转自:http://blog.csdn.net/czmao1985/article/details/6411667
数据库设计5步骤
Five Steps to design the Database
1.确定entities及relationships
a)明确宏观行为。数据库是用来做什么的?比如,管理雇员的信息。
b)确定entities。对于一系列的行为,确定所管理信息所涉及到的主题范围。这将变成table。比如,雇用员工,指定具体部门,确定技能等级。
c)确定relationships。分析行为,确定tables之间有何种关系。比如,部门与雇员之间存在一种关系。给这种关系命名。
d)细化行为。从宏观行为开始,现在仔细检查这些行为,看有哪些行为能转为微观行为。比如,管理雇员的信息可细化为:
·增加新员工
·修改存在员工信息
·删除调走的员工
e)确定业务规则。分析业务规则,确定你要采取哪种。比如,可能有这样一种规则,一个部门有且只能有一个部门领导。这些规则将被设计到数据库的结构中。
====================================================================
范例:
ACME是一个小公司,在5个地方都设有办事处。当前,有75名员工。公司准备快速扩大规模,划分了9个部门,每个部门都有其领导。
为有助于寻求新的员工,人事部门规划了68种技能,为将来人事管理作好准备。员工被招进时,每一种技能的专业等级都被确定。
定义宏观行为
一些ACME公司的宏观行为包括:
● 招聘员工
● 解雇员工
● 管理员工个人信息
● 管理公司所需的技能信息
● 管理哪位员工有哪些技能
● 管理部门信息
● 管理办事处信息
确定entities及relationships
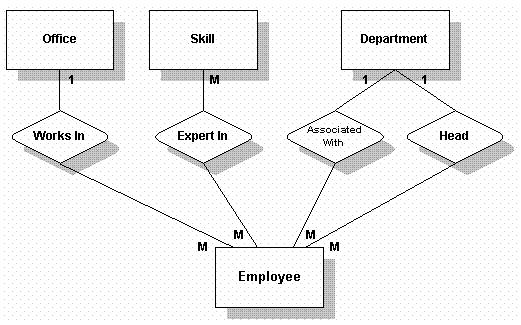
我们可以确定要存放信息的主题领域(表)及其关系,并创建一个基于宏观行为及描述的图表。
我们用方框来代表table,用菱形代表relationship。我们可以确定哪些relationship是一对多,一对一,及多对多。
这是一个E-R草图,以后会细化。
细化宏观行为
以下微观行为基于上面宏观行为而形成:
● 增加或删除一个员工
● 增加或删除一个办事处
● 列出一个部门中的所有员工
● 增加一项技能
● 增加一个员工的一项技能
● 确定一个员工的技能
● 确定一个员工每项技能的等级
● 确定所有拥有相同等级的某项技能的员工
● 修改员工的技能等级
这些微观行为可用来确定需要哪些table或relationship。
确定业务规则
业务规则常用于确定一对多,一对一,及多对多关系。
相关的业务规则可能有:
● 现在有5个办事处;最多允许扩展到10个。
● 员工可以改变部门或办事处
● 每个部门有一个部门领导
● 每个办事处至多有3个电话号码
● 每个电话号码有一个或多个扩展
● 员工被招进时,每一种技能的专业等级都被确定。
● 每位员工拥有3到20个技能
● 某位员工可能被安排在一个办事处,也可能不安排办事处。
2.确定所需数据
要确定所需数据:
a)确定支持数据
b)列出所要跟踪的所有数据。描述table(主题)的数据回答这些问题:谁,什么,哪里,何时,以及为什么
c)为每个table建立数据
d)列出每个table目前看起来合适的可用数据
e)为每个relationship设置数据
f)如果有,为每个relationship列出适用的数据
确定支持数据
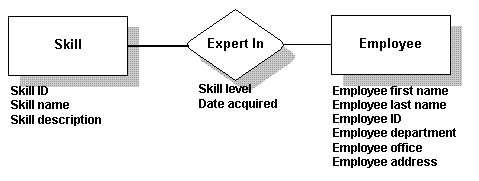
你所确定的支持数据将会成为table中的字段名。比如,下列数据将适用于表Employee,表Skill,表Expert In。
| Employee |
Skill |
Expert In |
| ID |
ID |
Level |
| Last Name |
Name |
Date acquired |
