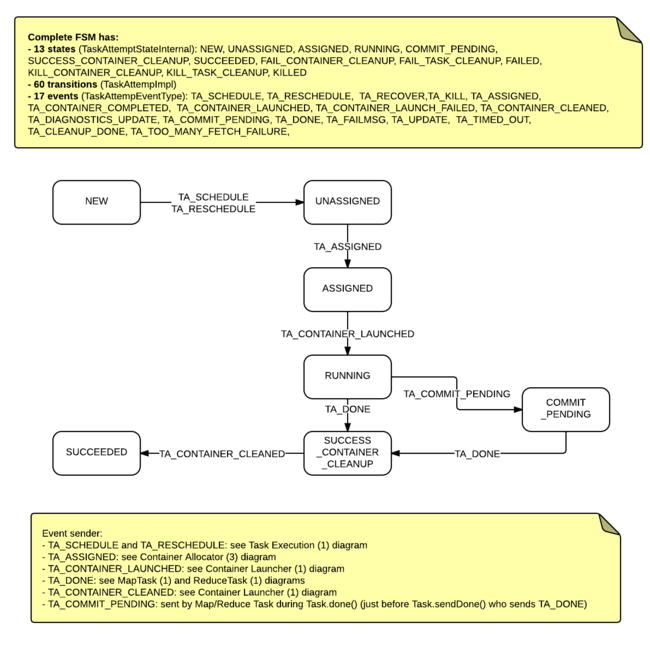
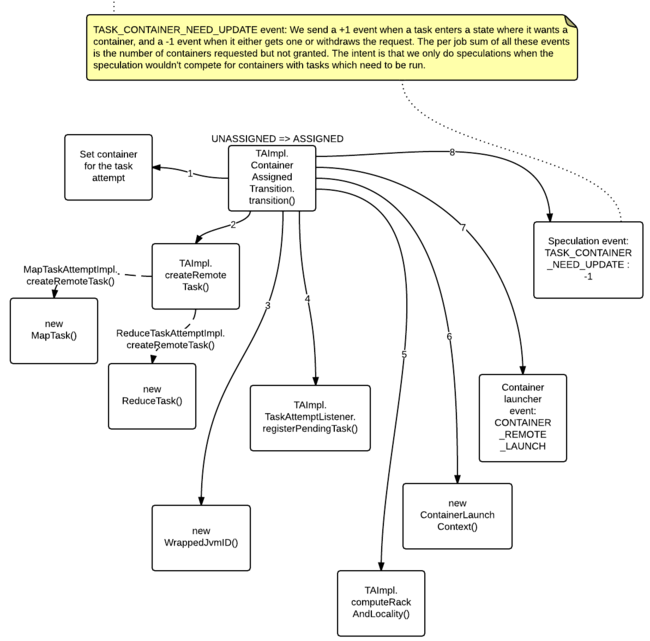
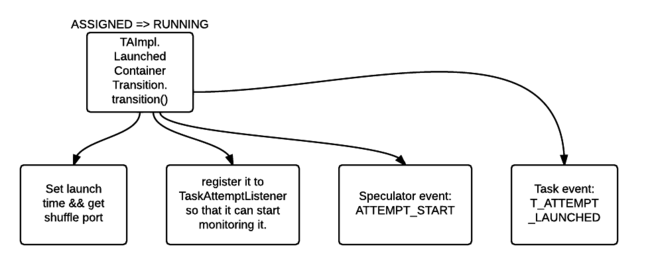
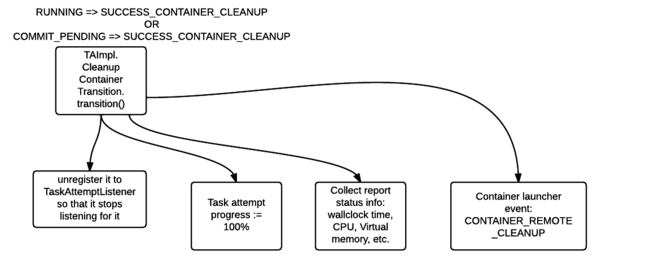
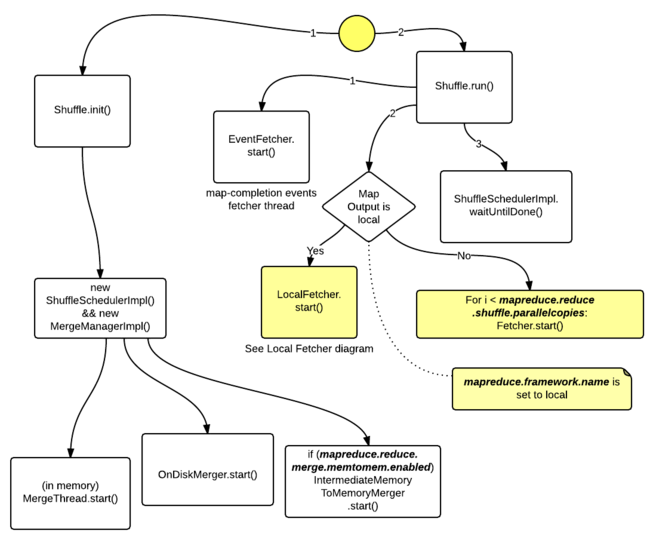
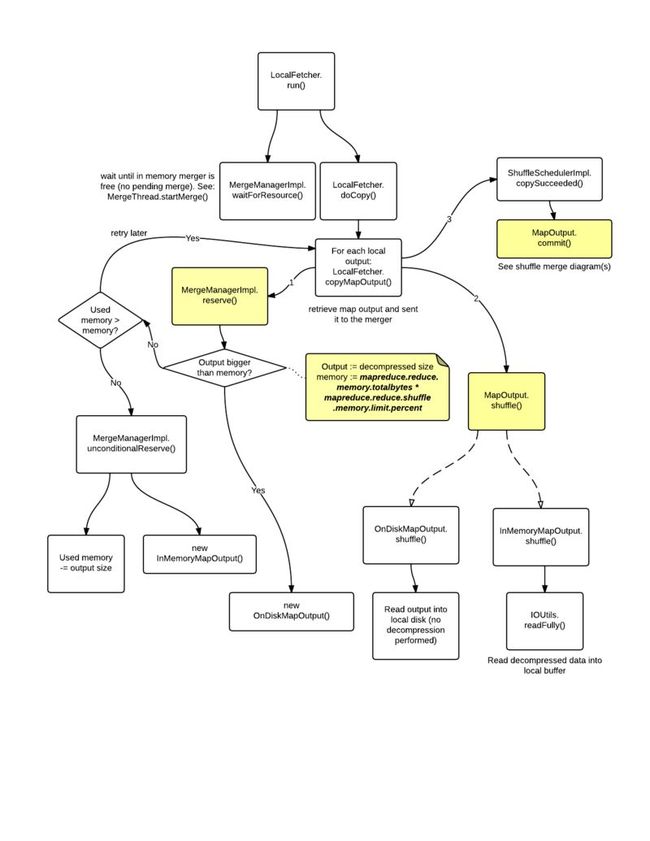
- hive 数字转换字符串_Hive架构及Hive SQL的执行流程解读
weixin_39756416
hive数字转换字符串
1、Hive产生背景MapReduce编程的不便性HDFS上的文件缺少Schema(表名,名称,ID等,为数据库对象的集合)2、Hive是什么Hive的使用场景是什么?基于Hadoop做一些数据清洗啊(ETL)、报表啊、数据分析可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。Hive是SQL解析引擎,它将SQL语句转译成M/RJob然后在Hadoop执行。由Facebook开源,
- mySQL和Hive的区别
iijik55
面试学习路线阿里巴巴hivemysql大数据tomcat面试
SQL和HQL的区别整体1、存储位置:Hive在Hadoop上;Mysql将数据存储在设备或本地系统中;2、数据更新:Hive不支持数据的改写和添加,是在加载的时候就已经确定好了;数据库可以CRUD;3、索引:Hive无索引,每次扫描所有数据,底层是MR,并行计算,适用于大数据量;MySQL有索引,适合在线查询数据;4、执行:Hive底层是MapReduce;MySQL底层是执行引擎;5、可扩展性
- Hadoop、Spark和 Hive 的详细关系
夜行容忍
hadoopsparkhive
