深究Oracle中的锁之锁的基础架构(原创)
Lock概述
Lock,首先代表一种控制机制,其次在这个机制中有一个成员也叫LOCK
LOCK框架包含三个组件:Resource Structure(资源)、Lock Structure(锁)和Enqueue(排队机制)。Resource和Lock是数据结构,Enqueue是算法。
Resource Structure
Oracle对于每个需要进行“并发控制”的资源,都在SGA中用一个数据结构来描述它,这个数据结构叫做Resource Structure。这个数据结构中的有3个与“并发控制”相关的成员:Onwer,Waiter,Converter。这是3个指针,分别指向3个有 Lock Structure组成的链表。
Lock Structure
每个进程要访问共享资源时,必须要先“锁定”该资源。这个动作实际就是从内存中申请一个Lock Structure,在其中记录”锁模式,进程ID“等重要信息。然后看是否能立即获得访问权,如果不能,则把Lock Structure挂到Resource Structure的Waiter链表中。如果能获得访问权,则把 Lock Structure挂到Resource Structure的 Onwer 链表中。上面说到的 Resource Structure中的 Onwer,Waiter,Converter三个成员就是指向由Lock Structure组成的链表的指针。Lock的组成示意图如下
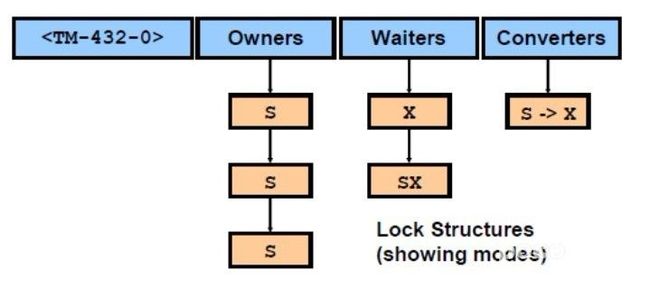
锁模式
Oracle中的对象可以分为两类,简单对象(Simple Objects)和复合对象(Compound Objects)。数据表是典型的复合对象,表中的每条记录是典型的简单对象。对于简单对象只有3中模式:Null、Share、Exclusive。而 对于复合对象,除了 Null、Share、Exclusive这3中模式外,还有 Sub-Shared、Sub-Exclusive、Shared-sub-exclusive 。
Null:模式值为1。不妨碍任何访问,这种模式主要用于数据字典。
Share: 模式值为4。 拥有者本身对资源进行只读访问,允许其他用户并发只读访问。
Exclusive: 模式值为6。 拥有者本身对资源进行修改访问,不允许其他用户任何并发访问
Sub-Shared: 模式值为2。 当需要以Share模式访问复合对象中的成员时,需要对复合对象加这种模式的锁,而对成员加Shared模式的锁;这种模式有不同的缩写(SS,RS,CR)。
Sub-Exclusive: 模式值为3。 当要以Exclusive模式访问复合对象中的成员时,需要对复合模式对象加这种模式的锁,而对成员加Exclusive模式的锁;这种锁模式有不同的缩写(SX,RX,CR)。
Shared-sub-exlusive: 模式值为5。 当需要对复合对象的成员进行Exclusive模式访问,同时要对复合对象本身进行Shared模式访问时,需要对复合对象加这种模式的锁;这种模式的锁有不同的缩写(SSX,SRX,PW)
为什么要引入意向锁
之所以把对象划分成为两种类型,也是从性能角度考虑。
如果在一个数据库管理系统中,同时支持多种锁定粒度供事务选择,这种锁定方法就被称为多粒度锁定(multiple granularity locking)。如下图所示是一个四级的多粒度树。该树的根节点是数据库,表示最大的粒度;页节点是列,表示最小的粒度。
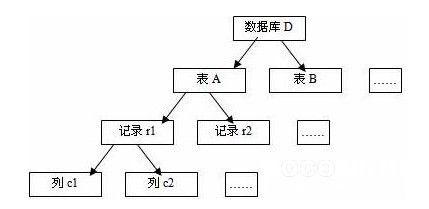
我们知道,选择锁定粒度时应该同时考虑并发度与开销两个因素,以求最优的效果。一般地,需要处理大量记录的事务可以以表为锁定粒度;需要处理多个表中的大量记录的事务可以以数据库为锁定粒度;而只需要处理某个表中少量记录的事务,则可以以记录为锁定粒度。
多粒度锁定协议是指,允许对多粒度树中的节点单独地加锁,另外,对一个节点加锁还意味着对这个节点的各级子节点也加同样的锁。
