Data Guard理论概述(原创)
Data Gurad概述
不少未实际接触过dg的初学者可能会下意识以为data guard是一个备份恢复的工具。我要说的是,这种形容不完全错,dg拥有备份的功能,某些情况下它甚至可以与primary数据库完全一模一样,但是它存在的目的并不仅仅是为了恢复数据,应该说它的存在是为了 确保企业数据的高可用性,数据保护以及灾难恢复 ( 注意这个字眼,灾难恢复) 。dg提供全面的服务包括:创建,维护,管理以及监控standby数据库,确保数据安全,管理员可以通过将一些操作转移到standby数据库执行的方式改善数据库性能 ,构建高可用的企业数据库应用环境。
在Data Gurad 环境中,至少有两个数据库,一个处于Open 状态对外提供服务,这个数据库叫作Primary Database。 第二个处于恢复状态,叫作Standby Database。 运行时primary Database 对外提供服务,用户在Primary Database 上进行操作,操作被记录在联机日志和归档日志中,这些日志通过网络传递给Standby Database。 这个日志会在Standby Database 上重演,从而实现Primary Database 和Standby Database 的数据同步。
Oracle Data Gurad 对这一过程进一步的优化设计,使得日志的传递,恢复工作更加自动化,智能化,并且提供一系列参数和命令简化了DBA工作。
如果是可预见因素需要关闭Primary Database,比如软硬件升级,可以把Standby Database 切换为Primary Database 继续对外服务,这样即减少了服务停止时间,并且数据不会丢失。如果异常原因导致Primary Database 不可用,也可以把Standby Database 强制切换为Primary Database继续对外服务,这时数据损失都和配置的数据保护级别有关系。因此Primary 和Standby 只是一个角色概念,并不固定在某个数据库中。
Data Guard 架构
DG架构可以按照功能分成3个部分:
1) 日志发送(Redo Send)
2) 日志接收(Redo Receive)
3) 日志应用(Redo Apply)
1. 日志发送(Redo Send)
Primary Database 运行过程中,会源源不断地产生Redo 日志,这些日志需要发送到Standy Database。 这个发送动作可以由Primary Database 的LGWR 或者ARCH进程完成, 不同的归档目的地可以使用不同的方法,但是对于一个目的地,只能选用一种方法。 选择哪个进程对数据保护能力和系统可用性有很大区别。
1.1 使用ARCH 进程
1)Primary Database 不断产生Redo Log,这些日志被LGWR进程写到联机日志。
2)当一组联机日志被写满后,会发生日志切换(Log Switch),并且会触发本地归档,本地归档位置是采用 LOG_ARCHIVE_DEST_1='LOCATION=/path' 这种格式定义的。
如:alter system set log_archive_dest_1 = 'LOCATION=/u01/arch' scope=both;
3)完成本地归档后,联机日志就可以被覆盖重用。
4)ARCH 进程通过Net 把归档日志发送给Standby Database的RFS(Remote File Server) 进程。
5)Standby Database 端的RFS 进程把接收的日志写入到归档路径中。
6)Standby Database 端的MRP(Managed Recovery Process)进程(Redo Apply)或者LSP 进程(SQL Apply)在Standby Database上应用这些日志,进而同步数据。
参见下图
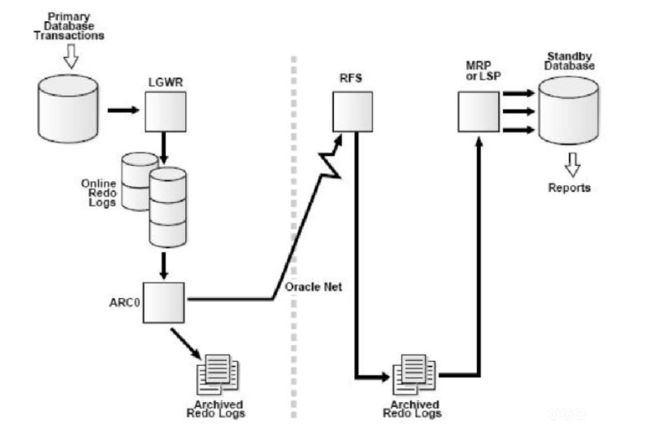
用ARCH模式传输不写Standby Redologs,直接保存成归档文件存放于Standby端。
说明:
逻辑Standby接收后将其转换成SQL语句,在Standby数据库上LSP进程执行SQL语句实现同步,这种方式叫SQL Apply。
物理Standby接收完Primary数据库生成的REDO数据后,MRP进程以介质恢复的方式实现同步,这种方式也叫Redo Apply。
注意:创建逻辑Standby数据库要先创建一个物理Standby数据库,然后再将其转换成逻辑Standby数据库。
使用ARCH进程传递最大问题在于: Primary Database 只有在发生归档时才会发送日志到Standby Database。 如果Primary Database 异常宕机,联机日志中的Redo内容就会丢失,因此使用ARCH 进程无法避免数据丢失的问题,要想避免数据丢失,就必须使用LGWR,而使用LGWR 又分SYNC(同步)和ASYNC(异步)两种方式。
在缺省方式下,Primary Database使用的是ARCH进程,参数设置如下:
alter system set log_archive_dest_2 = 'SERVICE=ST' scope=both;
1.2 使用LGWR 进程的SYNC 方式
1)Primary Database 产生的Redo日志要同时写到日志文件和网络。也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(Network Server Process),再由LNSn(LGWR Network Server process)进程把日志通过网络发送给远程的目的地,每个远程目的地对应一个LNS进程,多个LNS进程能够并行工作。
2)LGWR 必须等待写入本地日志文件操作和通过LNSn进程的网络传送都成功,Primary Database上的事务才能提交,这也是SYNC的含义所在。
3)Standby Database的RFS进程把接收到的日志写入到Standby Redo Log日志中。
4)Primary Database的日志切换也会触发Standby Database 上的日志切换,即Standby Database 对Standby Redo Log的归档,然后触发Standby Database 的MRP或者LSP进程恢复归档日志。
因为Primary Database 的Redo 是实时传递的,于是Standby Database 端可以使用两种恢复方法:
实时恢复(Real-Time Apply): 只要RFS把日志写入Standby Redo Log 就会立即进行恢复;
归档恢复: 在完成对Standby Redo Log 归档才触发恢复。
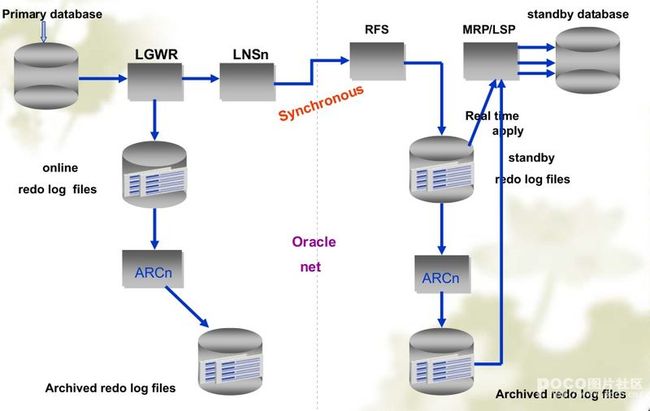
Primary Database默认使用ARCH进程,如果使用LGWR进程必须明确指定。使用LGWR SYNC方式时,可以同时使用NET_TIMEOUT参数,这个参数单位是秒,代表如果多长时间内网络发送没有响应,LGWR 进程会抛出错误。 示例如下:
alter system set log_archive_dest_2 = 'SERVICE=ST LGWR SYNC NET_TIMEOUT=30' scope=both;
1.3 使用LGWR进程的ASYNC 方式
使用LGWR SYNC方法的可能问题在于,如果日志发送给Standby Database过程失败,LGWR进程就会报错。也就是说Primary Database的LGWR 进程依赖于网络状况,有时这种要求可能过于苛刻,这时就可以使用LGWR ASYNC方式。 它的工作机制如下:
1) Primary Database 一段产生Redo日志后,LGWR 把日志同时提交给日志文件和本地LNS 进程,但是LGWR进程只需成功写入日志文件就可以,不必等待LNSn进程的网络传送成功。
2) LNSn进程异步地把日志内容发送到Standby Database。多个LNSn进程可以并发发送。
3) Primary Database的Online Redo Log 写满后发生Log Switch,触发归档操作,也触发Standby Database对Standby Database对Standby Redo Log 的归档;然后触发MRP或者LSP 进程恢复归档日志。
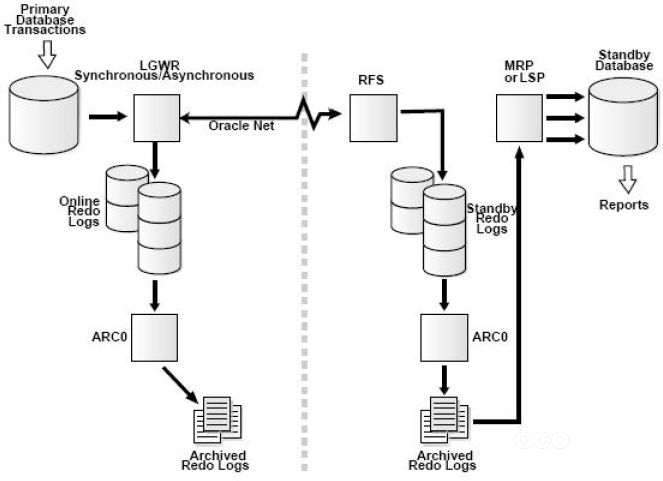
因为LGWR进程不会等待LNSn进程的响应结果,所以配置LGWR ASYNC方式时不需要NET_TIMEOUT参数。示例如下:
alter system set log_archive_dest_2 = 'SERVICE=ST LGWR ASYNC ' scope=both;
2. 日志接收(Redo Receive)
Standby Database 的RFS(Remote File Server)进程接收到日志后,就把日志写到Standby Redo Log或者Archived Log文件中,具体写入哪个文件,取决于Primary 的日志传送方式和Standby database的位置。如果写到Standby Redo Log文件中,则当Primary Database发生日志切换时,也会触发Standby Database上的Standby Redo Log 的日志切换,并把这个Standby Redo Log 归档。 如果是写到Archived Log,那么这个动作本身也可以看作是个归档操作。
在日志接收中,需要注意的是归档日志会被放在什么位置:
1) 如果配置了STANDBY_ARCHIVE_DEST参数,则使用该参数指定的目录。
2) 如果某个LOG_ARCHIVE_DEST_n 参数明确定义了VALID_FOR=(STANDBY_LOGFILE,*)选项,则使用这个参数指定的目录。
3) 如果数据库的COMPATIBLE参数大于等于10.0,则选取任意一个LOG_ARCHIVE_DEST_n的值。
4) 如果STANDBY_ARCHIVE_DEST 和 LOG_ARCHIVE_DEST_n 参数都没有配置,使用缺省的STANDBY_ARCHIVE_DEST参数值,这个缺省值是$ORACLE_HOME/dbs/arc.
3. 日志应用(Redo Apply)
日志应用服务,就是在Standby Database上重演Primary Database日志,从而实现两个数据库的数据同步。 根据Standby Database重演日志方式的不同,可分为物理Standby(Physical Standby)和逻辑Standby (Logical Standby)。
Physical Standby 使用的是Media Recovery 技术,在数据块级别进行恢复,这种方式没有数据类型的限制,可以保证两个数据库完全一致。 Physical Standby数据库只能在Mount状态下进行恢复,也可以是打开,但只能已只读方式打开,并且打开时不能执行恢复操作,即在打开状态下不能应用日志。
Logical Standby使用的是Logminer 技术,通过把日志内容还原成SQL 语句,然后SQL引擎执行这些语句,Logminer Standby不支持所有数据类型,可以在视图DBA_LOGSTDBY_UNSUPPORTED 中查看不支持的数据类型,如果使用了这种数据类型,则不能保证数据库完全一致。 Logical Standby数据库可以在恢复的同时进行读写操作。
Standby数据库的相关进程读取接收到的REDO数据(可能来自于Standby端的归档文件,也可能来自于Standby Redologs),再将其写入Standby数据库。保存之后数据又是怎么生成的呢?两种方式:物理Standby通过REDO应用,逻辑Standby通过SQL应用
根据Redo Apply发生的时间可以分成两种:
一种是实时应用(Real-Time Apply), 这种方式必须Standby Redo Log,每当日志被写入Standby Redo Log时,就会触发恢复,使用这种方式的好处在与可以减少数据库切换(Switchover 或者Failover)的时间,因为切换时间主要用在剩余日志的恢复上。
另一种是归档时应用,这种方式在Primary Database发生日志切换,触发Standby Database 归档操作,归档完成后触发恢复。 这也是默认的恢复方式。
如果是Physical Standby,可以使用下面命令启用Real-Time:
Alter database recover managed standby database using current logfile;
如果是Logical Standby,可以使用下面命令启用Real-Time:
Alter database start logical standby apply immediate;
查看是否使用Real-Time apply:
Select recovery_mode from v$archive_dest_status;
上文提到了物理Standby和逻辑Standby,下面我们来详细介绍下这两类standby数据库。
物理Standby
我们知道物理Standby与Primary数据库完全一模一样,DG通过REDO应用来维护物理Standby数据库。
通常在物理Standby没有执行REDO应用操作的时候,可以将物理Standby数据库以READ ONLY模式打开,如果数据库中指定了Flashback Area的话,甚至还可以被临时性的置为READ WRITE模式,操作完之后再通过Flashback Database特性恢复回READ WRITE前的状态,以便继续接收Primary端发送的REDO并应用。
物理Standby通过REDO应用来保持与Primary数据库的一致性,所谓的REDO应用,实质是通过Oracle的恢复机制,应用归档文件(或Standby Redologs文件)中的REDO数据。 恢复操作属于块对块的应用 。如果正在执行REDO应用的操作,Oracle数据库就不能被Open。
READ ONLY模式打开。以READ ONLY模式打开后,可以在Standby数据库执行查询或备份等操作(变相减轻Primary数据库压力)。此时Standby数据库仍然能够继续接收Primary数据库发送的REDO数据,不过并不会应用,直到Standby数据库重新恢复REDO应用。
也就是说在READ ONLY模式下不能执行REDO应用,REDO应用时数据库肯定处于未打开状态。如果需要的话,你可以在两种状态间转换,如先应用REDO,然后将数据库置为READ ONLY状态,需要与Primary同步时再次执行REDO应用命令,切换回REDO应用状态.
说明: Oracle 11g版本中增强物理Standby的应用功能,在11g版本中,物理Standby可以在OPEN READ ONLY模式下继续应用REDO数据,这就极大地提升了物理Standby数据库的应用场合。
READ WRITE模式打开。如果以READ WRITE模式打开,那么Standby数据库将暂停从Primary数据库接收REDO数据,并且暂时失去灾难保护的功能。当然,以READ WRITE模式打开也并非一无是处,如你可能需要临时调试一些数据,但又不方便在正式库中操作,那就可以临时将Standby数据库置为READ WRITE模式,操作完之后将数据库闪回到操作前的状态(闪回之后,Data Guard会自动同步,不需要重建物理Standby,不过如果从另一个方向看,没有启动闪回,那就回不到READ WRITE前的状态了)。
物理Standby特点如下:
(1)灾难恢复及高可用性。物理Standby提供了一个健全、高效的灾难恢复,以及高可用性的解决方案。更加易于管理switchover/failover角色转换及在更短的计划内或计划外停机时间。
(2)数据保护。使用物理Standby数据库,DG能够确保即使面对无法预料的灾害也能够不丢失数据。前面也提到物理Standby是基于块对块的复制,因此与对象、语句无关,Primary数据库上有什么,物理Standby数据库端也会有什么。
(3)分担Primary数据库压力。通过将一些备份任务、仅查询的需求转移到物理Standby数据库,可以有效节省Primary数据库的CPU及I/O资源。
(4)提升性能。物理Standby所使用的REDO应用技术使用最底层的恢复机制,这种机制能够绕过SQL级代码层,因此效率最高。
逻辑Standby
逻辑Standby也要通过Primary数据库(或其备份,或其复制库,如物理Standby)创建,因此在创建之初与物理Standby数据库类似。不过由于逻辑Standby通过SQL应用的方式应用REDO数据,因此逻辑Standby的物理文件结构,甚至数据的逻辑结构都可以与Primary不一致。
与物理Standby不同,逻辑Standby正常情况下是以READ WRITE模式打开,用户可以在任何时候访问逻辑Standby数据库,就是说逻辑Standby是在OPEN状态执行SQL应用。 注意:逻辑Standby虽然是以READ WRITE模式打开并应用REDO数据,不过被维护的对象默认处于只读状态,无法在逻辑Standby端直接修改。对于逻辑standby 同样有利也有弊,由于SQL应用自身特点,逻辑Standby对于某些数据类型及一些DDL/DML语句会有操作上的限制。可以在视图DBA_LOGSTDBY_UNSUPPORTED 中查看不支持的数据类型,如果使用了这种数据类型,则不能保证数据库完全一致。
逻辑Standby 的读写打开可以使它做报表系统,这样减轻系统的压力。
除了上述物理Standby中提到的类似灾难恢复、高可用性及数据保护等特点之外,逻辑Standby还有下列一些特点:
(1)有效地利用备机的硬件资源。除灾难恢复外,逻辑Standby数据库还可用于其他业务需求。如通过在Standby数据库创建额外的索引、物化视图等提高查询性能并满足特定业务需要;又如创建新的SCHEMA(该SCHEMA在Primary数据库端并不存在),然后在这些SCHEMA中执行那些不适于在Primary数据库端执行的DDL或者DML操作等。
(2)分担Primary数据库压力。逻辑Standby数据库可以在保持与Primary同步时仍然置于打开状态,这使得逻辑Standby数据库能够同时用于数据保护和报表操作,从而将主数据库从报表和查询任务中解脱出来,节约宝贵的CPU和I/O资源。
(3)平滑升级。可以通过逻辑Standby来实现如跨版本升级,为数据库打补丁等操作。应该说应用的空间很大,而带来的风险却很小(前提是如果你拥有足够的技术实力。另外虽然物理Standby也能够实现一些升级操作,但如果跨平台的话恐怕就力不从心了,所以此项没有作为物理Standby的特点列出),我个人认为这是一种值得可行的在线的滚动的平滑的升级方式,如果你的应用支持创建逻辑Standby的话。
数据保护模式
Data Guard 允许定义3钟数据保护模式,分别是最大保护(Maximum Protection),最大可用(Maximum Availability)和 最大性能(Maximum Performance)
最大保护(Maximum Protection)
这种模式能够确保绝无数据丢失。要实现这一步当然是有代价的,它要求所有的事务在提交前其REDO不仅被写入到本地的Online Redologs,还要同时写入到Standby数据库的Standby Redologs,并确认REDO数据至少在一个Standby数据库中可用(如果有多个的话), 然后才会在Primary数据库上提交事物 。如果出现了什么故障导致Standby数据库不可用的话(比如网络中断),Primary数据库会被Shutdown,以防止数据丢失。
使用这种方式要求Standby Database 必须配置Standby Redo Log,而Primary Database必须使用LGWR,SYNC,AFFIRM 方式归档到Standby Database.
这里解释下AFFIRM: AFFIRM仅当重做数据被写入到备用重做日志后,目标才确认已收到,含有SYNC含义。NOAFFIRM当重做数据写入到备用重做日志前目标就可以确认收到,含有ASYNC含义。
最高可用性(Maximum availability)
这种模式在不影响Primary数据库可用前提下,提供最高级别的数据保护策略。其实现方式与最大保护模式类似,也是要求本地事务在提交前必须至少写入一台Standby数据库的Standby Redologs中,不过与最大保护模式不同的是,如果出现故障导致Standby数据库无法访问,Primary数据库并不会被Shutdown,而是自动转为最高性能模式,等Standby数据库恢复正常之后,Primary数据库又会自动转换成最高可用性模式。
这种方式虽然会尽量避免数据丢失,但不能绝对保证数据完全一致。这种方式要求Standby Database 必须配置Standby Redo Log,而Primary Database必须使用LGWR,SYNC,AFFIRM 方式归档到Standby Database.
最高性能(Maximum performance)
缺省模式。 这种模式在不影响Primary数据库性能前提下,提供最高级别的数据保护策略。事务可以随时提交,当前Primary数据库的REDO数据至少需要写入一个Standby数据库,不过这种写入可以是不同步的。如果网络条件理想的话,这种模式能够提供类似最高可用性的数据保护,而仅对Primary数据库的性能有轻微影响。这也是创建Standby数据库时,系统的默认保护模式。这种方式可以使用LGWR ASYNC 或者 ARCH 进程实现,Standby Database也不要求使用Standby Redo Log。
参考至:《大话Oracle RAC》 张晓明著
http://www.5ienet.com/note/html/dg/dataguard-basic-what-is-dataguard.shtml
http://blog.csdn.net/tianlesoftware/article/details/5514082
http://wenku.baidu.com/view/90a5f0270722192e4536f6b6.html
http://wenku.baidu.com/view/8e797bebe009581b6bd9eb3a.html
http://oracle.chinaitlab.com/backup/784910.html
本文原创,转载请注明出处、作者
如有错误,欢迎指正