Hadoop、Spark和Hive的详细关系1.ApacheHadoopHadoop是一个开源框架,用于分布式存储和处理大规模数据集。核心组件:HDFS(HadoopDistributedFileSystem):分布式文件系统,提供高吞吐量的数据访问。YARN(YetAnotherResourceNegotiator):集群资源管理和作业调度系统。MapReduce:基于YARN的并行处理框架,用
- 大数据面试之路 (一) 数据倾斜
愿与狸花过一生
大数据面试职场和发展
记录大数据面试历程数据倾斜大数据岗位,数据倾斜面试必问的一个问题。一、数据倾斜的表现与原因表现某个或某几个Task执行时间过长,其他Task快速完成。Spark/MapReduce作业卡在某个阶段(如reduce阶段),日志显示少数Task处理大量数据。资源利用率不均衡(如CPU、内存集中在某些节点)。常见场景Key分布不均:如某些Key对应的数据量极大(如用户ID为空的记录、热点事件)。数据分区
- Hadoop的运行模式
对许
#Hadoophadoop大数据分布式
Hadoop的运行模式1、本地运行模式2、伪分布式运行模式3、完全分布式运行模式4、区别与总结Hadoop有三种可以运行的模式:本地运行模式、伪分布式运行模式和完全分布式运行模式1、本地运行模式本地运行模式无需任何守护进程,单机运行,所有的程序都运行在同一个JVM上执行Hadoop安装后默认为本地模式,数据存储在Linux本地。在本地模式下调试MapReduce程序非常高效方便,一般该模式主要是在
- Hadoop的mapreduce的执行过程
画纸仁
大数据hadoopmapreduce大数据
一、map阶段的执行过程第一阶段:把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认Splitsize=Blocksize(128M),每一个切片由一个MapTask处理。(getSplits)第二阶段:对切片中的数据按照一定的规则读取解析返回对。默认是按行读取数据。key是每一行的起始位置偏移量,value是本行的文本内容。(TextInputFormat)第三阶段:调用Mapp
- Hadoop:分布式计算平台初探
dccrtbn6261333
大数据运维java