因此,可以用两种方法对多粒度树中的节点加锁:显式锁定、隐式锁定。显式锁定是在事务中明确指定要加在节点上的锁;隐式锁定是由于在其上级节点中加显式锁时而使该节点获得的锁。
在多粒度锁定中,显式锁定与隐式锁定的作用与相容规则都是一样的。因此,当系统检查锁定的冲突时,不仅要检查显式锁定还要检查隐式锁定。
一般地,当对一个节点加锁时,系统第一要检查在该节点上有无显式锁定与之冲突;第二要检查其所有上级节点有无显式锁定与之冲突,以便查看在该节点上加该显 式锁定,是否会与从上级节点获得的隐式锁定有冲突;第三要检查所有下级节点有无显式锁定与之冲突,以便查看在该节点上加该显式锁定,是否会使下级节点从该 节点获得的隐式锁定与其显式锁定有冲突。
这种检查锁定冲突的方法的效率很低,所以引进了意向锁(Intended lock)的概念。
意向锁
意向锁的含义是,如果对一个节点加某种意向锁,则会对该节点的各级下级节点加这种锁;如果对一个节点加某种锁,则必须先对该节点的各级上级节点加这种意向锁。
例如,对记录r1加锁时,必须先对它所在的表A加意向锁。于是,事务T1对表A加X锁时,系统只需要检查根节点数据库D和表A是否已经加了不相容的锁,而不再需要检查表A中每个记录是否加了X锁。
Oracle中的意向锁就是:Sub-Shared,Sub-Exclusive,Shared-sub-exlusive
Sub-Shared锁---意向共享锁
如果对一个节点加SS锁,则表示对它的所有下级节点有加S锁的意向;如果对一个节点加S锁,则必须先对该节点的各级上级节点加SS锁。
Sub-Exclusive锁---意向排他锁)
如果对一个节点加SX锁,则表示对它的所有下级节点有加X锁的意向;如果对一个节点加X锁,则必须先对该节点的各级上级节点加IX锁。
Shared-sub-exlusive---共享意向排他锁
如果对一个节点加SSX锁,则表示对它加S锁,然后再加SX锁,即SSX=S+SX。例如,如果事务T对表A加SSX锁,则表示事务T要读取整个表(S锁的作用),同时还会更新某些记录(SX锁的作用)。
各种锁之间的相容规则如下图表所示。 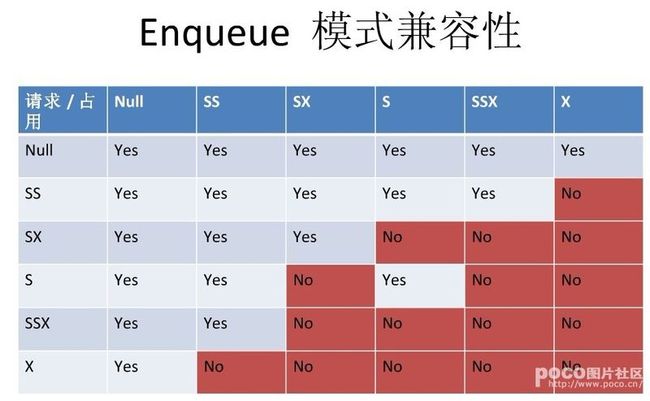
这些不同模式锁的保护能力顺序如下: Highest level X>SSX>SX=S>SS>NULL Lowest level
常见SQL锁加大锁模式如下表
| SQL Statement |
Mode of Table Lock |
| SELECT...FROM table ... |
none |
| INSERT INTO table ... |
RX |
| UPDATE table ... |
RX |
| DELETE FROM table ... |
RX |
| SELECT ... FROM table FOR UPDATE OF ... |
RS |
| LOCK TABLE table IN ROW SHARE MODE |
RS |
| LOCK TABLE table IN ROW EXCLUSIVE MODE |
RX |
| LOCK TABLE table IN SHARE MODE |
S |
| LOCK TABLE table IN SHARE ROW EXCLUSIVE MODE |
SRX |
| LOCK TABLE table IN EXCLUSIVE MODE |
X |
| |
RS: row share |
Enqueue算法
Lock使用的Enqueue算法,可以理解为“先入先出队列”。
注意: Enqueue的获取/转换/释放操作都是由 Session操作的,而不是由Process