| First Name |
Description |
|
| Department |
||
| Office |
||
| Address |
如果将这些数据画成图表,就像:
需要注意:
● 在确定支持数据时,请一定要参考你之前所确定的宏观行为,以清楚如何利用这些数据。
● 比如,如果你知道你需要所有员工的按姓氏排序的列表,确保你将支持数据分解为名字与姓氏,这比简单地提供一个名字会更好。
● 你所选择的名称最好保持一致性。这将更易于维护数据库,也更易于阅读所输出的报表。
● 比如,如果你在某些地方用了一个缩写名称Emp_status,你就不应该在另外一个地方使用全名(Empolyee_ID)。相反,这些名称应当是Emp_status及Emp_id。
● 数据是否与正确的table相对应无关紧要,你可以根据自己的喜好来定。在下节中,你会通过测试对此作出判断。
3.标准化数据
标准化是你用以消除数据冗余及确保数据与正确的table或relationship相关联的一系列测试。共有5个测试。本节中,我们将讨论经常使用的3个。
关于标准化测试的更多信息,请参考有关数据库设计的书籍。
标准化格式
标准化格式是标准化数据的常用测试方式。你的数据通过第一遍测试后,就被认为是达到第一标准化格式;通过第二遍测试,达到第二标准化格式;通过第三遍测试,达到第三标准化格式。
如何标准格式:
1.列出数据
2.为每个表确定至少一个键。每个表必须有一个主键。
3.确定relationships的键。relationships的键是连接两个表的键。
4.检查支持数据列表中的计算数据。计算数据通常不保存在数据库中。
5.将数据放在第一遍的标准化格式中:
6.从tables及relationships除去重复的数据。
7.以你所除去数据创建一个或更多的tables及relationships。
8.将数据放在第二遍的标准化格式中:
9.用多于一个以上的键确定tables及relationships。
10.除去只依赖于键一部分的数据。
11.以你所除去数据创建一个或更多的tables及relationships。
12.将数据放在第三遍的标准化格式中:
13.除去那些依赖于tables或relationships中其他数据,并且不是键的数据。
14.以你所除去数据创建一个或更多的tables及relationships。
数据与键
在你开始标准化(测试数据)前,简单地列出数据,并为每张表确定一个唯一的主键。这个键可以由一个字段或几个字段(连锁键)组成。
主键是一张表中唯一区分各行的一组字段。Employee表的主键是Employee ID字段。Works In relationship中的主键包括Office Code及Employee ID字段。给数据库中每一relationship给出一个键,从其所连接的每一个table中抽取其键产生。
| RelationShip |
Key |
| Office |
*Office code |
| Office address |
|
| Phone number |
|
| Works in |
*Office code |
| *Employee ID |
|
| Department |
*Department ID |
| Department name |
|
| Heads |
*Department ID |
| *Employee ID |
|
| Assoc with |
*Department ID |
| *EmployeeID |
|
| Skill |
*Skill ID |
| Skill name |
|
| Skill description |
|
| Expert In |
*Skill ID |
| *Employee ID |
|
| Skill level |
|
| Date acquired |
|
| Employee |
*Employee ID |