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop框架中最核心设计就是:MapReduce和HDFS。MapReduce提供了对数据的计算,HDFS提供了海量数据的存储。MapReduceMapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释M
- 探秘开源项目 MapReduce:分布式计算的新篇章
褚知茉Jade
探秘开源项目MapReduce:分布式计算的新篇章去发现同类优质开源项目:https://gitcode.com/在大数据处理领域,一个名字始终熠熠生辉,那就是。这是一个由Google提出的并被广泛应用的编程模型,用于大规模数据集的并行计算。本文将带你深入了解这一开源实现的魅力,分析其技术原理,探讨它的应用场景,并揭示它独特的特性。项目简介该项目是ChubbyJiang对原始GoogleMapRe
- MapReduce:分布式并行编程的基石
JAZJD
mapreduce分布式大数据
目录概述分布式并行编程分布式并行编程模型分布式并行编程框架MapReduce模型简介Map和Reduce函数Map函数Map函数的输入和输出Map函数的常见操作Reduce函数Reduce函数的输入和输出Reduce函数的常见操作工作流程概述各个阶段1.输入分片2.Map阶段3.Shuffle阶段4.Reduce阶段MapReduce工作流程总结Shuffle过程详解1.分区(Partitioni
- MapReduce:分布式计算的基石
Earth explosion
mapreduce大数据
MapReduce是一种用于处理和生成大数据集的编程模型,以及一个用于执行该模型的关联实现。它使得在大型商用硬件集群(数千台机器)上进行并行处理海量数据成为可能。本文将深入探讨MapReduce的核心概念、工作原理、应用场景以及一些高级主题。核心概念:分而治之MapReduce的核心思想是“分而治之”。它将复杂的计算任务分解成两个主要阶段:Map阶段和Reduce阶段。Map阶段:输入数据被分割成
- 【Hadoop】如何理解MapReduce?