如果会话的锁定请求不能满足,该会话的Lock Structure就被加到Waiter的链表的末端。当占用会话释放锁时,会检查Waiter和Converter队列,把锁分配给最先进入队列的请求者。 Waiter和Converter两个都是等待队列,二者的用法有细微的区别:如果某个操作先后需要两种不同模式的锁,比如先Share Mode然后是Exclusive Mode,则会话会先请求 Share Mode,获得后Lock Structure会挂在Owner队列上,当需要Exclusive Mode时,会话必须先释放Share Mode的锁,然后再次申请Exclusive Mode的锁,但是可能无法立即获得,这是这个请求被挂在Conveter队列下, Conveter队列会优先于Waiter 队列被处理。可以从v$lock视图中看到这些Lock信息,并且根据LMODE和REQUEST MODE判断谁是OWNER、 Waiter和 Conveter。
LMODE>0,REQUEST MODE=0 OWNER
LMODE=0,REQUEST MODE>0 Waiter
LMODE>0,REQUEST MODE>0 Conveter
DDL锁
当用户发布DDL(Data Definition Language)语句时会对涉及的对象加DDL锁。由于DDL语句会更改数据字典,所以该锁也被称为字典锁。
DDL锁能防止在用DML语句操作数据库表时,对表进行删除,或对表的结构进行更改。
对于DDL锁,要注意的是:
DDL锁只锁定DDL操作所涉及的对象,而不会锁定数据字典中的所有对象。
DDL锁由Oracle自动加锁和释放。不能显式地给对象加DDL锁,即没有加DDL锁的语句。
在过程中引用的对象,在过程编译结束之前不能被改变或删除,即不能被加排他DDL锁。
DDL锁的类型与特征如表所示。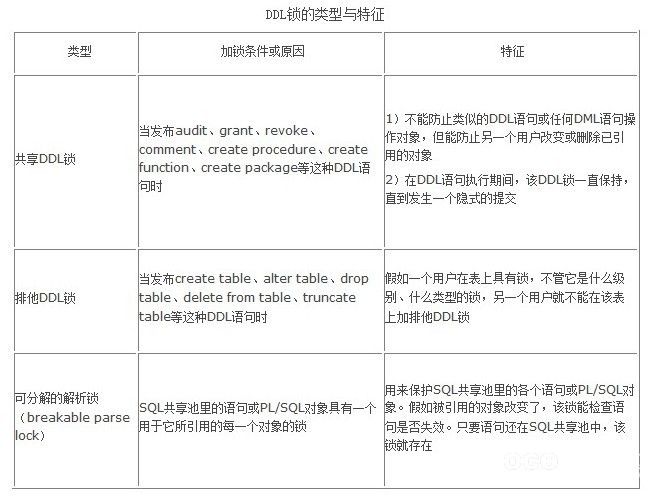
数据记录的行级锁概述
数据块是Oracle最基本的存储单元,每个数据块可以分成两部分,数据块头和数据块体。数据块头存放着管理信息,和事务相关的就是 ITL(Interested Trasaction List)。数据块体存放着具体的记录。用户记录也按照一定的格式保存的,每条记录可以分成记录头和记录体两部分,记录头是描述信息的宽度,和事务相关的 是ITL Entry Pointer字段。整个行级锁共涉及以下4种结构。
ITL:每个数据块的块头都存有ITL用于记录哪些事务修改了这个数据块的内容。可以把它想象成一张表,每一个表项对应一个事务,包括事务号,事务是否提交等重要信息。
记录头ITL索引:每条记录的记录头部都有一个字段,用于记录ITL表项号,可以看作是指向ITL表的指针
TX锁:代表一个事务。属于LOCK机制拥有, Lock Structure、Resource Structure和Enqueue算法。
TM锁:也属于LOCK机制,用于保护对象的定义不被修改。
行级锁机制
当一个事务开始时,必须申请一个TX锁,这种锁保护的资源是回滚段、回滚数据块。因此申请也就意味着:用户进程必须先申请到回滚段资源后才开始一个事务,才能执行DML操作。申请到回滚段后,用户事务就可以修改数据了。具体顺序如下:
1、首先获得TM锁,保护事务执行时,其他用户不能修改表结构
2、事务修改某个数据块中记录时,该数据块头部的ITL表中申请一个空闲表项,在其中记录事务项号,实际就是记录这个事务要使用的回滚段的地址(应该叫包含)
3、事务修改数据块中的某条记录时,会设置记录头部的ITL索引指向上一步申请到的表项。然后修改记录。修改前先在回滚段将记录之前的状态做一个拷贝,然后修改表中数据。
4、其他用户并发修改这条记录时,会根据记录头部ITL索引读取ITL表项内容,确认是否事务提交。
5若没有提交,必须等待TX锁释放
从上面的机制来看,无论一个事务修改多少条记录,都只需要一个TX锁。所谓的“行级锁”其实也就是数据块头、数据记录头的一些字段,不会消耗额外的资源。 从另一方面也证明了,当用户被阻塞时,不是被某条记录阻塞,而是被TX锁堵塞。也正因为这点,很多人也倾向把TX锁称为事务锁。这里可通过实验来验证所说 结论。
会话1
SQL> select * from test;
ID NAME
---------- --------
1 A
2 B
3 C
SQL> savepoint a;
Savepoint created.
