Over a decade into XML evolution, however, these parsing technologies are slowly showing their age, requiring bypasses and optimizations to overcome their well-known limitations. StAX, or Streaming API for XML, is the new-age XML parser that offers the best features of the existing models, and at the same time provides high performance and efficient access to the underlying XML document.
This article introduces you to StAX 2, and gets you hands-on writing code using an open source StAX 2 implementation called Woodstox.
About DOM and SAX
Chances are that you already work with DOM or SAX parsers in one form or another.DOM is Document Object Model, a W3C standard for representing and manipulating XML documents programmatically. DOM has one of the simplest to learn interfaces, and provides extremely developer-friendly objects and methods for accessing an XML document. In fact, many scripting languages support DOM for these reasons.Figure 1 shows how DOM works.
Figure 1: DOM Operation
Essentially, the XML document is parsed into memory, and the various elements and sub-elements are transformed into data structures. This creates a large in-memory version of the XML document. Using the DOM APIs, you can easily query for different nodes in the tree, get their attributes, contents, namespace information, etc. The powerful, document-wide queries that you can make using DOM also distinguishes it from other parser technologies. For example, to get all the elements named “bigelement” in the entire XML document, you only need a call similar to:
NodeList nodes = document.
getElementsByTagName("bigelement"); Since DOM has access to the entire document, document validation is usually quite straightforward to implement and is a part of most DOM parsers.
DOM works great when the XML documents are relatively small. The Achilles’ heel for a DOM parser is the memory requirement when parsing moderate to large sized documents. The fact that the entire document is represented in memory makes working with large documents difficult. A DOM parser must read through the entire XML file before output can be generated by your code; with a large document, this parsing can take a significant time.
Many optimizations have been made to the basic DOM model to deal with these problems (such as lazy on-demand loading of certain parts of the document tree), and some of them work well for certain application scenarios.
DOM’s low level cousin: SAX
The Simple API for XML (SAX), although widely used, has never been formally defined or ratified by any standards bodies. The initial SAX 1.0 API is practically defined by the API that implements it (in Java). The new SAX 2.0 API provides more configurability and support for XML details such as namespaces. You can find the latest official SAX downloads at SourceForge.If you view DOM as a high-level way of accessing an XML document, then you can think of SAX as a very low-level way of accessing the document. In fact, you frequently find that DOM parsers use SAX under the hood.
A SAX parser does not read in an entire XML document before allowing you to process the data. Instead, it fires specific events back into your code as it encounters different elements in the XML document. Figure 2 shows the operation of a SAX parser.
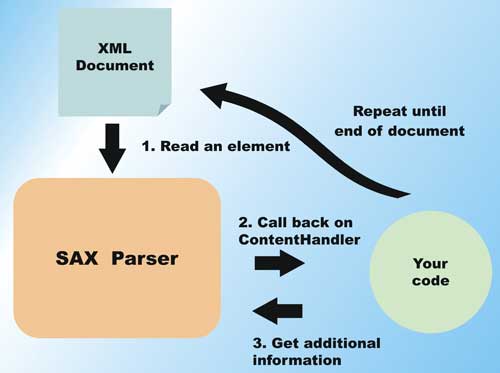
Figure 2: SAX Operation
When you write code using a SAX parser, you must add a content handler to handle the different events. As the SAX parser parses the document, events such as start of document, start of element, end of element, content characters parsed, and so on, are fired into your content handler. Since the document doesn’t need to be loaded in its entirety, the SAX parser has considerably lower memory requirements than a DOM parser. However, also because the entire document is not loaded, and the document is only accessed one symbol at a time, SAX provides no document query capability. In addition, SAX parsers do not provide any document validation capabilities.
SAX parses documents in a forward-only manner, allowing the parser to free data structures used during parsing soon after an element has been parsed. This results in a considerably smaller memory footprint while parsing large documents.
Writing SAX-based parser code is considerably more difficult than writing DOM code. The current state during parsing must be maintained by the code that you write. If you need to know where you are in a document tree at some time, you must save enough information to determine it yourself.
Streaming XML – StAX
StAX (Streaming API for XML) is detailed in specification JSR-173, stewarded by an expert group headed by BEA. StAX 2 is an extension of the StAX 1.0 specification to address some of the issues identified with the StAX 1.0 APIs. However, StAX 2 is not the product of formal specification. A StAX 2 parser implements the full StAX 1.0 specification in addition to the extensions.StAX is similar to SAX parsers in that it does not build an in-memory tree of the document, and reads the document in a forward-only manner. Because of this, StAX also offers small parser memory footprint and parse code efficiency.
While StAX 1.0 API does not define any assistance in document validation, the StAX 2 extensions provide a full framework to assist in DTD-based document validation.
