm2ddl.auto" value="update"/> <property name="hibernate.jdbc.fetch_size" value="18"/> <property name="hibernate.jdbc.batch_size" value="10"/> <property name="hibernate.show_sql" value="true"/> <property name="hibernate.format_sql" value="true"/> </properties> </persistence-unit> </persistence>
本例程中使用了Hibernate3.6作为JPA的实现,并以hsqldb作为测试数据库进行配置,在使用Spring容器的场景下通过下面的配置方式进行设置:
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="jpaVendorAdapter" ref="hibernateJpaVendorAdaptor"/> <property name="packagesToScan" value="xxx"/> <property name="loadTimeWeaver"> <bean class="org.springframework.instrument.classloading.InstrumentationLoadTimeWeaver"/> </property> <property name="persistenceXmlLocation" value="/WEB-INF/config/persistence.xml"/> </bean> <bean id="hibernateJpaVendorAdaptor" class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"> <property name="databasePlatform" value="org.hibernate.dialect.H2Dialect"/> </bean> <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> <property name="entityManagerFactory" ref="entityManagerFactory"/> </bean>
JPA的持久化映射的数据表
作为ORM框架,肯定是有一套对应Java对象实体到关系数据库映射的工具。在Hibernate诞生之初使用的是.hibernate.xml配置文件的方式,而最近通过注解工具的发展(Annotation,@),已经可以通过更便于管理的方式定义这种关系(当然还可以采取更加灵活的注解+配置文件的混合方式)。
使用@Entity来标识一个持久化对象,所有对应数据库表的持久化对象都必须声明该注解,并可以定义name字段的名称来自定义数据表的内容。
使用@Id来标识主键,持久化对象必须含有主键,主键一般使用与业务无关的自增/随机字段来表示(不建议使用联合主键的方式),以获得更好的扩展性。
可以使用@GenerateValue方式来声明主键自动生成的策略,有下面四种方式:
- GenerationType.TABLE:使用独立表来记录主键,适用于各种数据库,但性能会差一些,因其每次进行insert时都会额外发出一次主键查询;
- GenerationType.SEQUENCE:只适用于oracle数据库;
- GenerationType.IDENTITY:适用于Sqlserver等数据库;
- GenerationType.AUTO:由JPA实现来探测底层使用的数据库,自动采取一种主键自增的策略,可以指定生成器。如对Oracle采用SEQUENCE策略,对Sqlserver采用IDENTITY策略。AUTO策略支持目前绝大多数已知的数据库,这是默认的策略也是我们目前采用的策略。
如果使用AUTO,最好将主键字段设置为long(int也可以);如果设置为generator=uuid,那么主键字段类型使用String;如果不设置@GenerationType,那么应用程序中需要指定主键。
在@Entity对象中定义的所有成员变量,都会映射到数据表中(默认名称即为该字段的名称),可以使用@Column注解显示地将该成员变量定义为数据表字段,并通过name字段显示地指定该字段的名称;也可以使用@Transient来标识该成员变量为非数据库字段;
此外,static(不属于具体的对象实例)或final(不能更改其引用)字段由于其特殊性,并不能作为数据库字段。
如果字段需要使用Java中的枚举类型,可以将字段设置为Enum类型,并设置@Enumerated,如果想要将该字段映射为String(枚举表示的String),可以将其value设置为EnumType.String。
对于想要设置为日期Date类型的字段,可以使用@Temporal来标识,可以选择Date,Time,TimeStamp(默认,如果不标识,也默认使用TimeStamp)。
对于大的文本,想要使用数据库中的Clob或Blob字段,那么可以使用@Lob来标识:
- Clob:java.lang.String, java.lang.Character[],java.lang.char[], java.sql.Clob可映射为Clob;
- Blob:java.lang.byte[], java.lang.Byte[], java.sql.Blob及实现了Serializable对象的类可映射为Blob。
数据表之间的关联关系映射
数据表之间的关联关系在JPA中有三种:
@OneToOne
一对一映射分为主键关联和外键关联两种方式,如果使用主键关联,那么从表的的主键同时也是外键,主从表中关联的记录主键完全一致,需要在被维护端使用@PrimaryKeyJoinColumn指定对应的关系,比如下面的例子:
@Entity
public class Husband {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToOne(mappedBy="husband", cascade=CascadeType.ALL)
private Wife wife;
...
}
@Entity
public class Wife {
@Id
private Long id;
private String name;
@OneToOne(cascade=CascadeType.ALL)
@PrimaryKeyJoinColumn
@MapsId
private Husband husband;
}
如果是外键关联,则会使用一个额外的外键字段来建立关联关系,比如下面的例子:
@Entity
public class Car {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToOne(cascade={CascadeType.PERSIST, CascadeType.MERGE}, fetch=FetchType.LAZY) @JoinColumn(name="engine_id")//外键关联字段
private Engine engine;
@Entity
public class Engine {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToOne(mappedBy="engine", fetch=FetchType.LAZY, cascade={CascadeType.PERSIST, CascadeType.MERGE})
private Car car;
}
@OneToMany @ManyToOne
一对多/多对一映射注解,在双向一对多关系中,一端是关系维护端,只能在另一端中添加mapped属性,多端是关系被维护端,建表时在关系被维护端(多的那一端)中建立一个外键指向关系维护端的主键一列。
比如:
@OneToMany(mappedBy = "executableSubTaskDefinition", fetch = FetchType.LAZY) private List<ExecutableSubTaskStatus> executableSubTaskStatusList = new ArrayList<>();
注意,mappedBy即为ExecuteableSubTaskStatus中的@ManyToOne成员变量名称而非数据库字段名称,那么在另一端,
@ManyToOne(cascade = CascadeType.ALL, optional = false) private ExecutableSubTaskDefinition executableSubTaskDefinition;
@ManyToMany
多对多映射是相对来说最为复杂的一种映射关系,会采取中间表连接的映射策略,建立的中间表分别引入两边的主键作为外键,形成两个一对多关系。
在双向的多对多关系中,在关系维护端(owner side)的 @ManyToMany 注解中添加 mappedBy 属性,另一方是关系的被维护端(inverse side),关系的被维护端不能加 mappedBy 属性,建表时,根据两个多端的主键生成一个中间表,中间表的外键是两个多端的主键:
关系维护端——> @ManyToMany(mappedBy="另一方的关系引用属性")
关系被维护端——> @ManyToMany(cascade=CascadeType.ALL ,fetch = FetchType.Lazy)
比如下面的实例:
@ManyToMany @JoinColumn(name = "task_data_range") private List<SubTaskDefinition> subTaskDefinitions = new ArrayList<>();
@ManyToMany(fetch = FetchType.LAZY) @JoinTable(name = "sub_task_data_range", joinColumns = @JoinColumn(name = "sd_task_id", referencedColumnName = "sub_task_definition_id"), inverseJoinColumns = @JoinColumn(name = "sd_data_id", referencedColumnName = "task_data_range_id")) private List<TaskDataRange> taskDataRanges = new ArrayList<>();