| Last Name |
|
| First Name |
|
| Social security number |
|
| Employee street |
|
| Employee city |
|
| Employee state |
|
| Employee phone |
|
| Date of birth |
将数据放在第一遍的标准化格式中
● 除去重复的组
● 要测试第一遍标准化格式,除去重复的组,并将它们放进他们各自的一张表中。
● 在下面的例子中,Phone Number可以重复。(一个工作人员可以有多于一个的电话号码。)将重复的组除去,创建一个名为Telephone的新表。在Telephone与Office创建一个名为Associated With的relationship。
将数据放在第二遍的标准化格式中
● 除去那些不依赖于整个键的数据。
● 只看那些有一个以上键的tables及relationships。要测试第二遍标准化格式,除去那些不依赖于整个键的任何数据(组成键的所有字段)。
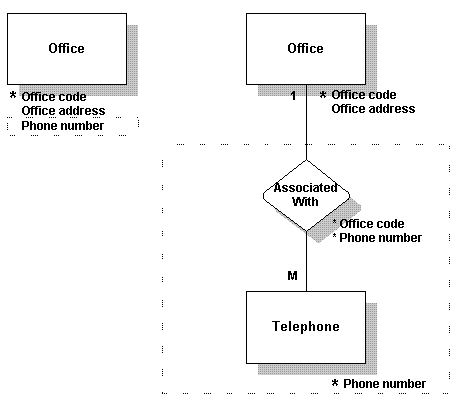
● 在此例中,原Employee表有一个由两个字段组成的键。一些数据不依赖于整个键;例如,department name只依赖于其中一个键(Department ID)。因此,Department ID,其他Employee数据并不依赖于它,应移至一个名为Department的新表中,并为Employee及Department建立一个名为Assigned To的relationship。
将数据放在第三遍的标准化格式中
● 除去那些不直接依赖于键的数据。
● 要测试第三遍标准化格式,除去那些不是直接依赖于键,而是依赖于其他数据的数据。
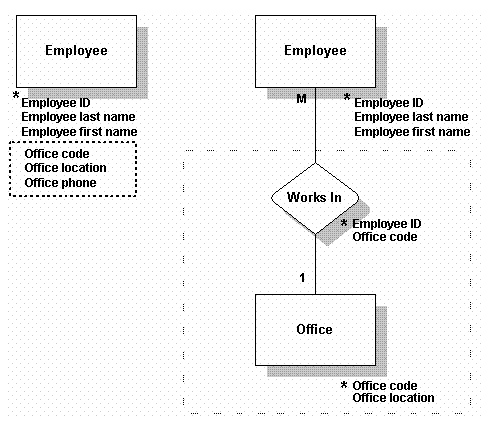
● 在此例中,原Employee表有依赖于其键(Employee ID)的数据。然而,office location及office phone依赖于其他字段,即Office Code。它们不直接依赖于Employee ID键。将这组数据,包括Office Code,移至一个名为Office的新表中,并为Employee及Office建立一个名为Works In的relationship。
4.考量关系
当你完成标准化进程后,你的设计已经差不多完成了。你所需要做的,就是考量关系。
考量带有数据的关系
你的一些relationship可能集含有数据。这经常发生在多对多的关系中。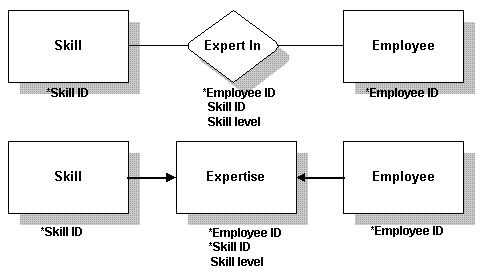
遇到这种情况,将relationship转化为一个table。relationship的键依旧成为table中的键。
考量没有数据的关系
要实现没有数据的关系,你需要定义外部键。外部键是含有另外一个表中主键的一个或多个字段。外部键使你能同时连接多表数据。
有一些基本原则能帮助你决定将这些键放在哪里:
一对多在一对多关系中,“一”中的主键放在“多”中。此例中,外部键放在Employee表中。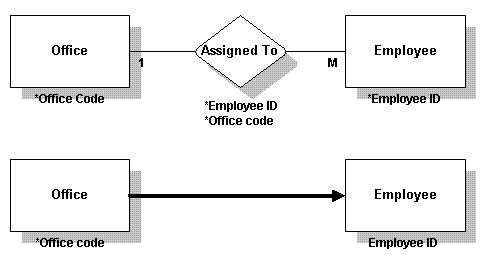
一对一在一对一关系中,外部键可以放进任一表中。如果必须要放在某一边,而不能放在另一边,应该放在必须的一边。此例中,外部键(Head ID)在Department表中,因为这是必需的。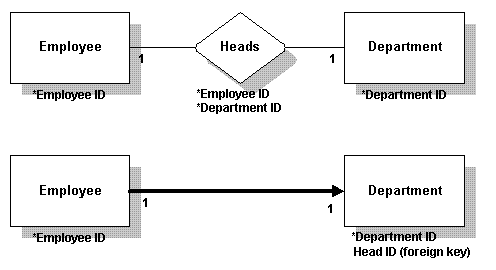
多对多在多对多关系中,用两个外部键来创建一个新表。已存的旧表通过这个新表来发生联系。
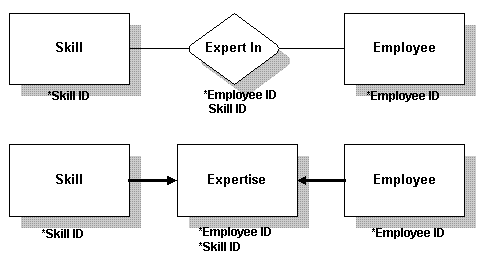
5.检验设计
在你完成设计之前,你需要确保它满足你的需要。检查你在一开始时所定义的行为,确认你可以获取行为所需要的所有数据:
● 你能找到一个路径来等到你所需要的所有信息吗?
