服务框架HSF分析之三Consumer启动和处理
前两篇文章为大家带来了HSF容器启动和Porvider的分享。这篇来分析下consumer端的运行机制。
一. Consumer的启动
1. 服务代理
在HSFSpringConsumer的启动中会返回一个HSFServiceProxy的jdk动态代理,后续调用其实都是通过这个代理类来实现的。
InvocationHandler handler = newHSFServiceProxy(metadata);
Object proxyObj =Proxy.newProxyInstance(getClass().getClassLoader(), new Class[] {interfaceClass }, handler);
2. 服务订阅
通过metadataService的subscribe订阅服务的信息,主要是接口的所有地址,路由规则和机房流量规则
a. 路由规则
通过diamond订阅路由规则
DiamondManager diamondManager = newDefaultDiamondManager(group, dataId, new ManagerListenerAdapter() {
@Override
public voidreceiveConfigInfo(String configInfo) {
registerRule(serviceUniqueName, configInfo);
}
});
.......
registerRule(serviceUniqueName,configInfo);
当consumer端会有定时线程去diamond端获取单个服务的配置信息,默认周期15s,同时diamond使用了pushit进行实时通知,当有变更时会实时拿到变更信息,当有规则变更时都会刷新本地规则。
b. 路由规则注册
主要分2部分,路由规则(机器路由),机房流量规则(是否本地机房优先)
b.1 路由规则注册
b.1.1规则解析
代码:
// 处理路由规则
if (splitter.has(HSFConstants.HEADER_ROUTING_RULE)) {
final String routingRule =splitter.get(HSFConstants.HEADER_ROUTING_RULE);
addressService.setServiceRouteRule(serviceUniqueName, routingRule);
}
当在diamond里配置了路由规则时触发更新,规则内容类似于
Groovy_v200907@package hqm.test.groovy
public class RoutingRule{
Map<String,List<String>> routingRuleMap(){
return[
"DETAIL":[
"172.23.172.101:*",
"172.24.165.63:*",
"172.23.204.170:*",
"172.23.204.185:*",
……
]
];
}
String interfaceRoutingRule(){
return null;
}
String mathodRoutingRule(String methodName, String[] paramTypeStrs){
return "DETAIL";
}
Object argsRoutingRule(String methodName, String[] paramTypeStrs){
return null;
}
}
在setServiceRouteRule中,hsf会调用parser来解析这些规则,上面那个规则将被GroovyRouteRuleParser解析成RouteRule实体,代码:
RouteRule<String> rule = null;
for (RouteRuleParser parser : this.ruleParsers) {
...
rule =parser.parse(rawRouteRuleObj, allMethodSigs);
...
}
具体parse过程:
1. 拿到Groovy的Classloader:GroovyClassLoader loader = newGroovyClassLoader(GroovyRouteRuleParser.class.getClassLoader());
2. 将规则加载成Class实例 c_groovy = loader.parseClass(groovyRule);
3. 反射生成实例 ruleObj = c_groovy.newInstance();
4. 反射调用routingRuleMap方法,拿到规则索引的Map,后续的类级,方法级规则等的处理都是基于这个规则索引的
5. 反射调用interfaceRoutingRule方法,拿到接口级别的规则名称
6. 反射调用mathodRoutingRule方法,拿到方法级别的规则名称
7. 反射调用argsRoutingRule方法,拿到参数级别的规则名称
8. 组装RouteRule实体对象,返回之
b.1.2 地址结果更新
规则实体解析之后,就需要对现有的地址进行更新了,这样就可以让配置在调用方起效。代码:
RouteResultCache<String>addressCache = getRouteResultCache(serviceUniqueName);
addressCache.setRouteRule(rule);
addressCache.reset();
