--转载自己的文章,原文发表在《程序员》2013年第2期上,感谢《程序员》授权转载
前言:随着移动互联网的兴起以及restful和web service的大规模使用,http协议因其使用方便以及跨平台的特性,在web开发以及SOA领域得到了广泛使用。但其所涵盖的信息,大都是未经加密的明文,信息获取门槛的降低,也为应用架构的安全性及稳定性带来了挑战。
对于常规的web攻击手段,如xss、crsf、sql注入等等,防范措施相对来说也比较容易,比如xss的防范需要转义掉输入的尖括号,防止crsf需要将cookie设置为httponly以及增加session相关的hash token码, sql注入的防范需要将分号转义等等,做起来虽然简单,但却容易被忽视,更多的是需要从开发流程上来予以保障,以免因人为的疏忽而造成损失。
本篇更多的是从平台架构的安全性及稳定性方面着笔,希望能通过些许文字的分析和介绍,来窥探http平台搭建所涉及的一些技术细节,给读者以启发。
协议的安全性
http协议其所涵盖的信息都是未经加密的明文,包括请求参数,返回值,cookie,head等等,因此,外界通过对通信的监听,轻而易举便可模拟出请求和响应双方的格式,伪造请求与响应,修改和窃取各种信息。相对于tcp协议层面的socket传输方式,针对http协议攻击门槛更低。因此,基于http协议的web及SOA架构,在应用的安全性方面,需要更加的重视。
1.摘要签名
对于普通的非敏感数据,我们更多的关注其真实性和准确性,因此,如何在通信过程中保证数据不被篡改,便成为首当其冲需要考虑的问题。鉴于使用https性能上的成本以及需要额外申请CA证书,这种情况下,一般采用参数摘要的方式即能够满足需求。每次请求和响应生成对应的sign,以此来保障请求及响应不被第三方篡改。
请求的参数经过排序,将参数名称和值经过一定的策略组织起来,加上一个密钥secret,然后通过摘要算法生成sign。常见的摘要算法包括MD5、SHA等等,由于摘要算法的不可逆性,以及请求参数值的多变性,能够在一定程度上保证通信的安全性。

图1 签名的构造
服务端接收到请求后,以同样的顺序将参数排序,加上相同的secret,以相同的摘要算法生成签名,然后与请求传过来的sign进行比较,如果参数在中途被篡改,传过来的sign与服务端生成的sign则存在差异,以此来判断请求的合法性。

图2 签名的校验
服务端校验完成后,生成响应,同样的,响应的内容也需要以类似的方式进行签名,客户端收到响应后,根据接收到的sign来验证签名的正确性。
举例来说,某个请求的url可能是这样,www.xxx.com/api.do?userid=12345678&page=1&pagesize=10&signtype=MD5&charset=gbk&method=com.chenkangxian.getname&sign=aef503e0ae7c27b04c2fe1cc95ce1d,userid、page、pagesize是常规参数,signtype表示加密类型,charset表示编码,method表示接口名称,sign为生成的签名串,为了互联网传输方便,一般对其进行16进制或者base64编码,服务端将接收到的参数拼接成字符串userid=12345678&page=1&pagesize=10&signtype=MD5&charset=gbk&method=com.chenkangxian.getname,采用MD5算法生成sign,与传递过来的sign(当然,需16进制或者base64解码)比较,如果一致,表示参数未被篡改。
2.公私钥签名
上述方法能较好的解决数据合法性校验问题,但是secret相对固定,如果多客户端调用,容易导致secret泄露。
因此,可以给每个客户端分配一对公私钥,请求时,客户端将参数按与前面类似的方式排好序,拼成一个字符串,md5后,通过私钥加密,生成sign。

图3 客户端用私钥生成sign
服务端采用同样的方式将参数编排,拼成字符串,md5,通过客户端公钥解密sign,与其md5生成的值进行比较,便可得出数据是否合法。
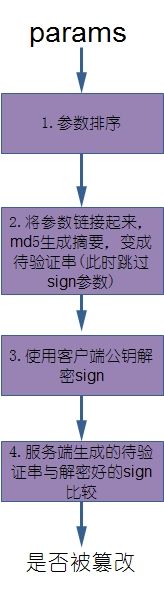
图4 服务端用公钥校验sign
当然,客户端也可以采用相同的方法,使用服务端的公钥,对服务端进行校验,这里就不一一枚举了。
3.https
上面的两种方法能较好解决数据合法性问题,但对于一些较为敏感的信息,如隐私数据,用户名密码等等,这些信息如以明文的形式传递,会带来较大风险,服务端secret或者公私钥相对固定,一旦密钥泄露,也会有很大的安全风险,并且,通信过程中,客户端与服务端的身份,特别是服务端的身份难以得到保障,第三方可以通过域名劫持的方式来伪造身份,欺骗客户端向伪造的服务端发送数据,这样一来,损失将不可估量。因此,有必要采用更加严格的加密手段来保障信息的安全。
依托SSL(Secure Socket Layer)协议,https能够确保整个通信过程加密,密钥随机产生,并且能够通过数字证书验证通信双方的身份,以此来保障信息安全。
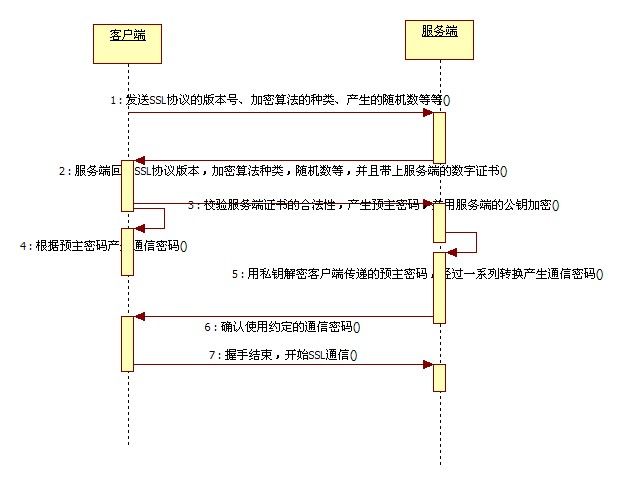
图5 服务端单向身份认证https通信过程
SSL协议握手的过程是这样的,客户端向服务端发送SSL协议的版本号,支持的加密算法类型,产生的随机数以及其他客户端与服务端通信所需要的信息,服务端收到这些信息后,会将它自己的SSL协议版本,支持的加密算法类型,以及产生的随机数等等内容,加上它的数字证书,一起回复给客户端。
证书以证书链的形式组织,客户端会逐级校验证书的合法性,包括服务器域名是否与证书所声明的域名一致,证书是否过期,证书颁发机构是否是可信赖的等等。这个过程对于用户来说一般是透明的,操作系统会内置一些知名的CA机构的根证书,免去用户的安装步骤,开发者或机构只需要向相关的CA机构以付费的方式申请证书即可。当然,也有个别例外的奇葩,如12306,直接将根证书挂在主页上供用户下载。
校验完证书过后,客户端将产生一个预主密码,并用服务端的公钥加密传送给服务端,服务端会根据预主密码来生成通信密码,与此同时,客户端也通过相同的方式生成通信密码,这样,一次通信握手基本完成。
通过SSL协议能够完成对服务端的认证,加密数据,防止在传输过程中信息的泄露和篡改,能够在相当的程度上保障通信的安全性。
4.应用授权
以上的场景其实是在通信双方相对信任的基础下完成的,客户端直接访问服务端完成数据交互。还有一种场景是平台商将数据有限开放给第三方软件厂商(ISV),第三方软件厂商再利用这些数据来给用户提供服务,当然,前提是用户必须对ISV授权。对于平台厂商来说,用户形形色色的需求,很难以一己之力来予以充分满足,因此,将数据以接口的形式下放给众多的第三方开发者,便成了必然的趋势,也正是由此引发了近几年的“开放平台热”。这样,如何保障对用户数据的访问均是经过授权的,且不会对第三方泄露用户的用户名密码,便成了首当其冲的问题。
OAuth协议为用户资源的授权提供了一个安全、开放的标准,与以往的授权方式不同,OAuth不需触及到用户账户信息(用户名密码),即可完成第三方对用户信息访问的授权。
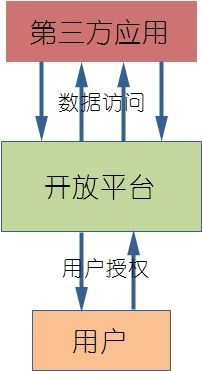
图6 开放应用平台授权
OAuth协议的出现,使得用户在不泄露自己用户名密码的情况下,能够完成对第三方应用的授权,第三方应用得到用户授权后,便可以在一定时间内访问到用户授权的数据。
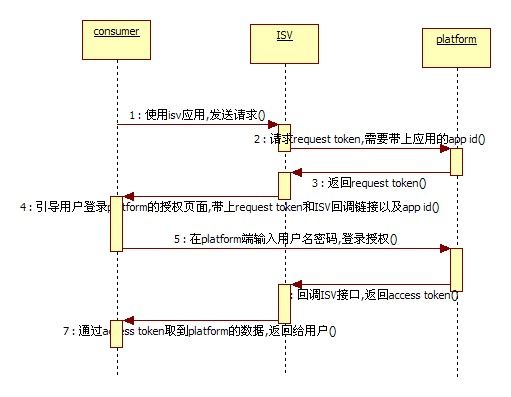
图7 Oauth协议的授权过程