● 设计是否满足了你的需要?
● 所有需要的数据都可用吗?
如果你对以上的问题都回答是,你已经差不多完成设计了。
最终设计
最终设计看起来就像这样:
设计数据库的表属性
数据库设计需要确定有什么表,每张表有什么字段。此节讨论如何指定各字段的属性。
对于每一字段,你必须决定字段名,数据类型及大小,是否允许NULL值,以及你是否希望数据库限制字段中所允许的值。
选择字段名
字段名可以是字母、数字或符号的任意组合。然而,如果字段名包括了字母、数字或下划线、或并不以字母打头,或者它是个关键字(详见关键字表),那么当使用字段名称时,必须用双引号括起来。
为字段选择数据类型
SQL Anywhere支持的数据类型包括:
整数(int, integer, smallint)
小数(decimal, numeric)
浮点数(float, double)
字符型(char, varchar, long varchar)
二进制数据类型(binary, long binary)
日期/时间类型(date, time, timestamp)
用户自定义类型
关于数据类型的内容,请参见“SQL Anywhere数据类型”一节。字段的数据类型影响字段的最大尺寸。例如,如果你指定SMALLINT,此字段可以容纳32,767的整数。INTEGER可以容纳2,147,483,647的整数。对CHAR来讲,字段的最大值必须指定。
长二进制的数据类型可用来在数据库中保存例如图像(如位图)或者文字编辑文档。这些类型的信息通常被称为二进制大型对象,或者BLOBS。
关于每一数据类型的完整描述,见“SQL Anywhere数据类型”。
NULL与NOT NULL
如果一个字段值是必填的,你就将此字段定义为NOT NULL。否则,字段值可以为NULL值,即可以有空值。SQL中的默认值是允许空值;你应该显示地将字段定义为NOT NULL,除非你有好理由将其设为允许空值。
关于NULL值的完整描述,请见“NULL value”。有关其对比用法,见“Search conditions”。
选择约束
尽管字段的数据类型限制了能存在字段中的数据(例如,只能存数字或日期),你或许希望更进一步来约束其允许值。
你可以通过指定一个“CHECK”约束来限制任意字段的值。你可以使用能在WHERE子句中出现的任何有效条件来约束被允许的值,尽管大多数CHECK约束使用BETWEEN或IN条件。
更多信息
有关有效条件的更多信息,见“Search conditions”。有关如何为表及字段指定约束,见“Ensuring Data Integrity”。
====================================================================
范例
例子数据库中有一个名为department的表,字段是dept_id, dept_name, dept_head_id。其定义如下:
| Fields |
Type |
Size |
Null/Not Null |
Constraint |
| Dept_id |
Integer |
-- |
Not null |
None |
| Dept_name |
Char |
40 |
Not null |
None |
| Dept_head_id |
Integer |
-- |
Not null |
None |
注意每一字段都被指定为“not null”。这种情况下,表中每一记录的所有字段的数据都必填。
选择主键及外部键
主键是唯一识别表中每一项记录的字段。如何你的表已经正确标准化,主键应当成为数据库设计的一部分。
外部键是包含另一表中主键值的一个或一组字段。外部键关系在数据库中建立了一对一及一对多关系。如果你的设计已经正确标准化,外部键应当成为数据库设计的一部分。
There are five major steps in the design process.
- Step 1: identify entities and relationships
- Step 2: identify the required data
- Step 3: normalize the data
- Step 4: resolve the relationships
- Step 5: verify the design
$ For information about implementing the database design, see the chapter "Working with Database Objects".
Step 1: identify entities and relationships
- To identify the entities in your design and their relationship to each other:
- Define high-level activities. Identify the general activities you will use this database for. For example, you may want to keep track of information about employees.
- Identify entities. For the list of activities, identify the subject areas you need to maintain information about. These will become tables. For example, hire employees, assign to a department, and determine a skill level.
- Identify relationships. Look at the activities and determine what the relationships will be between the tables. For example, there is a relationship between departments and employees. We give this relationship a name.