RouteResultCache对象是对调用方直接可见的路由结果,也是规则生效所需要刷新的数据实体。为了方便进行并发控制,其实现使用了RefHolder的方式来更新,就是把所有数据对象都包了一层refer,刷新的时候直接修改refer的引用即可。具体reset过程:
1. 对规则索引的map进行规则过滤,从规则map生成一个结果map,其value不再是规则(正则表达式),而是过滤之后的具体机器地址了,规则过滤的源是当前所有可用的服务器列表
2. 重新计算接口级地址列表。从之前的规则索引中拿到具体规则,对当前所有可用的服务器列表进行过滤,得到接口级别的地址列表
3. 同样方法计算方法级别的地址列表
4. 引用切换
b.2机房流量规则
代码:
// 处理机房流量规则
if (splitter.has(HSFConstants.HEADER_FLOW_CONTROL_RULE)){
StringflowControlRule = splitter.get(HSFConstants.HEADER_FLOW_CONTROL_RULE);
addressService.setFlowControlRule(serviceUniqueName, flowControlRule);
}
Diamond中的规则定义:
flowControl@<flowControl><localPreferredSwitch>on</localPreferredSwitch><threshold>0.2</threshold></flowControl>
具体set过程:
1. 使用FlowControlRuleParser解析规则xml,生成FlowControlRule实体
2. 刷新该服务对应的AddressBucket实体中的可用服务列表,实现如下
3. 拿到所有地址
4. 通过过滤拿到所有可用的本机房地址列表
5. 如果本地优先,则设置可用服务地址列表为本地可用地址列表
6. 否则设置可用服务地址列表为所有可用地址列表(所有地址列表中过滤掉invalid的地址)
7. 地址结果更新,和路由规则一样将计算后的结果更新到RouteResultCache
c. 服务地址信息注册
通过configserver的推送,更新本地的所有地址列表,当有机器重新注册时,就会推送,这里是异步的。代码:
// 订阅服务地址信息
final String cs_subscriberId = SUBSCRIBER_PREFIX + serviceUniqueName;
SubscriberRegistration cs_registration = newSubscriberRegistration(cs_subscriberId, serviceUniqueName);
cs_registration.setGroup(group);
Subscriber subscriber = SubscriberRegistrar.register(cs_registration);
subscriber.setDataObserver(new SubscriberDataObserver() {
@Override
public void handleData(StringdataId, List<Object> datas) {
for (Object serviceUrl :datas) {
urls.add((String) serviceUrl);
}
addressService.setServiceAddresses(dataId, urls);
}
});
具体set过程:
1. 设置服务地址列表全集并重新计算服务地址列表,修改服务对应的AddressBucket实体中的所有地址列表
2. 从所有地址类表中筛选出和本机同处一个机房的机器列表,方式是比较ip前2段。。。
3. 刷新可用服务地址列表,和机房流量规则解析时一样
4. 地址结果更新,和路由规则一样将计算后的结果更新到RouteResultCache
二. Consumer的执行
调用consumer时,直接调用HSFServiceProxy的invoke方法,其最终会使用RPCProtocolTemplateComponent进行rpc调用。过程:
1. 组装请求对象
// 组装HSFRequest
final HSFRequest request = new HSFRequest();
request.setTargetServiceUniqueName(serviceUniqueName);
request.setMethodName(methodName);
request.setMethodArgSigs(paramTypeStrs);
request.setMethodArgs(args);
2. 是否需要发起远程调用,这里如果本地就有provider的话,直接调用本地service,我们常用的同步调用是需要发起远程调用的
3. 如果需要发起远程调用,则寻找调用目标地址,如为测试模式,则以配置的target为优先
4. 调用addressService的getServiceAddress寻址,寻址过程为单亲委派模式:参数级 -> 方法级 -> 接口级 -> 全部可用地址
5. 从计算后的地址列表中选一台机器作为调用对象
6. 校验目标机器是否可用,尝试创建连接,如果成功则认为可用,否则不可用
7. 如果不可用,将目标添加到invalid地址中,继续重试,重试最多2次
8. 如果重试之后还是找不到,则抛出异常,报找不到目标。。
9. 寻址代码:
// 当target不为null,或者重试次数已到达最大重试次数时,退出寻找可用的目标服务地址的过程
for (int i = 0;(isBlank(targetURL)) && (i < RETRY_TIMES); i++) {
...
