Hadoop没有使用java.util.Properties管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是使用了一套独有的配置文件管理系统,并提供自己的API,即使用org.apache.hadoop.conf.Configuraiton处理配置信息。
1.1 Hadoop配置文件的格式
Hadoop配置文件采用XML格式,下面是Hadoop配置文件的一部分:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>dfs.name.dir</name>
<value>${hadoop.tmp.dir}/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
<property>
<name>dfs.web.ugi</name>
<value>webuser,webgroup</value>
<final>true</final>
<description>The user account used by the web interface.
Syntax: USERNAME,GROUP1,GROUP2, ...
</description>
</property>
… …
</configuration>
Hadoop配置文件的根元素是configuration,一般只包含子元素property。每一个property元素就是一个配置项。每个配置项一般包括配置属性的名称name、值value和一个关于配置项的描述description;元素final和Java中的关键字final类似,意味着这个配置项是“固定不变的”,在合并资源的时候,可以防止配置项的值被覆盖。
在上面的示例文件中,配置项dfs.web.ugi的值是“webuser,webgroup”,它是一个final配置项;从description看,这个配置项配置了Hadoop Web界面的用户账号,包括用户名和用户组信息。这些信息可以通过Configuration类提供的方法访问。
Hadoop配置系统还有一个很重要的功能,就是属性扩展。如配置项目dfs.name.dir的值是${hadoop.tmp.dir}/dfs/name,其中,${hadoop.tmp.dir}会使用Configuration中的相应属性值进行扩展。如果hadoop.tmp.dir的值是“/data”,那么扩展后的dfs.name.dir的值就是“/data/dfs.name”。
使用Configuration类的一般过程是:构造Configuration对象,并通过类的addResource()方法添加需要加载的资源;然后就可以使用get*方法和set*方法访问/设置配置项,资源会在每一次使用的时候自动加载到对象中。
1.2 Configuration的成员变量
在eclipse开发工具里打开Configuration类,再打开其大纲视图如下: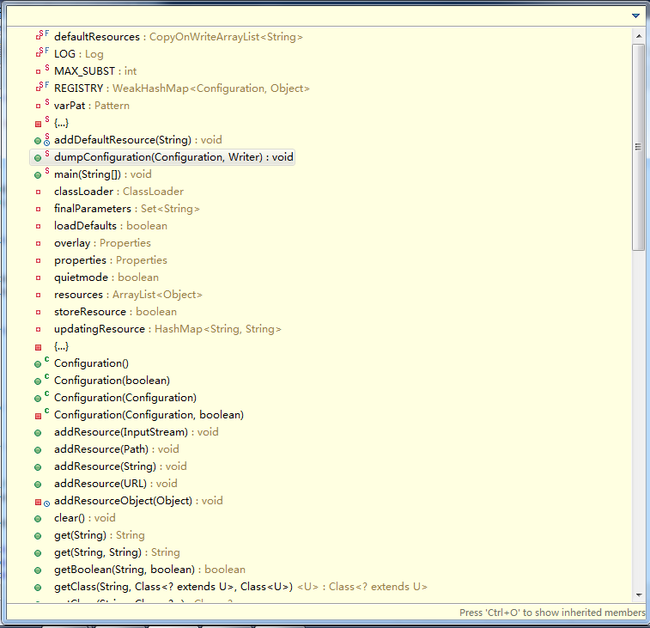
从大纲视图可以看到,Configuration有7个主要的非静态成员变量。
布尔变量quietmode,用来设置加载配置的模式。如果quietmode为true(默认值),则在加载解析配置文件的过程中,不输出日志信息。Quietmode只是一个方便开发人员调试的变量。
数组resources保存了所有通过addResource()方法添加到Configuration对象的资源。
Configuration.addResource()有如下4种形式:
public void addResource(InputStream in)
public void addResource(Path file)
public void addResource(String name) //CLASSPATH资源
public void addResource(URL url)
也就是说,用户可以添加如下形式的资源:
一个已经打开的输入流;
Hadoop文件路径org.apache.hadoop.fs.Path形式的资源,如hdfs://www.xxx.com:8888/conf/core-default.xml;
URL,如http://www.xxx.com/core-default.xml;
CLASSPATH资源(String形式)。
布尔变量loadDefaults用于确定是否加载默认资源,这些默认资源保存在defaultResources中。注意,defaultResources是个静态成员变量,通过方法addDefaultResource()可以添加系统的默认资源。如HDFS的DataNode中,就有下面的代码加载默认资源:
static{
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
}
properties、overlay和finalParameters都是和配置项相关的成员变量。其中,properties和overlay的类型都是java.util.Properties。Hadoop配置文件解析后的键-值对,都存放在properties中。变量finalParameters的类型是Set<String>,用来保存所有在配置文件中已经被声明为final的键-值对的键;变量overlay用于记录通过set()方式改变的配置项。也就是说,出现在overlay中的键-值对是应用设置的,而不是通过对配置资源解析得到的。
Configuration中最后一个重要的成员变量是classLoader,这是一个类加载器变量,可以通过它来加载指定类,也可以通过它加载相关的资源。上面提到addResource()可以通过字符串方式加载CLASSPATH资源,它其实通过Configuration中的getResource()将字符串转换在URL资源,相关代码如下:
public URL getResource(String name) {
return classLoader.getResource(name);
}
Configuration类的其他部分都是为了操作这些变量而实现的解析、设置、获取方法。
1.3 资源加载
资源通过对象的addResource()方法或类的静态addDefaultResource()方法(设置了loadDefaults标志)添加到Configuration对象中,添加的资源并不会立即被加载,只是通过reloadConfiguration()方法清空properties和finalParameters。相关代码如下:
public void addResource(String name) {
addResourceObject(name);
}
private synchronized void addResourceObject(Object resource) {
resources.add(resource); // 添加到成员变量“资源列表”中。
reloadConfiguration();
}
public synchronized void reloadConfiguration() {
properties = null; // 会触发资源的重新加载
finalParameters.clear();