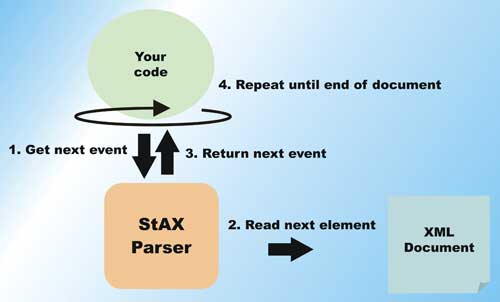
Figure 3: StAX Operation
Unlike SAX, StAX’s strength lies in the availability of cursor level access to the document. You can think of a StAX cursor as a low-level file pointer into well-defined points (aligned with XML elements) within the document. With StAX, you can move this pointer forward, skipping to only the elements that you care to parse and process (see Figure 3).
In addition to the cursor-based APIs, StAX also includes an event object-based iterative API. With this API, you can pull complete Java objects representing the parser events. These objects can be passed along to delegates for parsing, through an XML processing pipeline, or back to a StAX writer for XML output. This object-based API is out of the scope of this article, see StAX 1.0 specification for more details.
There is another key difference between StAX parsers and SAX parser: StAX is a “pull” parser model while SAX is a “push” parser model. The next section explains this very important difference.
Push versus pull
Unlike the SAX model, when you are working with StAX you have control over the parsing code, and can incrementally move the parser engine forward by asking for the next piece of data. Figure 4 shows this difference.
Figure 4: Push versus pull
With SAX, the document is parsed by the parser, and the opportunity to process the parsed document is “pushed” to you. If you do nothing with these opportunities, the document is still parsed and nothing will be done.
With pull parsers such as a StAX implementation, you must write code to ask for data and move the parser engine forward. If you do nothing, the document will not be parsed at all. You need to actively “pull” data from the document. This is the key to high efficiency parsing – you can optimally direct the parser to only work on parsing the portion of the XML file that you need to process, and there is no work wasted.
Since a pull parser leaves the developer with full control of the XML parsing engine, code can actually work on multiple documents on the same execution thread. This is in contrast with most push parsers, where there is usually a one-to-one correspondence between execution threads and documents being processed.
Bidirectional API supporting XML output
Unlike SAX but similar to DOM, the StAX API also includes the ability to write XML documents. This makes the creation of XML filtering and transformation applications quite straightforward.In StAX 2, this capability is further extended to provide pass-through abilities where elements with large and complex bodies can be directly passed between the reader and writer to increase processing efficiency.
With this background, let’s explore StAX 2 further by writing some actual code to process an XML file.
Hands On with Woodstox
While there are StAX 1.0 parser implementations from SUN, BEA and Oracle, among others, there is currently only one parser that implements StAX 2. Called Woodstox, it is an open source parser released under the Apache Software License 2.0 (a version for the LGPL 2.1 licence is also available). You can find the download and documentation here.The code for this article has been tested with Woodstox 3.2.0. After you have unzipped the download, you will only need two JAR files to compile and run the example:
- stax2.jar
- wstx-asl-3.2.0.jar
Large XML files with huge elements
In this example, you first use the bidirectional support of StAX to create a very large XML file. The XML file contains elements with large text content – up to about 5 MB in size. Randomly embedded in the content is the ‘@’ character. You will then create two parsers to parse the XML file:- a DOM-based parser
- a StAX-based parser
You will see how to program Woodstox to parse and write XML files; and you will appreciate at first hand the difference between a DOM parser and a StAX parser.
The code to write the large XML file (about 380 MB in size) is in BigFileGen.java from the source code download – www.vsj.co.uk. This file provides the input for the StAX parser code that you will write; it also helps to illustrate the limitations of a DOM-based alternative.
The general form of the generated XML file is:
<mydoc> <myelement> <bigelement> abcdefghijklmnopqrstuvwxyzABC ... </bigelement> <withnested> <nested1>abcdefg... </nested1> <nested2>abcdefg... </nested2> ... <nested49>abcdefg... </nested49> </withnested> </myelement> ... </mydoc>The document element is <mydoc> and it contains 50 <myelement> elements. Each <myelement> contains a <bigelement> and a <withnested> sub-element. The <bigelement> has a very large content text of about 5 MB in size. In this content are a random number of embedded ‘@’ characters. Each of the 49 <nestedxx> elements has a body of about 5k in size, and they also contain text with embedded ‘@’ characters.
The code of BigFileGen.java is annotated in the following listing. First, note the XMLStreamWriter2 extends from XMLStreamWriter. XMLStreamWriter is the StAX 1 inteface, while XMLStreamWriter2 has additional StAX 2 features.
package uk.co.vsj.woodstox;
import java.io.FileWriter;
import
javax.xml.stream.XMLOutputFactory;
import
javax.xml.stream.XMLStreamException;
import
org.codehaus.stax2.XMLStreamWriter2;
public class BigFileGen {
private static String filename =
"c:\\bigfile.xml";
private String alphabet =
"abcdefghijklmopqrstuvwxyz";
private String alphabetUpper =
alphabet.toUpperCase();
private String egg = "@"; The alphabet and alphabetUpper strings are used to compose the large content bodies of the big element. The egg is the character that will be embedded randomly in the content, in this case the ‘@’ character. The main() method creates an instance of BigFileGen and calls the writeFile() method to write out the XML file.
public static void main(String[] args)
throws Exception {
BigFileGen bfg = new BigFileGen();
bfg.writeFile();
} All of the work of writing out the XML file is located in the writeFile() method. Parser timing is calculated by maintaining a startTime variable.
public void writeFile() {
long startTime =
System.currentTimeMillis();
try{ You need an instance of XMLStreamWriter2 to write the XML file, this can be obtained from an instance of the class factory called XMLOutputFactory. Since the only StAX implementation in the classpath will be Woodstox, this obtains a Woodstox XMLStreamWriter2.
