由于一些数据库重构项目的需求,最近遇到很多从SQL Server将表和数据迁移到MySQL的需求。这个需求说简单也简单,说麻烦也麻烦。前不久为了把一张大日志表成功导入到mysql,也折腾了不少时间。现在简单整理下实施方案。
首先是表结构的问题:
SQL Server中的部分字段类型不能直接沿用到MySQL,需要进行转换,主要有以下几种:
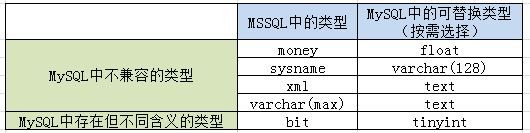
然后是数据迁移的问题:
数据迁移时,我们采取的是从SQL Server将数据导出为文本文件,然后将文本文件load到MySQL的方式(也尝试过通过etl工具直接迁移,例如SQL Server Integration Service,但是速度实在不理想)。用文本导入的话有几个需要考虑的问题:
- 为了保持SQL Server表中的null值,null值需要转化成\N导出;
- 由于反斜杠\在load data时是转义符,因此表数据中存有的反斜杠要进行替换变成\\,才能正确导入到MySQL;
- 由于源数据的字符类字段中可能本身就含有特殊字符,如换行符回车符等,在导出数据时需要使用特殊分隔符以区分字段和行。
假设要迁移的表syslog有如下字段:
| Column_name | Type | Nullable |
| id | int | no |
| Servername | varchar | yes |
| Dbname | varchar | yes |
| filename | varchar | yes |
| Filesize | varchar | yes |
| Backup_start_time | datetime | yes |
| Backup_end_time | datetime | yes |
那么在导出数据时可以用如下sql提取数据(有大于8000的数据可以转换成varchar(max)):
select id, case when Servername is null then '\N' else replace(convert(varchar(8000),Servername),'\','\\') end as Servername, case when Dbname is null then '\N' else replace(convert(varchar(8000),Dbname),'\','\\') end as Dbname, case when Filesize is null then '\N' else replace(convert(varchar(8000),Filesize),'\','\\') end as Filesize, case when Backup_start_time is null then '\N' else convert(varchar(8000),Backup_start_time,121) end as Backup_start_time, case when Backup_end_time is null then '\N' else convert(varchar(8000),Backup_end_time,121) end as Backup_end_time from syslog (nolock)
如果表字段很多,提取数据的sql写起来比较麻烦 ,那么可以通过下列语句直接从系统表中拼接语句:
select case is_nullable when 0 then 'replace(convert(varchar(8000),'+name+case system_type_id when 61 then ',121),''\'',''\\'')' else '),''\'',''\\'')' end+name
