皮尔逊相关系数是比欧几里德距离更加复杂的可以判断人们兴趣的相似度的一种方法。该相关系数是判断两组数据与某一直线拟合程序的一种试题。它在数据不是很规范的时候,会倾向于给出更好的结果。
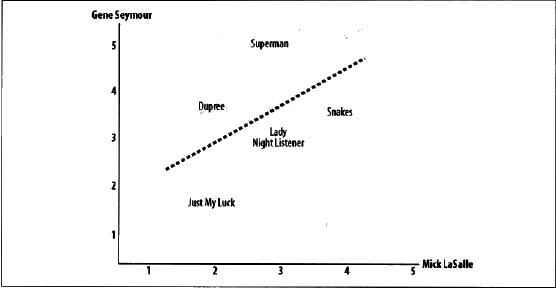
如图,Mick Lasalle为<<Superman>>评了3分,而Gene Seyour则评了5分,所以该影片被定位中图中的(3,5)处。在图中还可以看到一条直线。其绘制原则是尽可能地靠近图上的所有坐标点,被称为最佳拟合线。如果两位评论者对所有影片的评分情况都相同,那么这条直线将成为对角线,并且会与图上所有的坐标点都相交,从而得到一个结果为1的理想相关度评价。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:![]()
皮尔逊相关系数计算公式
公式二:![]()
皮尔逊相关系数计算公式
公式三:
皮尔逊相关系数计算公式
公式四:
皮尔逊相关系数计算公式
以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
皮尔逊相关度评价算法首先会找出两位评论者都曾评论过的物品,然后计算两者的评分总和与平方和,并求得评分的乘积之各。利用上面的公式四计算出皮尔逊相关系数。
critics = {'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane': 4.5, 'You, Me and Dupree': 1.0, 'Superman Returns': 4.0}}
from math import sqrt
def sim_pearson(prefs, p1, p2):
# Get the list of mutually rated items
si = {}
for item in prefs[p1]:
if item in prefs[p2]:
si[item] = 1
# if they are no ratings in common, return 0
if len(si) == 0:
return 0
# Sum calculations
n = len(si)
# Sums of all the preferences
sum1 = sum([prefs[p1][it] for it in si])
sum2 = sum([prefs[p2][it] for it in si])
# Sums of the squares
sum1Sq = sum([pow(prefs[p1][it], 2) for it in si])
sum2Sq = sum([pow(prefs[p2][it], 2) for it in si])
# Sum of the products
pSum = sum([prefs[p1][it] * prefs[p2][it] for it in si])
# Calculate r (Pearson score)
num = pSum - (sum1 * sum2 / n)
den = sqrt((sum1Sq - pow(sum1, 2) / n) * (sum2Sq - pow(sum2, 2) / n))
if den == 0:
return 0
r = num / den
return r
print(sim_pearson(critics,'Lisa Rose','Gene Seymour'))
0.396059017191
注:还有许多方法可以衡量两组数据间的相似程度,使用哪一种方法最优,完全取决于具体的应用。