}
静态方法addDefaultResource()也能清空Configuration对象中的数据(非静态成员变量),这是通过类的静态成员REGISTRY作为媒介进行的。
静态成员REGISTRY记录了系统中所有的Configuration对象,所以,addDefaultResource()被调用时,遍历REGISTRY中的元素并在元素上调用reloadConfiguration()方法,即可触发资源的重新加载,相关代码如下:
public static synchronized void addDefaultResource(String name) {
if(!defaultResources.contains(name)) {
defaultResources.add(name);
for(Configuration conf : REGISTRY.keySet()) {
if(conf.loadDefaults) {
conf.reloadConfiguration();
}
}
}
}
成员变量properties中的数据,直到需要的时候才会加载进来。在getProps()方法中,如果发现properties为空,将触发loadResources()方法加载配置资源。这里其实采用了延迟加载的设计模式,当真正需要配置数据的时候,才开始分析配置文件。相关代码如下:
private synchronized Properties getProps() {
if (properties == null) {
properties = new Properties();
loadResources(properties, resources, quietmode);
… …
}
return properties;
}
1.4 使用get*和set*访问/设置配置项
1.4.1 get*
get*个代表21个方法,它们用于在Configuration对象中获取相应的配置信息。这些配置信息可以是boolean(getBoolean)、int(getInt)、long(getLong)等基本类型,也可以是其他一些Hadoop常用类型,如类的信息(getClassByName、getClasses、getClass)、String数组(getStringCollection、getStrings)、URL(getResource)等。这些方法里最重要的是get()方法,它根据配置项的键获取对应的值,如果键不存在,则返回默认值defaultValue。其他的方法都会依赖于Configuration.get(),并在get()的基础上做进一步处理。Get()方法如下:
public String get(String name, String defaultValue){
return substituteVars(getProps().getProperty(name, defaultValue));
}
Configuration.get()会调用Configuration的私有方法substituteVars(),该方法会完成配置的属性扩展。substituteVars()中进行的属性扩展,不但可以使用保存在Configuration对象中的键-值对,而且还可以使用Java虚拟机的系统属性。
1.4.2 set*
相对于get*来说,set*的大多数方法都很简单,这些方法对输入进行类型转换等处理后,最终都调用了下面的Configuration.set()方法:
public void set(String name, String value) {
getOverlay().setProperty(name, value);
getProps().setProperty(name, value);
}
set()方法只是简单地调用了成员变量properties和overlay的setProperty()方法,保存传入的键-值对。
1.5 Configurable接口
Configurable是一个很简单的接口,在eclipse开发工具里其大纲视图如下:
如果一个类实现了Configurable接口,意味着这个类是可配置的。也就是说,可以通过为这个类的对象传入一个Configurable实例,提供对象工作需要的一些配置信息。如:
public void setConf(Configuration conf) {
String regex = conf.get(FILTER_REGEX);
if (regex==null)
throw new RuntimeException(FILTER_REGEX + "not set");
this.p = Pattern.compile(regex);
this.conf = conf;
}
如果setConf()方法比较简单, 只是简单的将参数Configuration赋值给这个类的对象成员变量,则可以直接继承hadoop提供的Configured类。
Configuration.setConf()方法何时被调用呢?一般来说,对象创建以后,就应该使用setConf()方法,为对象提供进一步的初始化工作。为了简化对象创建和调用setConf()方法这两个连续的步骤,org.apache.hadoop.util.ReflectionUtils中提供了静态方法newInstance(),代码如下:
public static <T> T newInstance(Class<T> theClass, Configuration conf) {
T result;
try {
Constructor<T> meth = (Constructor<T>) CONSTRUCTOR_CACHE.get(theClass);
if (meth == null) {
meth = theClass.getDeclaredConstructor(EMPTY_ARRAY);
meth.setAccessible(true);
CONSTRUCTOR_CACHE.put(theClass, meth);
}
result = meth.newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
setConf(result, conf);
return result;
}
方法newInstance()利用Java反射机制,根据对象类型信息(参数theClass),创建一个新的相应类型的对象,然后调用ReflectionUtils中的另一个静态方法setConf()配置对象,代码如下:
public static void setConf(Object theObject, Configuration conf) {
if (conf != null) {
if (theObject instanceof Configurable) {
((Configurable) theObject).setConf(conf);
}
setJobConf(theObject, conf);
}
}
在setConf()中,如果对象实现了Configurable接口,那么对象的setConf()方法会被调用,并根据Configuration类的实例conf进一步初始化对象。
[/size][/size][/size]