2302_79952574
hadoopmapreduce数据库
MapReduce是一种用于处理大规模数据集的编程模型和计算框架。它的核心思想是将复杂的计算任务分解为两个简单的阶段:Map(映射)和Reduce(归约)。通过这种方式,MapReduce可以高效地并行处理海量数据。一.MapReduce的核心概念1.Map(映射):将输入数据分割成小块,并对每个小块进行初步处理。输出键值对(key-valuepairs),例如。2.Shuffle和Sort(洗牌
- Hadoop介绍:什么是Hadoop?了解Hadoop的应用
Zzzxt007
hadoop大数据分布式
一、认识Hadoop框架Hadoop是一个提供分布式存储和计算的开源软件框架,使用Java语言编写,具有高扩展性、高容错性、无共享和高可用(HA)等特点,非常适合处理海量数据。它基于Google发布的MapReduce论文实现,并且应用了函数式编程的思想。Hadoop框架主要包括HDFS(HadoopDistributedFileSystem,Hadoop分布式文件系统)、MapReduce、YA
- 【Hadoop】详解HDFS
2302_79952574
hadoophdfs大数据
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件上的分布式文件系统,它是一个高度容错性的系统,适合部署在廉价的机器上,能够提供高吞吐量的数据访问,非常适合大规模数据集上的应用。为了做到可靠性,HDFS创建了多份数据块的副本,并将它们放置在服务器群的计算节点中,MapReduce可以在它们所在的节点上处理这些数据。1.HDFS的设计目标存储大规模数据:HDFS可以存储并管理PB级甚至
- hadoop框架与核心组件刨析(四)MapReduce
小刘爱喇石( ˝ᗢ̈˝ )
hadoopmapreduce大数据
MapReduce是一种用于大规模数据处理的编程模型和计算框架,最初由Google提出,后来由ApacheHadoop实现并广泛应用。它的核心思想是将数据处理任务分解为两个阶段:Map和Reduce,并通过分布式计算并行处理海量数据。MapReduce的核心思想分而治之:将大规模数据集分割成多个小块,分布到集群中的多个节点上并行处理。Map阶段:将输入数据转换为键值对(Key-ValuePair)
- hadoop运行java程序命令_使用命令行编译打包运行自己的MapReduce程序 Hadoop2.6.0
emi0wb
网上的MapReduceWordCount教程对于如何编译WordCount.java几乎是一笔带过…而有写到的,大多又是0.20等旧版本版本的做法,即javac-classpath/usr/local/hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jarWordCount.java,但较新的2.X版本中,已经没有hadoop-core*.jar这个文件,因此编辑和打
- 大数据Hadoop集群运行程序
赵广陆
hadoophadoopbigdatamapreduce
目录1运行自带的MapReduce程序2常见错误1运行自带的MapReduce程序下面我们在Hadoop集群上运行一个MapReduce程序,以帮助读者对分布式计算有个基本印象。在安装Hadoop时,系统给用户提供了一些MapReduce示例程序,其中有一个典型的用于计算圆周率的Java程序包,现在运行该程序。该jar包文件的位置和文件名是“~/hadoop-3.1.0/share/Hadoop/
- 大数据面试系列之——Hadoop
潜心_守道
大数据面经面试大数据Hadoop
Hadoop的三个核心:HDFS(分布式存储系统)MapReduce(分布式计算系统)YARN(分布式资源调度)1.Hadoop集群的几种搭建模式1.单机模式:直接解压安装,不存在分布式存储系统2.伪分布式:NameNode和DataNode安装于同一个节点,无法体现分布式处理的优势。3.完全分布式:一个主节点,多个从节点,存在如果主节点宕机,集群就无法使用的缺点。4.高可用模式:多个主节点,多个
- hadoop
百里自来卷
hadoop大数据分布式
Hadoop是一个用于分布式存储和处理大规模数据的开源框架,它的架构主要由以下几个核心组件组成:1.Hadoop生态系统核心组件Hadoop的核心架构主要包括HDFS(HadoopDistributedFileSystem)和YARN(YetAnotherResourceNegotiator),以及MapReduce计算框架:1.1HDFS(分布式文件系统)HDFS负责存储大规模数据,采用主从架构
- 第一个Hadoop程序
lqlj2233
hadoop大数据分布式
编写和运行第一个Hadoop程序是学习Hadoop的重要步骤。以下是一个经典的“WordCount”程序示例,它统计文本文件中每个单词出现的次数。我们将使用Java编写MapReduce程序,并在Hadoop集群上运行它。一、WordCount程序概述WordCount是Hadoop的“HelloWorld”程序。它的基本逻辑如下:Mapper:读取输入文件,将每一行文本拆分为单词,并输出每个单词
- 【自学笔记】Hadoop基础知识点总览-持续更新
Long_poem
笔记hadoop大数据
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录Hadoop基础知识点总览1.Hadoop简介2.Hadoop生态系统3.HDFS(HadoopDistributedFileSystem)HDFS基本命令4.MapReduceWordCount示例(Java)5.YARN(YetAnotherResourceNegotiator)6.其他组件简介总结Hadoop基础知识点总
- Spark是什么?可以用来做什么?