一次OAuth协议的授权过程如上图所示,用户先对ISV发起请求,ISV向平台商请求request token,带上其申请的app id,平台返回request token,其后ISV应用将用户引导到平台的授权页面,带上自己的app id、request token以及回调地址,用户在平台的页面上完成授权(这样便不会将用户名密码泄露给第三方),然后平台通过ISV提供的回调链接,返回给ISV应用access token,ISV应用通过access token取到用户授权的数据,进行加工后返回给用户,授权完成。
为了确保通信安全,一般会让ISV使用其私钥对参数进行签名,平台使用ISV的公钥进行签名验证,来校验ISV的资质,具体过程前面详细介绍过,此处不再赘述。
OAuth协议得到了国内外互联网公司的广泛认可,包括Facebook,Google,Window Live,以及国内的腾讯、新浪、淘宝、人人等,都对其提供了良好的支持。不同的厂商有不同的OAuth版本,但不论是OAuth1还是OAuth2,其核心思想都是将资源做权限分级和隔离,ISV引导用户在平台端登陆,完成授权,获得授权后ISV可以在一定时间段内访问用户的私有数据,用户完全把控这一过程,且授权可取消。这样,第三方ISV能够利用平台商所拥有的一些数据,来服务用户,为用户创造价值,形成了一个生态系统的闭环。
OAuth授权其实是一个相对较复杂的体系,涵盖系统的方方面面,包括之前所说的通信加解密,以及权限划分,token生成和校验,公私钥的管理,还有后面将要提到的分布式session机制等等。相对于前几年来说,由于开源社区的发展,为其的实现降低了不少门槛,目前已有很多开源的解决方案,详情请参照OAuth网站(http://oauth.net)。
session的安全性
对于互联网应用来说,为了应对高并发访问的压力,支撑其业务的往往不止是单台服务器,而是一个分布式集群,http请求在不同的服务器间跳转,这样集群间session的同步便成了不得不考虑的问题。
对于一般web应用来说,采用cookie能解决一部分问题,但随着应用规模的不断扩大,cookie会不断的膨胀,而浏览器对于每个域名下的cookie的个数以及每个cookie的长度会有所限制,不能满足持续性增长的需要,并且,客户端的cookie数据会存在一定的安全性隐患。对于服务端调用来说,请求不经过浏览器,cookie显然无法满足需求,随着移动互联网的发展,基于http的SOA架构还将兼容无线客户端的请求,因此,基于cookie的session同步方案已无法满足需求。
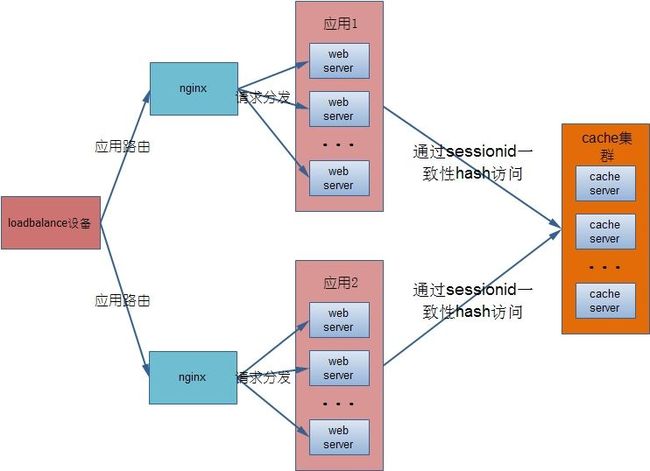
图8 基于cache的分布式session结构
如上图,基于cache的分布式的session同步机制,能较好的解决上述问题。客户端通过login登陆,如果客户端为浏览器,则通过cookie回写的方式,设置sessionid,如果是在移动端或者服务端调用,则直接返回sessionid,这样,不管用户如何跳转,不同的客户端和应用都可以通过sessionid到cache集群中取到session,避免了session丢失。
而使用一致性hash算法,能够确保当某台cache server宕机后,不至于整个的key都重新hash一遍,导致所有的用户都需要重新登录,这样不仅提升了用户体验,也降低了对于login的压力,不会有大量的用户像雪崩一样同时发来大量的登录请求(这对于像淘宝双11双12这样大流量的活动来说,十分重要)。使用cache来存储session会话,即表示会话是可以丢失的,对于系统设计者来说,对这一点须有清楚的认识。
分布式session也会跟普通单机session一样,存在session失效以及cookie防盗用等等问题。