SQL> update test set name='ssss' where id=2;
1 row updated.
会话2
SQL> update test set name='ssdsdsds'where id=2;
会话1
SQL> rollback to a;
Rollback complete.
可以看到,虽然会话1已经撤销了对记录的修改,但是会话2仍然处于等待状态这是因为会话2是被会话1的TX锁阻塞的,而不是被会话1上的行级锁 阻塞(rollback to savepoint不会结束事务) 。
会话3
SQL> select username,event,sid,blocking_session from v$session where username='HR';
USERNAME EVENT SID BLOCKING_SESSION
-------- ----------------------------------- ---------- ----------------
HR enq: TX - row lock contention 146 159
HR SQL*Net message from client 159
会话1:
SQL> rollback;
会话2
SQL> update test set name='ssdsdsds'where id=2;
1 row updated.
会话3
SQL> select username,event,sid,blocking_session from v$session where username='HR';
USERNAME EVENT SID BLOCKING_SESSION
-------- ----------------------------------- ---------- ----------------
HR SQL*Net message from client 159
事务结束,tx锁释放,会话2update执行成功。
其他类型的锁
HW锁:主要用来控制特定对象空间分配时的并发操作。v$lock中的id1为表空间编号ts#,id2为需要分配空间的对象segment header的相对DBA(Data Block Address)位置。争用主要发生在大量插入时,或手工对该对象allocate/deallocate空间时。
US锁:控制特定Undo Segment上的并行话操作。 v$lock中的id1为 Undo Segment的 编号*1,id2始终为1。触发US 锁的相关操作有:
对回滚段的create/drop/alter操作;Offining PENDING OFFUNE RBS by SMON;SMON-abortive offline cleanup;startup
CF锁:与控制文件相关的锁:1、串行化对控制文件的修改。2、任何涉及到对控制文件进行修改的进程都会持有此锁。 v$lock中的id1 始终为0 ,id2为0时表示串行化控制文件的操作,为1时表示共享信息的访问。使用场景如下:
日志切换
新增、删除各种类型的文件(数据文件,临时文件,日志文件)
打开、关闭、备份数据库,改变表空间、数据文件的在线状态,读写状态
转储控制文件中的对象信息(数据文件,日志文件)
修改数据库的checkpoint信息
JQ锁:此锁是为了控制对job的并发访问与执行。正在运行的job会持有此锁, v$lock中的id1 始终为0 ,id2为job的编号job_no,oracle以此为基础创建 dba_jobs_running视图,可通过该视图确定正在运行的任务
SQ锁:此锁用来防止多个进程同时刷新SGA中的Sequence缓存。 v$lock中的id1 为sequence对应的object_id ,id2始终为0。如果对Sequence的cache设置较小,就会导致系统遭遇较多的SQ enqueue等待。另外,如果sequence使用nocache,系统可能会遭遇到较严重的row cache lock,而不会出现SQ enqueue。
参考至:《大话Oracle RAC》张晓明著
《让Oracle跑得更快》谭怀远著
http://blog.csdn.net/lxlj2006/article/details/5999563
http://space.itpub.net/9268278/viewspace-196031
http://www.dbthink.com/?p=575&utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+dbthink+%28a+db+thinker%27s+home%29
本文原创,转载请注明出处、作者
如有错误,欢迎指正