Bugkillers
大数据spark大数据分布式
ApacheSpark是一个开源的分布式计算框架,专为处理大规模数据而设计。它最初由加州大学伯克利分校开发,现已成为大数据处理领域的核心工具之一。相比传统的HadoopMapReduce,Spark在速度、易用性和功能多样性上具有显著优势。一、Spark的核心特点速度快:基于内存计算(In-MemoryProcessing),比基于磁盘的MapReduce快10~100倍。支持高效的DAG(有向无
- 大数据面试临阵磨枪不知看什么?看这份心理就有底了-大数据常用技术栈常见面试100道题
大模型大数据攻城狮
大数据面试职场和发展面试题数据仓库算法
目录1描述Hadoop的架构和它的主要组件。2MapReduce的工作原理是什么?3什么是YARN,它在Hadoop中扮演什么角色?4Spark和HadoopMapReduce的区别是什么?5如何在Spark中实现数据的持久化?6SparkStreaming的工作原理是什么?7如何优化Spark作业的性能?8描述HBase的架构和它的主要组件。9HBase的读写流程是怎样的?10HBase如何处理
- Spark核心之06:知识点梳理
小技工丨
大数据技术学习SparkSQLspark大数据
spark知识点梳理spark_〇一1、spark是什么spark是针对于大规模数据处理的统一分析引擎,它是基于内存计算框架,计算速度非常之快,但是它仅仅只是涉及到计算,并没有涉及到数据的存储,后期需要使用spark对接外部的数据源,比如hdfs。2、spark四大特性1、速度快spark比mapreduce快的2个主要原因1、基于内存(1)mapreduce任务后期再计算的时候,每一个job的输
- Hadoop基础知识及部署模式
2301_82242502
hadoop大数据分布式
一、Hadoop是什么Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力,解决海量数据的存储及海量数据的分析计算问题。广义上的Hadoop是指Hadoop的整个技术生态圈;狭义上的Hadoop指的是其核心三大组件,包括HDFS、YARN及MapReduce.二、Hadoop的发展史Hadoop起源于Lucen
- 探讨Hadoop的基础架构及其核心特点
xx155802862xx
hadoop大数据分布式
Hadoop是一个开源软件框架,用于存储和处理大规模数据集。它是Apache软件基金会下的一个项目,灵感来源于Google的两篇论文:一篇关于Google文件系统(GFS),另一篇关于MapReduce。Hadoop设计用于从单台服务器扩展到数千台机器,每台机器提供局部计算和存储。而不仅仅是处理大数据,Hadoop的真正价值在于其对于数据的高容错性、可扩展性以及相对低成本的存储和处理能力。以下是探
- 大数据技术学习框架(更新中......)
小技工丨
大数据技术学习大数据学习
Hadoop相关HDFS分布式文件系统MR(MapReduce)离线数据处理MR-图解YARN集群资源管理ZooKeeperZooKeeper分布式协调框架Hive相关Hive-01之数仓、架构、数据类型、DDL、内外部表Hive-02之分桶表、数据导入导出、静动态分区、查询、排序、hiveserver2Hive-03之传参、常用函数、explode、lateralview、行专列、列转行、UDF
- 入门Apache Spark:基础知识和架构解析
juer_0001
javaspark
介绍ApacheSparkSpark的历史和背景ApacheSpark是一种快速、通用、可扩展的大数据处理引擎,最初由加州大学伯克利分校的AMPLab开发,于2010年首次推出。它最初设计用于支持分布式计算框架MapReduce的交互式查询,但逐渐发展成为一种更通用的数据处理引擎,能够处理数据流、批处理和机器学习等工作负载。Spark的特点和优势Spark是一种快速、通用、可扩展的大数据处理框架,
- jdbc连接数据库步骤oracle,jdbc连接oracle数据库的步骤
weixin_39726044
使用E-MapReduce集群sqoop组件同步云外Oracle数据库数据到集群hiveE-MapReduce集群sqoop组件可以同步数据库的数据到集群里,不同的数据库源网络配置有一些差异网络配置。最常用的场景是从rdsmysql同步数据,最近也有用户询问如何同步云外专有Oracle数据库数据到hive。云外专有数据库需要集群所有节点通过公网访问,要创建VPC网络,使用VPC网络...文章鸿初2
- spark为什么比mapreduce快?
京东云开发者
sparkmapreduce大数据
作者:京东零售吴化斌spark为什么比mapreduce快?首先澄清几个误区:1:两者都是基于内存计算的,任何计算框架都肯定是基于内存的,所以网上说的spark是基于内存计算所以快,显然是错误的2;DAG计算模型减少的是磁盘I/O次数(相比于mapreduce计算模型而言),而不是shuffle次数,因为shuffle是根据数据重组的次数而定,所以shuffle次数不能减少所以总结spark比ma
- HIVE 面试题总结
小余真旺财
Hivehive
Hive依赖于HDFS存储数据,Hive将HQL转换成MapReduce执行,所以说Hive是基于Hadoop的一个数据仓库工具,实质就是一款基于HDFS的MapReduce计算框架,对存储在HDFS中的数据进行分析和管理。一、Hive架构用户接口:CLI(hiveshell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)元数据:元数据包括:表名、表所属的数据库(默
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_