为提高cache的利用率以及提高session的安全性,须针对cache设置一定时长的失效时间,避免在用户在离开位置后session被其他人盗用,但是,对于用户连续性的操作,又必须对session的到期时间进行不断更新,否则,可能会影响到用户的体验。
对于sessionid来说,最好是将其设置为httponly,避免跨站脚本对cookie进行盗用,当然,采用分布式session后,任何人都已经很难从cookie本身提取到有价值的攻击信息,但是,如果通过窃取sessionid来伪造用户登陆,则不得不防,尤其是交易相关的业务,可能会造成相当大的危害,因此,需将session的状态与客户端的ip地址或者mac地址挂钩。如果用户从ip1登陆,通过ip2来访问用户信息,即便ip2访问的时候带上了sessionid,也需要重新进行登陆,这样的话,则相当程度避免了会话劫持的发生。
平台的稳定性
对于生产环境的应用集群来说,故障是很难完全避免的,建立完善的监控预警机制,能够提高遇到问题时的响应速度,帮助快速发现问题,及时通知相关技术人员对故障进行修复,有效的避免或者降低损失。与此同时,也必须做好流量控制,防止突发的大流量将服务器压垮。
1.集群监控
生产环境的情况往往复杂多变,用户的行为不可预测,有效的监控措施不仅能够提高遇到问题时的响应速度,也为应用的扩容,性能的优化提供了参考依据,对我们及时了解应用的水位,评估和设置警戒线提供了十分重要的帮助。
常规的监控可以包括如下方面,机器的load,cpu使用率,内存使用率,网络traffic,pv以及uv信息,IO繁忙程度,磁盘使用率,异常catch等等,如果是java应用,应该包括堆栈的使用情况,fullgc的频率等等,如果是mysql DB,需要包括select/ps,update/ps,thread running等等,这些指标信息能够基本反映机器运行的健康状态。一旦某个指标出现异常,比如受攻击导致流量激增,可以发短信或者邮件通知相关应用负责人,进行及时的处理。
对于采用http协议的应用来说,能做的不仅仅只有这些,还可以采取包括接口数据校验,部分线上回归测试,页面状态检测等等措施,更加全面的对应用进行健康检查和监控。
举例来说,对于异步返回json、jsonp、xml格式数据的接口来说,可以事先造好一部分固定数据,覆盖接口代码的各个分支路径,然后通过shell脚本定时执行(crontab部署定时任务)的方式,验证返回的数据是否完整是否正确,以此完成接口的扫描与检查。
$CURL_BIN -s -m 100 "${HOSTNAME}${URL}" > $TMP_FILE
if [ "$CHECK_TXT" != "" ]; then
check_result=`fgrep $CHECK_TXT $TMP_FILE`
if [[ "$check_result" = "" ]]; then
CHECK_STATUS="1"
echo -e "check failure!\t${URL}\n"
fi
fi
code1 接口检查shell片段
脚本通过curl来请求相关接口url,将返回值与check_txt(预定义文本)通过fgrep比对,如果与预计的不符,则输出check failure,程序检测到该输出,则发送短信报警。
对于页面来说,返回的数据量大,整体校验相对来说代价较大,可以针对一些核心流程,比如接口的调用,后端数据的返回,定义一些状态码,塞到http的header请求头中返回,这样,通过监控header中对应的状态值,来完成页面的监控。
$CURL_BIN -s -I -m 100 "${HOSTNAME}${URL}" > $TMP_FILE
status=` awk -F ":" '{if($1 == "Server_Status"){print $2}}' $TMP_FILE `
status=${status//}