- Break down the activities. You started out with high-level activities. Now examine these activities more carefully to see if some of them can be broken down into lower-level activities. For example, a high-level activity such as maintain employee information can be broken down into:
- Add new employees
- Change existing employee information
- Delete terminated employees
- Add new employees
- Define high-level activities. Identify the general activities you will use this database for. For example, you may want to keep track of information about employees.
- Identify business rules. Look at your business description and see what rules you follow. For example, one business rule might be that a department has one and only one department head. These rules will be built into the structure of the database.
Example
ACME Corporation is a small company with offices in five locations. Currently, 75 employees work for ACME. The company is preparing for rapid growth and has identified nine departments, each with its own department head.
To help in its search for new employees, the personnel department has identified 68 skills that it believes the company will need in its future employee base. When an employee is hired, the employee's level of expertise for each skill is identified.
Define high-level activities
Some of the high-level activities for ACME Corporation are:
- Hire employees
- Terminate employees
- Maintain personal employee information
- Maintain information on skills required for the company
- Maintain information on which employees have which skills
- Maintain information on departments
- Maintain information on offices
Identify the entities and relationships
We can identify the subject areas (tables) and relationships that will hold the information and create a diagram based on the description and high-level activities.
We use boxes to show tables and diamonds to show relationships. We can also identify which relationships are one-to-many, one-to-one, and many-to-many.
This is a rough E-R diagram. It will be refined throughout the chapter.
Break down the high-level activities
The lower-level activities below are based on the high-level activities listed above:
- Add or delete an employee
- Add or delete an office
- List employees for a department
- Add a skill
- Add a skill for an employee
- Identify skills for an employee
- Identify an employee's skill level for each skill
- Identify all employees that have the same skill level for a particular skill
- Change an employee's skill level
These lower-level activities can be used to identify if any new tables or relationships are needed.
Identify business rules
Business rules often identify one-to-many, one-to-one, and many-to-many relationships.
The kind of business rules that may be relevant include the following:
- There are now five offices; expansion plans allow for a maximum of 10.
- Employees can change department or office
- Each department has one department head
- Each office has a maximum of three telephone numbers
- Each telephone number has one or more extensions
- When an employee is hired, the level of expertise in each of several skills is identified
- Each employee can have from three to 20 skills
- An employee may or may not be assigned to an office
Step 2: identify the required data
- To identify the required data:
- Identify supporting data.
- List all the data you will need to keep track of. The data that describes the table (subject) answers the questions who, what, where, when, and why.
- Set up data for each table.
- List the available data for each table as it seems appropriate right now.
- Set up data for each relationship.
- List the data that applies to each relationship (if any).
- Identify supporting data.
Identify supporting data
The supporting data you identify will become the names of the columns in the table. For example, the data below might apply to the Employee table, the Skill table, and the Expert In table:
Employee Skill Expert In| Employee ID | Skill ID | Skill level |
| Employee first name | Skill name | Date skill was acquired |
| Employee last name | Description of skill | |
| Employee department | ||
| Employee office | ||
| Employee address |
If you make a diagram of this data, it will look like this:
Things to remember
- When you are identifying the supporting data, be sure to refer to the activities you identified earlier to see how you will need to access the data.
- For example, if you know that you will need a list of all employees sorted by last name, make sure that you specify supporting data as Last name and First name, rather than simply Name (which would contain both first and last names).
- The names you choose should be consistent. Consistency makes it easier to maintain your database and easier to read reports and output windows.
- For example, if you choose to use an abbreviated name such as Emp_status for one piece of data, you should not use the full name (Employee_ID) for another piece of data. Instead, the names should be Emp_status and Emp_ID.
- It is not crucial that the data be associated with the correct table. You can use your intuition. In the next section, you'll apply tests to check your judgment.
Step 3: normalize the data
Normalization is a series of tests you use to eliminate redundancy in the data and make sure the data is associated with the correct table or relationship. There are five tests. In this section, we will talk about the three tests that are usually used.
For more information about the normalization tests, see a book on database design.
Normal forms
Normal forms are the tests you usually use to normalize data. When your data passes the first test, it is considered to be in first normal form, when it passes the second test, it is in second normal form, and when it passes the third test, it is in third normal form.
- To normalize the data:
- List the data:
- Identify at least one key for each table. Each table must have a primary key.
