最近在帮朋友做一个关于“热点新闻发现”的需求。先解释下什么是热点新闻发现:即在海量的新闻文本中,找到内容相似的那一类新闻,如果这类新闻的数量达到一定阈值,便认为该类新闻属于热点新闻。
其实这一类型的课题早在几年前就已经开始研究,属于TDT(Topic Detecting and Tracking话题检测与发现)分支之一,而且方法也较为成熟,多半是在文本分析的基础上利用数据挖掘中聚类知识进行处理。
但是,笔者遇到的这个需求较为特殊:
第一,这里的文本类型是互联网搜索引擎爬下来的“新闻”;
第二,数据量大约是10W-100W之间;
第三,需要程序单机处理,并且硬件配置和普通PC无异(双核CPU,内存4G左右);
第四,程序要求在30分钟内处理完毕;
最后,程序得到的热点新闻必须在新浪、网易、腾讯等大型门户网站上有相关新闻。
(哎,这就是小公司的悲哀,老板们总希望用最小成本获得最大收益,“又想马儿跑又想马儿不吃草”,天下哪有这等便宜事,但是谁叫他是老板,作为“码农”,还是得想尽办法去满足老板的需求。)
理想情况,假设硬件资源充足的情况下,大家会怎么处理?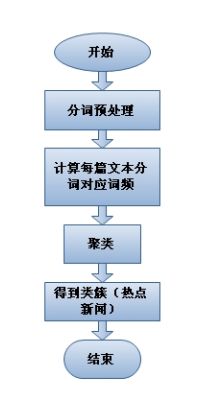
上图为简易的传统处理流程,如果硬件资源充足,即认为内存无上限,为了达到较快的运行时间,开发者理所当然将存储在硬盘上的文本文件全部Load进内存,然后:
1)对每篇新闻进行分词:文本分析中对文本进行分词处理是每篇文本特征化的第一步;
2)文本特征化:使用这种<分词,词频>来特征化每篇文本,当然你也可以使用较为常用的TF-IDF(即词3频-逆文档率)来进行特征化;
3)聚类:当获得每篇文本特征化表示方式后,开发者可以使用层次聚类、基于密度的聚类或者比较常用的划分式聚类(比如:k-means)来进行聚类分析;
4)过滤处理:对聚类后的所有类簇进行匹配,如果类簇中的新闻数量未达到阈值则将其过滤,否则认为该类属于热点新闻。
理想很美好,现实很骨感。老板给的硬件环境只是普通PC,为了不发生OOM(out of memory)的事件,这就使得开发者不可能将所有数据load至内存。是否有其他解决办法呢?也许有人想到,是不是可以采用类似外排序那种处理方式,处理一部分数据后将其结果保存至外存储,然后再处理下一步部分数据,如此循环,最后对所有结果进行归并。
是滴,这确实是一个好办法,即传说中的用时间换空间。但是万恶的老板要求,所有数据必须在30分钟内处理完毕,时间条件上不允许,并且传统的聚类算法处理时间随着数据量的增长往往呈非线性增长趋势,在时间上也较难满足笔者需求。
正像其他的数据挖掘问题一样,熟悉业务可能比会使用“牛B”的算法更为重要。为了解决上述问题,笔者对业务本身以及数据源特征进行了梳理,并总结出“某些经验”(这是基于对业务理解所产生的,可能并不一定具有普遍性,但是如果读者的业务也和笔者相似,可以举一反三试用下)形成了下述流程。
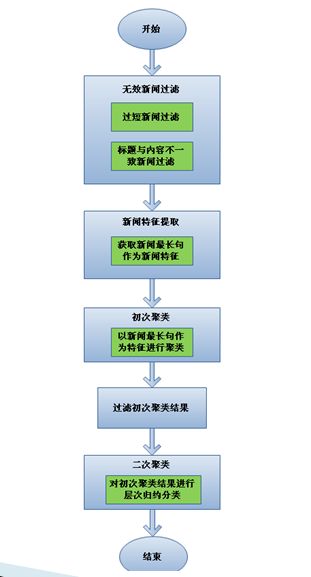
如图所示,与理想情况相比,新流程多了无效新闻过滤环节和二次聚类环节,并且在第一次聚类过程中特征化方式不一样,这些都是基于业务经验总结出来的,详述如下:
1) 无效新闻过滤:由于互联网上的新闻质量参差不齐以及爬虫本身的问题,所以往往会导致无效新闻的产生,笔者将其分为四类——a)新闻标题为空;b)新闻正文为空;c)新闻正文内容过短;c)新闻标题与正文内容不符。
其中,前三类过滤非常简单,只需判断是否为空或者检查字符串个数是否达标即可,而新闻标题与正文内容不符笔者是这么处理的:
首先,将标题进行分词(分词过程中需过滤无效词);
第二,定义同义词库,查找出分词后标题词元的同义词;
第三,在正文中查找是否出现标题词元,如果出现的词元个数大于阈值,即认为标题与正文相符(比如,标题词元有4个,在正文中出现了3个,阈值为2,则相符);否则,再将标题词元的同义词进行匹配,如果正文中匹配的个数大于阈值,也认为标题与正文相符;否则,判定为新闻内容与标题不相符。
(Tip:其实这个匹配过程属于多字符串匹配过程,笔者选用AC算法进行处理。)
最后,即可获得有效新闻,通过此步骤,可以过滤掉大量无效新闻,优化后续处理步骤的空间和时间。
2) 初次聚类:在第一次聚类过程中,笔者的特征提取方式和普通文本特征提取不太一样(传统处理可能选词频或者TF-IDF作为文本特征),笔者选取每篇文本的最长句作为新闻文本特征。这是基于业务特性的经验总结,因为笔者发现互联网上的新闻发表方式多为转载,或者是在各大门户网站所发表新闻的基础上进行局部修改。在此步骤中,如果两篇文章中最长的一句话是相同的,笔者即认为它们是相似新闻。
在此步骤中,笔者将最长句作为文本特征,并采用Hashtable作为存储结构,其中key:是文本最长句,而value是具有该最长句的新闻集合。
3) 过滤初次聚类结果:在此步骤中,笔者设定了过滤阈值,如果某个类簇(新闻集合)中新闻数量低于阈值,则将其过滤。
当然,读者会说,此时最好不应该进行过滤,因为通过后续第二次聚类处理,某些小于阈值的类簇有可能形成一个大类簇。对,这确有可能发生,笔者之所以这么做,是在精确度和时空复杂度之间进行了取舍,如果加入此过滤步骤,将会为第二次聚类优化大量时间和空间。
4) 二次聚类:或许读者已发现初次聚类并不是一个十分严谨的聚类,假如两篇文本内容相似但是不拥有相同的最长句,那么它们很可能被拆分成两类新闻,而这步骤便是要解决该问题。
经过对初次聚类结果过滤后,其实此时得到的类簇数量已经远远低于最开始的新闻文本数量(笔者针对自己的数据实验,最开始时新闻文本数量有30W,经过初次聚类并过滤后将只剩下2k个类簇),此时选取每个类簇的新闻标题作为原始文本,采用理想硬件条件下的普通的聚类方式进行聚类处理,即完成了二次聚类。
(虽然普通的聚类方式会随着数据量增加时间会曾非线性增长,但是经过多次过滤处理,第二次聚类过程所处理的数据量已骤减(只有2K左右),因此可以选用该算法。)
5) 最后,再将二次聚类合并后的类簇进行阈值过滤,即得到热点新闻。
(TIP:在该步过滤环节中,笔者还引入了指定网站过滤——即如果某个类簇中不包含五大网站(sina/sohu/qq/ifeng/163)的新闻便将其过滤,原因是考虑到五大网站的影响力和权威性,如果连它们都没有录入新闻,我们有理由认为这类新闻很难成为热点新闻。)
总结一下,笔者的解题思路其实是遵循这么一个模式:为了解决时间和空间问题,需要一步一步的过滤或合并数据,但是每次在过滤或合并数据时选择的处理方式的效率一定要高,即要考虑收获与成本之间的差异,即多引入一个流程所带来的时空开销一定要远远小于后续流程所节省的时空量;其次是关于算法准确率问题,为了获得时空上的优化可能是需要牺牲算法准确率(比如初次聚类的过滤问题),笔者建议读者最好多准备几组实验数据以确定阈值,从而达到准确率和时空复杂度之间的平衡。