if [ "$status" = "ok" ]; then
CHECK_STATUS="0"
else
CHECK_STATUS="1"
echo -e "check failure!\t$URL\n"
fi
code2 一段页面监控的shell片段
脚本通过curl来访问相关页面,通过awk过滤出header中的Server_Status值(该值在应用端事先约定好),判断其是否为ok状态,如果ok,则忽略,否则,输出check failure,程序检测到该状态,则发送报警短信。
2.并发与流量控制
任何应用都有一个设计指标和能承载的峰值,当它的压力超过了它设计的峰值以后,就好比一座为行人设计的独木桥,即使它再坚固,也无法让一辆坦克行驶通过,在这个时候,为了让机器能够正常运行,不至于完全瘫痪,需要对应用进行流量控制。
控制的策略有多种,可以直接丢弃掉那部分超出峰值的用户请求,这样虽然比较粗暴,但也是最简单最有效的方法,还有一种便是削峰填谷,将一部分暂时来不及处理的请求放入等待队列中,待资源空闲时再逐步消化,具体使用哪种策略,与应用的场景相关。
当然,要进行流控,首先得有一个进行流控阀值,这可不是拍拍脑袋或者仅凭经验就能够得出来的,不同的应用,不同种类的接口,不同的机器配置,其所面临的情况也不尽相同,阀值必定是有差异的,必须经过几轮的压力测试下来,才能够得到一个比较靠谱的值。
流控可以从多个维度来进行,比如针对qps(每秒查询数),并发线程数,黑白名单,服务加权分级等等,最典型最直观的,便是通过对qps或者是并发线程数的控制,来达到限流的目的。
从具体实施的角度来说,可以在应用的负载均衡端(如nginx)完成,这一层可以进行整体的比较粗粒度的控制,比如客户端的并发请求数,请求的频率等等,这样可以过滤掉大部分攻击请求,提高ddos的组织难度,当然,更加复杂的策略,如验证码防刷,黑名单,ip封锁等等,可以通过编写nginx模块来进行定制。
Nginx从0.7版开始提供2个限制用户连接的模块HttpLimitZone Module和HttpLimitReq Module,可以用来限制用户请求的频率和并发连接数:
limit_zone zone_session_state $binary_remote_addr 10m;
limit_req_zone $binary_remote_addr zone=req_session_state:10m rate=1r/s;
location /
{
limit_conn zone_session_state 1;
limit_req zone=req_session_state burst=5 nodelay;
… …
}
code3 nginx配置限流
负载均衡端作为应用总的流量入口,采取的限流措施可以挡掉大部分的恶意流量,但缺乏灵活性,难以响应后端的变化,并且受调度策略的影响,并不能保证落到每一台服务器的流量都是均衡的,因此,一般的策略是将入口阀值适当调高,然后结合应用端协同来进行流控。
应用端流控的好处便是能够更细粒度的划分流控的单位(能精确到接口层面),更加方便的调节流控阀值,动态的修改服务权重、调用的黑白名单,以及进行服务分级,优先保障核心流程的稳定,这在应对大流量高并发的压力 (如淘宝双11,双12)时,显得尤为重要。
关于应用端流控的实施,涉及众多细节,限于篇幅,笔者将在个人博客做详细介绍,此处便不再赘述。
小结
本文从协议的安全性,session的安全性以及平台的稳定性三个方面,介绍了http平台搭建过程中所面临的一些问题以及解决办法。http协议因其明文传输的特性,使得在系统设计阶段,不得不对安全性作充分考量。而对于生产环的境应用来说,完善的监控预警措施,能确保在第一时间发现问题,及时采取恰当的措施,避免损失;合适的流控机制,能保障在流量突增的情况下,机器能顶住压力,不至于宕机。