http://www.binospace.com/index.php/hdfs-ha-quorum-journal-manager/?utm_source=tuicool
1、背景
HDFS HA,即NameNode单点故障问题,一直是关系到HDFS稳定性最为重要的特性。之前Hadoop0.23初探系列文章中,介绍了HDFS的Federeation概况、配置与部署的情况,以及有关HA的相关概念。
HDFS HA的发展经历了如下几个阶段:
1)手动恢复阶段。手动备份fsimage、fsedits数据,NN故障之后,重启hdfs。这是最早期使用的办法,由于早期数据量、机器规模、以及对应用的影响还比较小,该方案勉强坚持了一段时间。
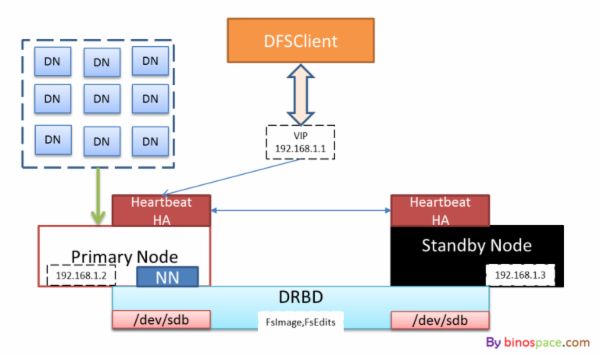
2)借助DRBD、HeartbeatHA实现主备切换。
使用DRBD实现两台物理机器之间块设备的同步,即通过网络实现Raid1,辅以Heartbeat HA实现两台机器动态角色切换,对外(DataNode、DFSClient)使用虚IP来统一配置。这种策略,可以很好地规避因为物理机器损坏造成的hdfs元数据丢失,(这里的元数据简单地说,就是目录树,以及每个文件有哪些block组成以及它们之间的顺序),但block与机器位置的对应关系仅会存储在NameNode的内存中,需要DataNode定期向NameNode做block report来构建。因此,在数据量较大的情况下,blockMap的重建过程也需要等待一段时间,对服务会有一定的影响。
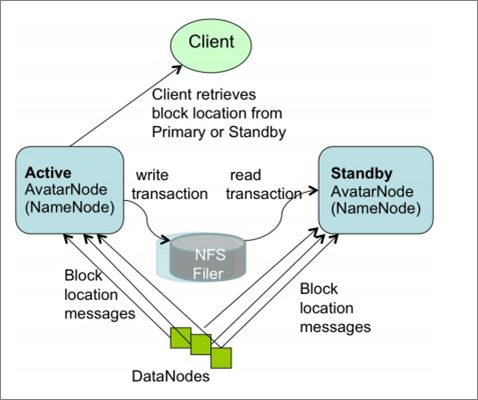
3)DataNode同时向主备NN汇报block信息。这种方案以Facebook AvatarNode为代表。
PrimaryNN与StandbyNN之间通过NFS来共享FsEdits、FsImage文件,这样主备NN之间就拥有了一致的目录树和block信息;而block的位置信息,可以根据DN向两个NN上报的信息过程中构建起来。这样再辅以虚IP,可以较好达到主备NN快速热切的目的。但是显然,这里的NFS又引入了新的SPOF。
在主备NN共享元数据的过程中,也有方案通过主NN将FsEdits的内容通过与备NN建立的网络IO流,实时写入备NN,并且保证整个过程的原子性。这种方案,解决了NFS共享元数据引入的SPOF,但是主备NN之间的网络连接又会成为新的问题。
总结:在开源技术的推动下,针对HDFS NameNode的单点问题,技术发展经历以上三个阶段,虽然,在一定程度上缓解了hdfs的安全性和稳定性的问题,但仍然存在一定的问题。直到hadoop2.0.*之后,Quorum Journal Manager给出了一种更好的解决思路和方案。
2 、 Quorum Journal Manager 原理
在一个典型的HA集群,两个独立的物理节点配置为NameNodes。在任何时间点,其中之一NameNodes是处于Active状态,另一种是在Standby状态。 Active NameNode负责所有的客户端的操作,而Standby NameNode尽用来保存好足够多的状态,以提供快速的故障恢复能力。
为了保证Active NN与Standby NN节点状态同步,即元数据保持一致。除了DataNode需要向两个NN发送block位置信息外,还构建了一组独立的守护进程”JournalNodes”,用来FsEdits信息。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上。而Standby NN负责观察JNs的变化,读取从Active NN发送过来的FsEdits信息,并更新其内部的命名空间。一旦ActiveNN遇到错误,Standby NN需要保证从JNs中读出了全部的FsEdits,然后切换成Active状态。
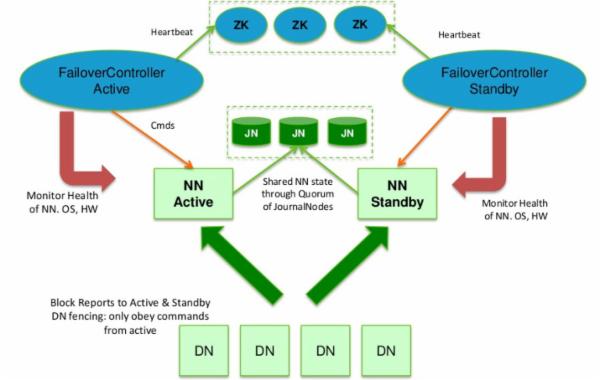
预防脑裂现象”Brain Split”。HA需要保证在任何一个时间点,最多只有一个NameNode处于Active状态。否则的话,在两个NN的NameSpace下的状态会出现分歧,从而引起数据丢失、或者其它不可预见的错误。为了预防该问题的发送,在任何时间点内JNs仅允许一个NN向其写FsEdits信息,保证故障迁移的正常执行。
3 、 HDFS HA — JQM 的配置
硬件资源:8台物理主机,hostname为GS-CIX-SEV0001~0008
软件版本:hadoop-2.0.5-alpha
系统配置目标:
1) 配置hbasecluster,commoncluster两个NameSpace,保证hbase集群和common集群命名空间的分离。
2) 对于每一个NameSpace下使用JQM配置HA。
3) 使用3个节点
系统环境清单:
系统设置两个NameSpace:hbasecluster, commoncluster
| hbasecluster |
commoncluster |
|
| NameNode |
GS-CIX-SEV0001, GS-CIX-SEV0002 |
GS-CIX-SEV0003, GS-CIX-SEV0004 |
| DataNode |
GS-CIX-SEV0001~0008 |
|
| JournalNode |
GS-CIX-SEV0001,GS-CIX-SEV0002,GS-CIX-SEV0003 |
|
| DFSZKFailoverController |
GS-CIX-SEV0001, GS-CIX-SEV0002 |
GS-CIX-SEV0003, GS-CIX-SEV0004 |
主要的配置文件有:hdfs-site.xml、core-site.xml
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.nameservices</name> <value>hbasecluster,commoncluster</value> </property> <property> <name>dfs.ha.namenodes.hbasecluster</name> <value>hnn1,hnn2</value> </property> <property> <name>dfs.ha.namenodes.commoncluster</name> <value>cnn1,cnn2</value> </property> <!--config rpc--> <property> <name>dfs.namenode.rpc-address.hbasecluster.hnn1</name> <value>GS-CIX-SEV0001:9100</value> </property> <property> <name>dfs.namenode.rpc-address.hbasecluster.hnn2</name> <value>GS-CIX-SEV0002:9100</value> </property> <property> <name>dfs.namenode.rpc-address.commoncluster.cnn1</name> <value>GS-CIX-SEV0003:9100</value> </property> <property> <name>dfs.namenode.rpc-address.commoncluster.cnn2</name> <value>GS-CIX-SEV0004:9100</value> </property> <!--config http-address--> <property> <name>dfs.namenode.http-address.hbasecluster.hnn1</name> <value>GS-CIX-SEV0001:50071</value> </property> <property> <name>dfs.namenode.http-address.hbasecluster.hnn2</name> <value>GS-CIX-SEV0002:50071</value> </property> <property> <name>dfs.namenode.http-address.commoncluster.cnn1</name> <value>GS-CIX-SEV0003:50071</value> </property> <property> <name>dfs.namenode.http-address.commoncluster.cnn2</name> <value>GS-CIX-SEV0004:50071</value> </property> <!-- qjournal config--> <!--dfs.namenode.shared.edits.dir dfs.namenode.shared.edits.dir--> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/lib/ssd/disk1/hadoop/hdfs/journal/</value> </property> <property> <name>dfs.namenode.shared.edits.dir.hbasecluster.hnn1</name> <value>qjournal://GS-CIX-SEV0001:8485;GS-CIX-SEV0002:8485;GS-CIX-SEV0003:8485/hbasecluster</value> </property> <property> <name>dfs.namenode.shared.edits.dir.hbasecluster.hnn2</name> <value>qjournal://GS-CIX-SEV0001:8485;GS-CIX-SEV0002:8485;GS-CIX-SEV0003:8485/hbasecluster</value> </property> <property> <name>dfs.namenode.shared.edits.dir.commoncluster.cnn1</name> <value>qjournal://GS-CIX-SEV0001:8485;GS-CIX-SEV0002:8485;GS-CIX-SEV0003:8485/commoncluster</value> </property> <property> <name>dfs.namenode.shared.edits.dir.commoncluster.cnn2</name> <value>qjournal://GS-CIX-SEV0001:8485;GS-CIX-SEV0002:8485;GS-CIX-SEV0003:8485/commoncluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.hbasecluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.client.failover.proxy.provider.commoncluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hbase/.ssh/id_rsa</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/var/lib/ssd/disk1/hadoop/hdfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/var/lib/ssd/disk1/hadoop/hdfs/data</value> <final>true</final> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration> core-site.xml: |
core-site.xml:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/var/lib/ssd/disk1/hadoop/tmp</value> <description>A base for other temporarydirectories.</description> </property> <property> <property> <name>hadoop.proxyuser.hbase.hosts</name> <value>GS-CIX-SEV0001.goso.com</value> <description>设置代理的主机</description> </property> <property> <name>hadoop.proxyuser.hbase.groups</name> <value>*</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hbasecluster</value> <description>设置默认前缀的形式,如果不设置的话,需要按照hdfs://${service_name}访问</description> </property> <property> <name>ha.zookeeper.quorum</name> <value>10.100.1.1:2181,10.100.1.2:2181,10.100.1.3:2181</value> <description>设置ha所依赖的zk-server的路径</description> </property> <property> <name>ha.zookeeper.parent-znode</name> <value>/hbase/hadoop-ha</value> <description>设置ha的zk路径</description> </property> </configuration> |
4 、 HDFS HA 启动过程
1) 设置HADOOP环境。
在${HADOOP_HOME_DIR}/etc/hadoop/hadoop-env.sh中设置:
export HADOOP_HOME=/opt/hadoop/hadoop/ #设置hadoop根目录
export JAVA_HOME=/usr/local/jdk1.6.0_38/ #设置jdk的环境
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop #设置hadoop conf目录
(ps:需要节点ssh无密码登录,具体方式可以参考网上内容)
按照本文第三部分的内容,根据自己环境配置hdfs-site.xml以及core-site.xml。
2) 启动JournalNodes。为此,可以准备如下的脚本。注意该部分不属于官方配置方式。
${HADOOP_HOME}/etc/hadoop/journalnodes 配置journalnodes
GS-CIX-SEV0001
GS-CIX-SEV0002
GS-CIX-SEV0003
启动脚本:${HADOOP_HOME}/start-journalnodes.sh
#!/bin/bash
bin=`dirname “${BASH_SOURCE-$0}”`
bin=`cd “$bin”; pwd`
DEFAULT_LIBEXEC_DIR=”$bin”/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hdfs-config.sh
JOURNAL_NODES=$(cat ${HADOOP_CONF_DIR}/journalnodes)
echo “Starting journal nodes [$JOURNAL_NODES]“
“$HADOOP_PREFIX/sbin/hadoop-daemons.sh” \
–config “$HADOOP_CONF_DIR” \
–hostnames “$JOURNAL_NODES” \
–script “$bin/hdfs” start journalnode
使用 sbin/start-journalnodes.sh启动JournaNodes。
3) 启动NameNode。
配置HA,需要保证ActiveNN与StandByNN有相同的NameSpace ID,在format一台机器之后,让另外一台NN同步目录下的数据。
配置Federation,需要在启动多个NameNode上format时,指定clusterid,从而保证2个NameService可以共享所有的DataNodes,否则两个NameService在fornat之后,生成的clusterid不一致,DataNode会随机注册到不同的NameNode上。如下所示:
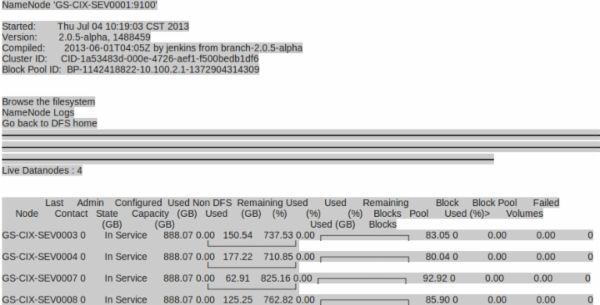
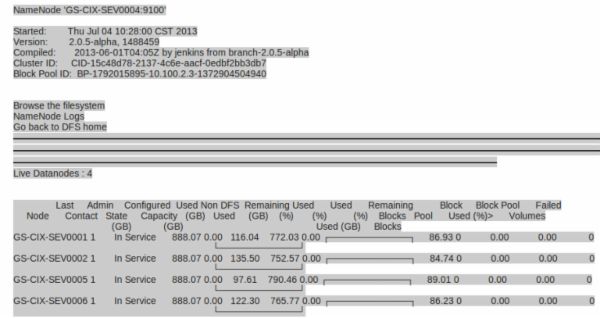
两个NameService下各出现了4个DataNodes,并没有达到DataNode共用的效果。因此在启动NN的过程中,需要按照如下的方式进行:
l 在hbasecluster的一台NN上执行:bin/hdfs namenode –format –clusterid cluster,然后启动NN,sbin/hadoop-daemon.sh start namenode
l 在hbasecluster的另外一台NN上执行:bin/hdfs namenode –bootstrapStandby 同步NN的文件,然后执行sbin/hadoop-daemon.sh start namenode
此时,hbasecluster上的2个NN都处于Standby状态,需要启动DFSZKFailoverController,该部分可以利用修改的sbin/start-dfs.sh启动。
对于commoncluster的两个NameNode,使用如上同样的方式进行启动。
4) 启动zkfc,具体的方式,可以参考sbin/start-dfs.sh提供的脚本进行。
5) 启动datanode,具体参见sbin/start-dfs.sh提供的启动方式。
启动之后,可以看到如下的目录结构。
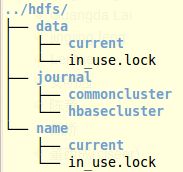
针对每一个NameService,在journal下有对应目录存储edits_***-***,而在name下是NameNode保存的本地fsimage和fsedits信息。
可以通过bin/hadoop fs –mkdir hdfs://hbasecluster/hbase
bin/hadoop fs –ls hdfs://hbasecluster/ 测试环境是否正常。
参考文献:
http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/HDFSHighAvailabilityWithQJM.html