else 'case when '+name+' is null then ''\N'' else replace(convert(varchar(8000),'+name+case system_type_id when 61 then ',121),''\'',''\\'') end as ' else '),''\'',''\\'') end as ' end+name end +','
From sys.columns (nolock)
where object_id=object_id('syslog')
order by column_id
上述语句得到的结果是所有字段的转换后输出,加入select和from就可以得到完整的提取sql如下:
select replace(convert(varchar(8000),id),'\','\\')id, case when Servername is null then '\N' else replace(convert(varchar(8000),Servername),'\','\\') end as Servername, case when Dbname is null then '\N' else replace(convert(varchar(8000),Dbname),'\','\\') end as Dbname, case when Filesize is null then '\N' else replace(convert(varchar(8000),Filesize),'\','\\') end as Filesize, case when Backup_start_time is null then '\N' else replace(convert(varchar(8000),Backup_start_time,121),'\','\\') end as Backup_start_time, case when Backup_end_time is null then '\N' else replace(convert(varchar(8000),Backup_end_time,121),'\','\\') end as Backup_end_time from syslog (nolock)
这样由于简单的统一化处理,会对非字符类型字段做一些多余的replace,但不会对导出速度有太大影响。
生成好提取语句后,可以通过SQL Server的数据导入导出工具进行导出。
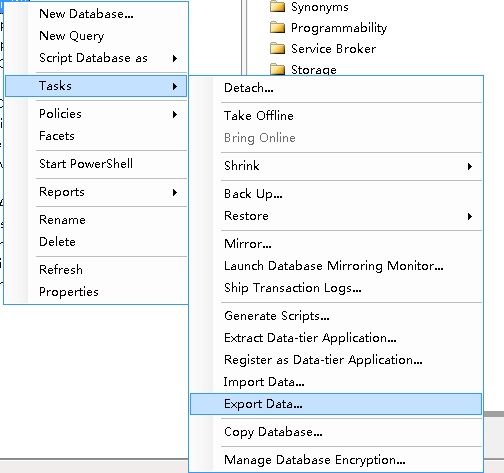
在源DB上右键,选择导出数据:
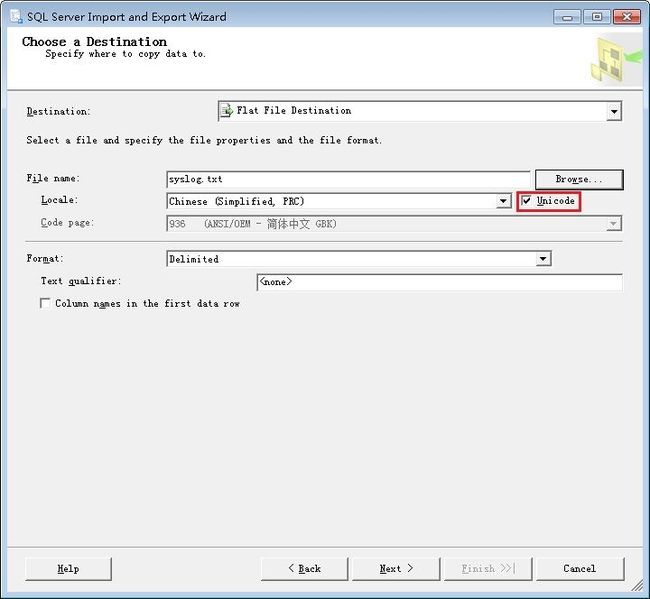
在导出源头输入正确的用户名密码后,导出的目的选择文本文件,并且为了保证中文字符正确迁移,最好采用unicode格式导出:
下一步后选择通过查询语句来转换数据:

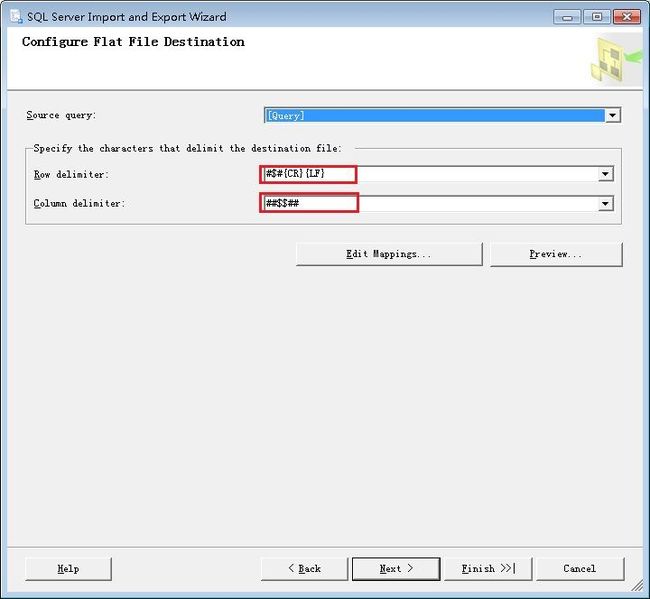
随后在下一窗口填入提取sql的语句,继续下一步到选择分隔符,这里使用特别的自定义分隔符作为行分隔符和列分隔符:
之后完成导出即可生成文件syslog.txt。
将导出的文本文件拷贝到mysql所在的linux服务器上后,先将文件进行转码,转为utf8格式:
iconv -f unicode -t utf8 syslog.txt -o syslog.raw
然后在mysql中进行load data,按照定义的特殊字符作为分隔(事先应该先把表结构创建好):
load data infile '/tmp/syslog.raw' into table syslog FIELDS TERMINATED BY '##$$##' LINES TERMINATED BY '#$#\r\n';
这样就能把数据完整地导入到MySQL中。