targetURL =addressService.getServiceAddress(serviceUniqueName, methodName, paramTypeStrs,args);
if(!rpcService.validTarget(targetURL)) {
...
addressProfiler.addInvalidAddress(serviceUniqueName, targetURL);
...
targetURL = null;
}
}
// 如这个时候targetURL仍然为null,抛出异常
if (isBlank(targetURL)) {
throw newHSFServiceAddressNotFoundException("[HSF-Consumer] 未找到需要调用的服务的目标地址", MessageFormat.format(
"需要调用的目标服务为:{0} 组别为:{1}", new Object[] { serviceUniqueName, metadata.getGroup() }));
}
10. 找到地址后,使用tbremoting发起调用
11. 构造一个client,注意之前判断是否目标可用时,其实已经创建好连接,这里直接使用
client =ClientManager.getImpl().get(HSFConstants.APPTYPE_FORREMOTING,
HSFServiceTargetUtil.formatTargetURL(targetURL));
12. Future方式发起调用,调用线程一直等待,直到超时或有返回,timeout为Long.MAX_VALUE
Object rawResponse =future.get().get(timeout);
…
synchronized (this) {
while (!isDone&& waitTime > 0) {
wait(waitTime);
waitTime = end -System.currentTimeMillis();
}
}
13. IO线程将请求发送成功之后,启动一个timer,在超时时间点运行,返回等待线程一个异常信息,说明是超时了
// On written of APP request, addPendingRequest and start timeout trigger
if (wf.isWritten()) {
..
TimeoutHandle timeoutHandle =new TimeoutHandle();
timeoutFuture =DefaultClientManager.timer.schedule(timeoutHandle,connRequest.getRespTimeout(), TimeUnit.MILLISECONDS);
}
14. 如果provider端成功返回,则mina线程会调用DefaultMsgListener的messageReceived的方法,
DefaultClient client = (DefaultClient)connection.getClient();
client.putResponse((ConnectionResponse) message);
15. 写回响应,
DefaultRespFuture respFuture =(DefaultRespFuture) connRequest.getRespFuture();
respFuture.setResponse(connResp);
16. 唤醒等待的业务线程
synchronized (this) {
connResponse = resp;
isDone = true;
notifyAll();
}
17. 业务线程被唤醒后,处理provider返回的结果
private Object getResponseAfterDone()throws RemotingException {
int errorCode = connResponse.getResult();
switch (errorCode) {
case TRConstants.RESULT_SUCCESS:
returnconnResponse.getAppResponse();
case TRConstants.RESULT_TIMEOUT:
String log = LogResources.getLog(LogResources.RESP_TIMEOUT);
throw new TimeoutException(log);
case TRConstants.RESULT_OVERFLOW:
throw newWriteOverFlowException(connResponse.getErrorMsg(), (OverFlowWriteFuture)connResponse
.getErrorCause());
default:
throw newRemotingException(connResponse.getErrorMsg());
}
}
三. 小结
以上简单分析的consumer端的运行机制。Consumer端是服务治理的重点,其核心是寻址过程。Hsf使用了diamond动态规则来自定义规则,还是比较灵活的。
常见的找不到target的原因:
1. 对方机器不可用,invalid失败,比如发布的时候
2. 调用发起太快,configserver推送地址是异步的,有延时,如果调用很快发起,则有可能拿不到地址
3. 配置了特殊规则,把正常的机器过滤掉的
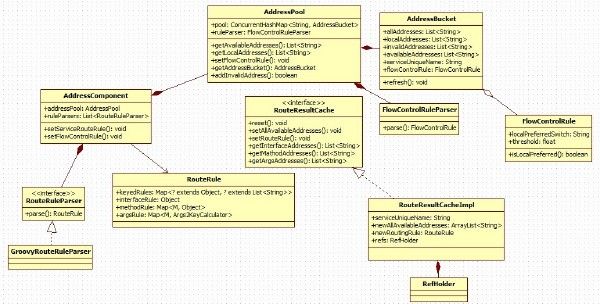
寻址类图如下: