本文查阅方法:
1、查阅目录 —— 查阅本文目录,确定想要查阅的目录标题
2、快捷“查找” —— 在当前浏览器页面,按键 “Ctrl+F” 按键组合,开启浏览器的查找功能,
在查找搜索框中 输入需要查阅的 目录标题,便可以直接到达 标题内容 的位置。
3、学习小结 —— 文中的学习小结内容,是笔者在学习之后总结出的,开发时可直接参考其进行应用开发的内容, 进一步加快了本文的查阅 速度。(水平有限,仅供参考。)
本文目录
学习小结
1、JAXP概述
2、获得JAXP中的DOM解析器
3、使用DOM解析Xml文档
4、写回数据/更新XML文档
5、DOM编程中的几个名词术语
6、DOM方式解析XML文件——流程范例Demo
A.DOM解析——获得Dom解析器:
B.更新/写回数据到原Xml文档。(共三个步骤)
C.遍历所有节点
D.查找某一个节点
E.向xml文档中添加新节点
F.读取指定标签属性的值:
G.向xml文档中指定位置上添加新节点
H.向xml文档中指定节点添加属性
I.删除xml文档中的指定节点
J.删除2: 删除指定节点所在的父结点
K.更新指定节点的文本内容
7、Jaxp的SAX解析方式概述
8、SAX解析原理剖析
9、JDK文档中对Sax解析方式的描述(图解)
10、SAX方式解析XML文档的流程
(1)使用SAX解析Xml文档
(2)样例Demo1:编写处理器——获取整个xml文档内容的处理器
(3)样例Demo2:编写处理器—— 获取到指定位置序列标签的值 以及属性值
(4)样例Demo3:编写处理器—— 把Xml文档的数据封装到JavaBean的处理器
11、编写SAX处理器的流程与注意事项:
12、SAX 方式解析XML文件——流程范例Demo
相关文章
XML文档语法 学习笔记
地址:http://even2012.iteye.com/blog/1828064
DTD约束 —— Xml文档 约束技术 学习笔记
地址:http://even2012.iteye.com/blog/1828290
Schama —— Xml文档约束技术 学习笔记
地址:http://even2012.iteye.com/blog/1832073
Dom4j 解析Xml文档及 XPath查询 学习笔记
地址:http://even2012.iteye.com/blog/1832068
Jaxp :Dom解析Xml文档和SAX解析Xml文档学习笔记
地址:http://even2012.iteye.com/blog/1829981
学习小结
(1)Jaxp —— Dom 解析Xml文档流程[共三个大步骤]
A. 解析XML文档:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //得到工厂。
DocumentBuilder builder = factory.newDocumentBuilder(); //得到Dom解析器。
Document document = builder.parse("src/book.xml"); //得到Dom文档。
B. Dom编程:对Dom树中的Node、Element、Text、Attr等元素进行增、删、改、查的操作
a. 获得目标节点:Node node=document.getElementsByTagName.item(0);
b. 应用该节点进行各种CRUD的操作。
【备注:重点是先获取超级父类Node节点,进行操作,找不到合适的操作方法时,
可将其强转成其他对应的子节点,应用子类中更多的、有针对性的方法进行操作。】
C. 更新/写回 XMl文档:
TransformerFactory factory = TransformerFactory.newInstance(); //得到工厂。
Transformer tf = factory.newTransformer(); //得到转换器。
tf.transform(new DOMSource(document), //实例对象document是原来解析获得Dom对象。
new StreamResult(new FileOutputStream("src/book.xml"))); //输出到目标文件。
(2)Jaxp —— SAX解析Xml文档流程。[共两个大步骤]
A. 使用SAX解析Xml文档
SAXParserFactory factory = SAXParserFactory.newInstance(); //1.创建产生解析器的工厂
SAXParser parser = factory.newSAXParser(); //2.创建解析器
XMLReader reader = parser.getXMLReader(); //3.得到xml文档读取器
reader.setContentHandler(new BookNameHandler()); //4.为读取器设置内容处理器
reader.parse("src/book.xml"); //5.利用读取器解析xml文档
B. 编写处理器——实现所需要的功能。
a. 新建类,并继承DefaultHandler 类
b. 覆盖startElement(...)、characters(...)、endElement(...) 这三个方法,并在里面编写代码实现功能。
1、JAXP概述
JAXP 开发包是J2SE的一部分,它由javax.xml、org.w3c.dom 、org.xml.sax 包及其子包组成
在 javax.xml.parsers 包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的 DOM 或 SAX 的解析器对象。
【小知识:改JVM虚拟内存(默认值:64m),防止Dom解析时造成内存溢出】
命令行: java -Xmx566m
MyEclipse--》VM参数:-Xmx566m
2、获得JAXP中的DOM解析器
javax.xml.parsers 包中的DocumentBuilderFactory用于创建DOM模式的解析器对 象 , DocumentBuilderFactory是一个抽象工厂类,它不能直接实例化,但该类提供了一个newInstance()静态方法 ,这 个方法会根据本地平台默认安装的解析器,自动创建一个工厂的对象并返回。
3、使用DOM解析Xml文档
a. 调用 DocumentBuilderFactory.newInstance() 方法得到创建 DOM 解析器的工厂。
b. 调用工厂对象的 newDocumentBuilder()方法得到 DOM 解析器对象。
c. 调用 DOM 解析器对象的 parse() 方法解析 XML 文档,得到代表整个文档的 Document 对象,进而可以利用DOM特性对整个XML文档进行操作了。
本例Demo见:标题“ 7、DOM方式解析XML文件” 中的范例
4、写回数据/更新XML文档
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,
例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写入到一个XML文件中。
(1)Transformer类通过transform(...)方法完成转换操作,该方法接收一个源和一个目的地。
(2)源document:javax.xml.transform.dom.DOMSource类来关联要转换的document对象,
(3)目的地文件:用javax.xml.transform.stream.StreamResult 对象来表示数据的目的地。
(4)Transformer对象通过TransformerFactory获得。
本例Demo见:标题“ 7、DOM方式解析XML文件” 中的范例
5、DOM编程中的几个名词术语
(1)DOM模型(document object model)
(2)节点类型(Node对象)
a.DOM解析器在解析XML文档时,会把文档中的所有元素,按照其出现的层次关系,解析成一个个Node对象(节点)。
b.Node对象提供了一系列常量来代表结点的类型,当开发人员获得某个Node类型后,就可以把Node节点转换成相应的节点对象(Node的子类对象,如:Element,Attr,Text等),以便于调用其特有的方法。(查看API文档)
c.Node对象提供了相应的方法去获得它的父结点或子结点。编程人员通过这些方法就可以读取整个XML文档的内容、或添加、修改、删除XML文档的内容了。
(3)在dom中,节点之间关系如下:
A. parent ———— 位于一个节点之上的节点是该节点的父节点(parent)
B. children ——— 一个节点之下的节点是该节点的子节点(children)
C. sibling ——— 同一层次,具有相同父节点的节点是兄弟节点(sibling[ˈsɪblɪŋ])
D. descendant —— 一个节点的下一个层次的节点集合是节点后代(descendant[diˈsendənt] )
E. ancestor ——— 父、祖父节点及所有位于节点上面的,都是节点的祖先(ancestor[ˈænsistə] )
6、DOM方式解析XML文件——流程范例Demo
A.DOM解析——获得Dom解析器:
Demo:
//得到dom解析器(共三个步骤)
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //得到工厂。
DocumentBuilder builder = factory.newDocumentBuilder(); //得到Dom解析器。
Document document = builder.parse("src/book.xml"); //得到Dom文档。
B.更新/写回数据到原Xml文档。(共三个步骤)
Demo:
//把内存中更新后对象树,重新定回到xml文档中
TransformerFactory factory = TransformerFactory.newInstance(); //得到工厂。
Transformer tf = factory.newTransformer(); //得到转换器。
tf.transform(new DOMSource(document), //实例对象document是原来解析获得Dom对象。
new StreamResult(new FileOutputStream("src/book.xml"))); //输出到目标文件。
C.遍历所有节点
Demo:
@Test
public void listXml() throws ParserConfigurationException, SAXException, Exception{
list(document);
}
public void list(Node node){
System.out.println(node.getNodeName());
NodeList list = node.getChildNodes();
for(int i=0;i<list.getLength();i++){
Node child = list.item(i);
list(child);
}
}
D.查找某一个节点
Demo:
//读取书名节点的值:<书名>javaweb开发</书名>
@Test
public void test1(){
//得到dom解析器: 略...
Node node = document.getElementsByTagName("书名").item(0);
String value = node.getTextContent();
System.out.println(value);
}
E. 向xml文档中添加新节
Demo:
@Test
public void test3() throws Exception{
//得到dom解析器: 略...
//创建要挂的节点
Element price = document.createElement("售价");
price.setTextContent("59元");
//把创建的结点挂到书节点下
Node book = document.getElementsByTagName("书").item(0);
book.appendChild(price);
//把内存中更新后对象树,重新定回到xml文档中:略。。。
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document),
new StreamResult(new FileOutputStream("src/book.xml")));
}
F.读取指定标签属性的值::
Demo:
@Test //<售价 type="rmb">39.00元</售价>
public void test2(){
//得到dom解析器: 略...
Node node = document.getElementsByTagName("售价").item(0);
Element price = (Element) node; //发现node满足不了,把node强转成相应类型
String attValue = price.getAttribute("type");
System.out.println(attValue);
}
G.向xml文档中指定位置上添加新节点
Demo:
@Test
public void test4() throws Exception{
//得到dom解析器: 略...
//创建要添加的节点
Element price = document.createElement("售价");
price.setTextContent("59元");
//得到要向哪个节点上挂子节点
Node book = document.getElementsByTagName("书").item(0);
//向参考节点前,挂新节点
book.insertBefore(price, document.getElementsByTagName("售价").item(0));
//把内存中更新后对象树,重新定回到xml文档中
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document),
new StreamResult(new FileOutputStream("src/book.xml")));
}
H.向xml文档中指定节点添加属性
Demo:
@Test
public void test5() throws Exception{
//得到dom解析器: 略...
//得到要添加属性的节点
Element author = (Element) document.getElementsByTagName("作者").item(0);
author.setAttribute("id", "12"); //向节点挂属性
//把内存中更新后对象树,重新定回到xml文档中
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document),
new StreamResult(new FileOutputStream("src/book.xml")));
}
I.删除xml文档中的指定节点
Demo:
@Test
public void test6() throws Exception{
//得到dom解析器: 略...
//得到要删除的节点
Node price = document.getElementsByTagName("售价").item(0);
//得到要删除的节点的父亲
Node parent = document.getElementsByTagName("书").item(0);
parent.removeChild(price);
//把内存中更新后对象树,重新定回到xml文档中
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document),
new StreamResult(new FileOutputStream("src/book.xml")));
}
J.删除2: 删除指定节点所在的父结点
Demo:
@Test
public void test7() throws Exception{
//得到dom解析器: 略...
//得到要删除的节点
Node price = document.getElementsByTagName("售价").item(0);
price.getParentNode().getParentNode().removeChild(price.getParentNode());
//把内存中更新后对象树,重新定回到xml文档中
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document),
new StreamResult(new FileOutputStream("src/book.xml")));
}
K.更新指定节点的文本内容:
Demo:
@Test
public void test8() throws Exception{
//得到dom解析器: 略...
document.getElementsByTagName("售价").item(1).setTextContent("19元");
//把内存中更新后对象树,重新定回到xml文档中
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document),
new StreamResult(new FileOutputStream("src/book.xml")));
}
G.附 book.xml 文件内容:
<?xml version="1.0" encoding="UTF-8"?><书架>
<书>
<书名>javaweb开发</书名>
<作者 id="12">张孝祥</作者>
<售价>59元</售价>
<售价 type="rmb">19元</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
</书架>
7、Jaxp的SAX解析方式概述
DOM 解析的缺点—— 在使用 DOM 解析 XML 文档时,需要读取整个 XML 文档,在内存中构架代表整个 DOM 树的Doucment对象,从而再对XML文档进行 操作。此种情况下,如果 XML 文档特别大,就会消耗计算机的大量内存,并且容易导致内存溢出。
SAX解析的特点—— SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会文档进行操作。
8、SAX解析原理剖析
SAX采用事件处理的方式解析XML文件,利用 SAX 解析 XML 文档,涉及两个部分:解析器和事件处理器:
(1)解析器——可以使用JAXP的API创建,创建出SAX解析器后,就可以指定解析器去解析某个XML文档。解析器采用SAX方式在解 析某个XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用事件处理器的方法时,会把当前解析到的xml 文件内容作为方法的参数传递给事件处理器。
(2)事件处理器——由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松地得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
9、JDK文档中对Sax解析方式的描述(图解)
备注:阅读ContentHandler API文档,常用方法:startElement、endElement、characters
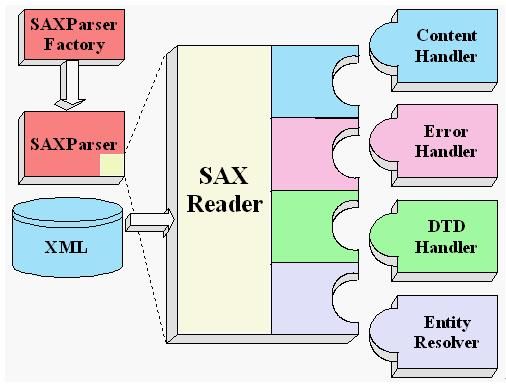
10、SAX方式解析XML文档的流程
(1)使用SAXParserFactory创建SAX解析工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
(2) 通过SAX解析工厂得到解析器对象
SAXParser sp = spf.newSAXParser();
(3) 通过解析器对象得到一个XML的读取器
XMLReader xmlReader = sp.getXMLReader();
(4) 设置读取器的事件处理器
xmlReader.setContentHandler(new BookParserHandler()); //实现不同的功能,需要设置可提供相应功能的处理。
(5) 解析xml文件
xmlReader.parse("book.xml");
11、编写SAX处理器的流程与注意事项:
(1)编写一个作为处理器的类:实现接口ContentHandler 或者 继承该接口的实现类:DefaultHandler
(2)方式一:实现接口ContentHandler
实现该接口中所有的方法,常用的方法是:startElement()、endElement()、characters().
缺点:需要在类中实现其全部方法(包括不需要使用的方法),是类中代码显得很乱。
(3)方式二:继承该接口的实现类:DefaultHandler
仅需要覆盖 编程需要使用的方法,其他方法可以不覆盖。
优点:类中仅仅包含所需要的方法,显得代码简洁,易于阅读维护。
覆盖常用的方法是:startElement()、endElement()、characters().
(4)根据编程需要,在覆盖的方法中编写相应的程序代码。
本例实现代码见下一标题:“13、SAX 方式解析XML文件——流程范例Demo”。
12、SAX 方式解析XML文件——流程范例Demo
(1)使用SAX解析Xml文档
SAXParserFactory factory = SAXParserFactory.newInstance(); //1.创建产生解析器的工厂
SAXParser parser = factory.newSAXParser(); //2.创建解析器
XMLReader reader = parser.getXMLReader(); //3.得到xml文档读取器
reader.setContentHandler(new BookNameHandler()); //4.为读取器设置内容处理器
reader.parse("src/book.xml"); //5.利用读取器解析xml文档
(2)样例Demo1:编写处理器——获取整个xml文档内容的处理器
class ListHandler extends DefaultHandler{ //创建类,并继承
public void startElement(String uri, String localName, String name,
Attributes atts) throws SAXException {
System.out.println("<" + name + ">");
}
public void endElement(String uri, String localName, String name)
throws SAXException {
System.out.println("</" + name + ">");
}
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.println(new String(ch,start,length));
}
}
(3)样例Demo2:编写处理器—— 获取到指定位置序列《书名》标签的值 以及属性值
class BookNameHandler extends DefaultHandler{
private String currentTag;
private int count; //记住当前解析到了几个书名标签
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
currentTag = name;
if("书名".equals(currentTag)){
count++;
}
//得到标签所有属性
for(int i=0;attributes!=null && i<attributes.getLength();i++){ //nullP
String attName = attributes.getQName(i);
String attValue = attributes.getValue(i);
System.out.println(attName + "=" + attValue);
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if("书名".equals(currentTag) && count==1){ //指定位置序列 1
System.out.println(new String(ch,start,length)); //将得到的标签名及其属性值打印。
}
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
super.endElement(uri, localName, name);
}
}
(4)样例Demo3:编写处理器—— 把书的数据封装到javabean的处理器
class BeanListHandler extends DefaultHandler{
private List list = new ArrayList();
private Book book; //自定义JavaBean类
private String currentTag;
public List getBooks(){
return list;
}
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
currentTag = name;
if(name.equals("书")){
book = new Book(); //book.set
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if(currentTag!=null && currentTag.equals("书名")){
book.setBookname(new String(ch,start,length));
}
if(currentTag!=null && currentTag.equals("作者")){
book.setAuthor(new String(ch,start,length));
}
if(currentTag!=null && currentTag.equals("售价")){
book.setPrice(new String(ch,start,length));
}
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
if(name.equals("书")){
list.add(book);
}
currentTag = null;
}
}
附1:Domain类:Book.java
public class Book {
private String bookname;
private String author;
private String price;
public String getBookname() {
return bookname;
}
public void setBookname(String bookname) {
this.bookname = bookname;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
}
附2:Xml文件:book.xml
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名 name="aaa">javaweb开发</书名>
<作者>张孝祥</作者>
<售价>39元</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>张xx</作者>
<售价>890元</售价>
</书>
</书架>