- Identify keys for relationships. The keys for a relationship are the keys from the two tables it joins.
- Check for calculated data in your supporting data list. Calculated data is not normally stored in the database.
- Put data in first normal form:
- Remove repeating data from tables and relationships.
- Create one or more tables and relationships with the data you remove.
- Put data in second normal form:
- Identify tables and relationships with more than one key.
- Remove data that depends on only one part of the key.
- Create one or more tables and relationships with the data you remove.
- Put data in third normal form:
- Remove data that depends on other data in the table or relationship and not on the key.
- Create one or more tables and relationships with the data you remove.
- List the data:
Data and keys
Before you begin to normalize (test your data), simply list the data and identify a unique primary key for each table. The key can be made up of one piece of data (column) or several (a concatenated key).
The primary key is the set of columns that uniquely identifies rows in a table. The primary key for the Employee table is the Employee ID column. The primary key for the Works In relationship consists of the Office Code and Employee ID columns. Give a key to each relationship in your database by taking the key from each of the tables it connects. In the example, the keys identified with an asterisk are the keys for the relationship:
Relationship Key| Office | *Office code |
| Office address | |
| Phone number | |
| Works in | *Office code |
| *Employee ID | |
| Department | *Department ID |
| Department name | |
| Heads | *Department ID |
| *Employee ID | |
| Assoc with | *Department ID |
| *Employee ID | |
| Skill | *Skill ID |
| Skill name | |
| Skill description | |
| Expert in | *Skill ID |
| *Employee ID | |
| Skill level | |
| Date acquired | |
| Employee | *Employee ID |
| Employee last name | |
| Employee first name | |
| Social security number | |
| Employee street | |
| Employee city | |
| Employee state | |
| Employee phone | |
| Date of birth |
Putting data in first normal form
- Remove repeating groups.
- To test for first normal form, remove repeating groups and put them into a table of their own.
- In the example below, Phone number can repeat. (An office can have more than one telephone number.) Remove the repeating group and make a new table called Telephone. Set up a relationship called Associated With between Telephone and Office.
Putting data in second normal form
- Remove data that does not depend on the whole key.
- Look only at tables and relationships that have more than one key. To test for second normal form, remove any data that does not depend on the whole key (all the columns that make up the key).
- In this example, the original Employee table specifies a key composed of two columns. Some of the data does not depend on the whole key; for example, the department name depends on only one of those keys (Department ID). Therefore, the Department ID, which the other employee data does not depend on, is moved to a table of its own called Department, and a relationship called Assigned To is set up between Employee and Department.
Putting data in third normal form
- Remove data that doesn't depend directly on the key.
- To test for third normal form, remove any data that depends on other data rather than directly on the key.
- In this example, the original Employee table contains data that depends on its key (Employee ID). However, data such as office location and office phone depend on another piece of data, Office code. They do not depend directly on the key, Employee ID. Remove this group of data along with Office code, which it depends on, and make another table called Office. Then we will create a relationship called Works In that connects Employee with Office.
Step 4: resolve the relationships
When you finish the normalization process, your design is almost complete. All you need to do is resolve the relationships.
Resolving relationships that carry data
Some of your relationships may carry data. This situation often occurs in many-to-many relationships.
When this is the case, change the relationship to a table. The key to the new table remains the same as it was for the relationship.
Resolving relationships that do not carry data
In order to implement relationships that do not carry data, you need to define foreign keys. A foreign key is a column or set of columns that contains primary key values from another table. The foreign key allows you to access data from more than one table at one time.
There are some basic rules that help you decide where to put the keys:
One to many In a one-to-many relationship, the primary key in the one is carried in the many. In this example, the foreign key goes into the Employee table.
One to one In a one-to-one relationship, the foreign key can go into either table. If it is mandatory on one side, but not on the other, it should go on the mandatory side. In this example, the foreign key (Head ID) is in the Department table because it is mandatory there.
Many to many In a many-to-many relationship, a new table is created with two foreign keys. The existing tables are now related to each other through this new table.
Step 5: verify the design
Before you implement your design, you need to make sure it supports your needs. Examine the activities you identified at the start of the design process and make sure you can access all the data the activities require:
- Can you find a path to get all the information you need?
- Does the design meet your needs?
- Is all the required data available?
If you can answer yes to all the questions above, you are ready to implement your design.
Final design
The final design of the example looks like this: