HBase replication 代码分析
随着HBase的大规模应用,HBase的容灾显得特别的重要。
本文主要从代码层面分析HBase replication (基于HBase0.94.3)
分为正常replication处理逻辑和RS Fail两块。
1.正常replication处理逻辑
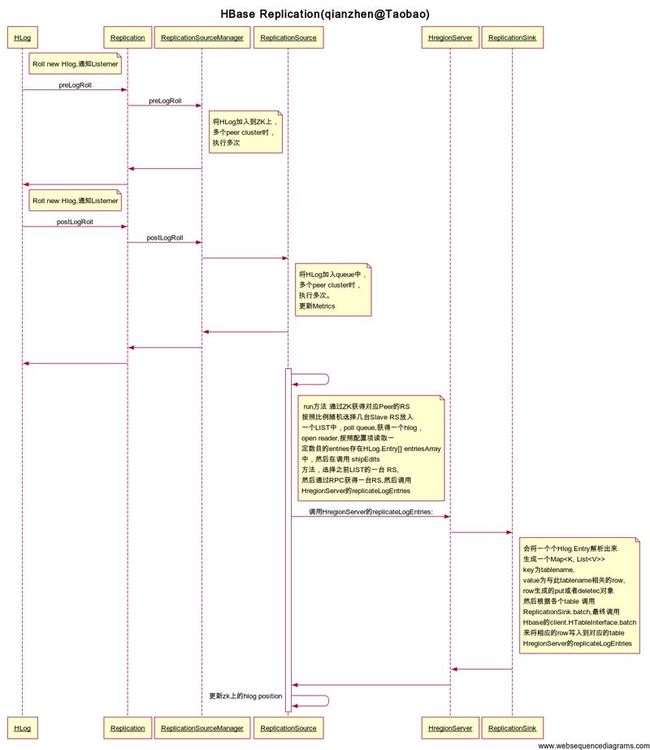
首先是HLog的rollwrite方法,调用prelogRoll, 在ZK上加上新的Hlog
再调用postlogRoll,调用Replication的postLogRoll
/**
* Gateway to Replication. Used by {@link org.apache.hadoop.hbase.regionserver.HRegionServer}.
*/
public class Replication implements WALActionsListener,
ReplicationSourceService, ReplicationSinkService {
Replication 实现了WALActionsListener接口,类似于提供给RS来调用的一些方法,类似于gateway.
当有新hlog生成时,会调用相应的方法来处理,在此方法中,
@Override
public void postLogRoll(Path oldPath, Path newPath) throws IOException {
getReplicationManager().postLogRoll(newPath);
Replication会调用ReplicationSourceManager的postLogRoll->ReplicationSource的enqueueLog方法,将新的hlog加入到一个queue中,同时更新Metrics, ReplicationSource是一个线程,负责读取,解析,发送和记录Hlog
,同时会根据replication ration来随机选择几台slave 集群的region servers来,然后将数据push到对应的RS上,若超过无法联系slave的RS,就认为此RS已经挂掉了。
在ReplicationSource的run中,通过ZK获得对应Peer的RS,按照比例随机选择几台Slave RS放入一个LIST中,poll queue,获得一个hlog,open reader,按照配置项读取一定数目的entries存在HLog.Entry[] entriesArray中,然后在调用 shipEdits方法,选择之前LIST的一台 RS,然后通过RPC获得一台RS,然后调用
HregionServer的replicateLogEntries,
HRegionInterface rrs = getRS();
LOG.debug("Replicating " + currentNbEntries);
rrs.replicateLogEntries(Arrays.copyOf(this.entriesArray, currentNbEntries));
在RS的 replicateLogEntries方法中,会调用RS的Replication.replicateLogEntries
this.replicationSinkHandler.replicateLogEntries(entries);
最终会调到ReplicationSink的replicateLogEntries方法,此方法中,会将一个个Hlog.Entry解析出来,生成一个Map>,key为tablename, value为与此tablename相关的row, row生成的put或者deletec对象,然后根据各个table 调用ReplicationSink.batch,最终调用 Hbase的client.HTableInterface.batch 来将
相应的row写入到对应的table。
调用HregionServer的replicateLogEntries方法完成后,会设置hlog的position
------
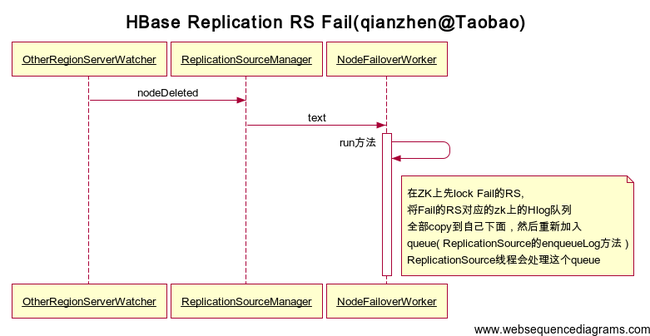
2.RS Fail
NodeFailoverWorker
OtherRegionServerWatcher.nodeDeleted -> ReplicationSourceManager.transferQueues-> NodeFailoverWorker.run
在run中,在ZK上先lock Fail的RS,将Fail的RS对应的zk上的Hlog队列全部copy到自己下面,然后重新加入queue( ReplicationSource的enqueueLog方法 )
本文主要从代码层面分析HBase replication (基于HBase0.94.3)
分为正常replication处理逻辑和RS Fail两块。
1.正常replication处理逻辑
首先是HLog的rollwrite方法,调用prelogRoll, 在ZK上加上新的Hlog
再调用postlogRoll,调用Replication的postLogRoll
/**
* Gateway to Replication. Used by {@link org.apache.hadoop.hbase.regionserver.HRegionServer}.
*/
public class Replication implements WALActionsListener,
ReplicationSourceService, ReplicationSinkService {
Replication 实现了WALActionsListener接口,类似于提供给RS来调用的一些方法,类似于gateway.
当有新hlog生成时,会调用相应的方法来处理,在此方法中,
@Override
public void postLogRoll(Path oldPath, Path newPath) throws IOException {
getReplicationManager().postLogRoll(newPath);
Replication会调用ReplicationSourceManager的postLogRoll->ReplicationSource的enqueueLog方法,将新的hlog加入到一个queue中,同时更新Metrics, ReplicationSource是一个线程,负责读取,解析,发送和记录Hlog
,同时会根据replication ration来随机选择几台slave 集群的region servers来,然后将数据push到对应的RS上,若超过无法联系slave的RS,就认为此RS已经挂掉了。
在ReplicationSource的run中,通过ZK获得对应Peer的RS,按照比例随机选择几台Slave RS放入一个LIST中,poll queue,获得一个hlog,open reader,按照配置项读取一定数目的entries存在HLog.Entry[] entriesArray中,然后在调用 shipEdits方法,选择之前LIST的一台 RS,然后通过RPC获得一台RS,然后调用
HregionServer的replicateLogEntries,
HRegionInterface rrs = getRS();
LOG.debug("Replicating " + currentNbEntries);
rrs.replicateLogEntries(Arrays.copyOf(this.entriesArray, currentNbEntries));
在RS的 replicateLogEntries方法中,会调用RS的Replication.replicateLogEntries
this.replicationSinkHandler.replicateLogEntries(entries);
最终会调到ReplicationSink的replicateLogEntries方法,此方法中,会将一个个Hlog.Entry解析出来,生成一个Map>,key为tablename, value为与此tablename相关的row, row生成的put或者deletec对象,然后根据各个table 调用ReplicationSink.batch,最终调用 Hbase的client.HTableInterface.batch 来将
相应的row写入到对应的table。
调用HregionServer的replicateLogEntries方法完成后,会设置hlog的position
------
2.RS Fail
NodeFailoverWorker
OtherRegionServerWatcher.nodeDeleted -> ReplicationSourceManager.transferQueues-> NodeFailoverWorker.run
在run中,在ZK上先lock Fail的RS,将Fail的RS对应的zk上的Hlog队列全部copy到自己下面,然后重新加入queue( ReplicationSource的enqueueLog方法 )