XMLOutputFactory xof = XMLOutputFactory.newInstance(); XMLStreamWriter2 xtw = null; xtw = (XMLStreamWriter2) xof.createXMLStreamWriter( new FileWriter(filename));XMLStreamWriter2 has many useful writexxxx() methods, including:
- writeStartDocument()
- writeStartElement()
- writeEndElement()
- writeEndDocument()
- writeAttribute()
- writeCData()
- writeCharacters()
- writeComment()
- writeEmptyElement()
- writeDTD()
- writeNamespace()
- writeEntityRef()
- writeProcessingInstruction()
xtw.writeStartDocument();
xtw.writeStartElement("mydoc");
for (int j=0; j < 50; j++) {
xtw.writeStartElement(
"bigelement");
writeLargeBody(xtw, 100000);
xtw.writeEndElement();
xtw.writeStartElement(
"withnested");
for (int i=1; i < 500; i++) {
xtw.writeStartElement(
"nested" + i);
writeLargeBody(xtw, 100);
xtw.writeEndElement();
}
xtw.writeEndElement();
}
xtw.writeEndDocument();
xtw.flush();
xtw.close();
}catch(Exception ex){
System.err.println("Exception
occurred while writing");
ex.printStackTrace();
}
System.out.println(
"Writing completed in " +
(System.currentTimeMillis()
-startTime) + " ms");
} The writeLargeBody() method uses XMLStreamWriter2’s writeRaw() method to write out an alphabet string a specified number of times. The writeRaw() method is only available with StAX 2. This method will write out characters to the document without any encoding or escape codes. It is useful for high performance write when you know ahead of time that content needs no further escape or encoding. This may occur, for example, if the content originated from an XML file that you are reading. In our case, the alphabet and alphabetUpper string is used to assemble the content. The ‘@’ character is randomly embedded in approximately half the number of iterations.
private void writeLargeBody(
XMLStreamWriter2 xw,
int iterations) throws
XMLStreamException {
for (int i=0; i< iterations;
i++) {
xw.writeRaw(alphabet);
if (Math.random() > 0.5) {
xw.writeRaw(egg);
}
xw.writeRaw(alphabetUpper);
}
}
}
Testing the File Generator
You need to compile the code first; from the distribution’s src directory, run the command:javac -classpath c:\woodstox\stax2.jar; c:\woodstox\wstx-asl-3.2.0.jar -d ..\bin *.javaMake sure you change the c:\woodstox directory to wherever you have Woodstox installed. The above should compile the code and place the binaries in the bin directory.
To run the generator, from the src directory, use the command (typed on one line):
java -classpath c:\woodstox\stax2.jar;c:\ woodstox\wstx-asl-3.2.0.jar;..\ bin uk.co.vsj.woodstox.BigFileGenThe file may take a little while to write out. On a Pentium 4 Dual Core 3.2 GHz system, it took about 20 seconds to generate. You will see a timing summary similar to:
Writing completed in 19797 msCheck your c:\ directory for the generated bigfile.xml.
Parsing with DOM
The first parser you write will be a DOM parser. The code is in SlowParser.java. The main() method creates an instance of SlowParser and call its parseFile() method.package uk.co.vsj.woodstox;
import
javax.xml.parsers.DocumentBuilder;
import
javax.xml.parsers.
DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.Text;
public class SlowParser {
public static void main(
String[] args)
throws Exception {
SlowParser xsp =
new SlowParser();
String filename =
"c:\\bigfile.xml";
xsp.parseFile(filename);
} The core code is in the parseFile() method. This parser uses the DOM parser implementation that is included as part of the Java SE 6 distribution. This parser is obtained from DocumentBuilderFactory.
public void parseFile(String
filename) throws Exception {
long starttime =
System.currentTimeMillis() ;
DocumentBuilderFactory
parserFactory =
DocumentBuilderFactory.
newInstance();
DocumentBuilder parser =
parserFactory.
newDocumentBuilder(); Here, you ask the DOM parser to parse document. This step takes a significant time, as the entire file must be read and transformed to in-memory tree. No output can be generated until the entire document is parsed. Once the document tree is constructed, it can be used to query all instances of <bigelement>.
Document document = parser.parse(filename); NodeList nodes = document.getElementsByTagName( "bigelement");The next section of code goes through the content of all the <bigelement> instances and calls countFilter() to print out the number of ‘@’ signs found.
for(int i = 0;
i < nodes.getLength(); i ++) {
Element titleElem =
(Element)nodes.item(i);
Node childNode =
titleElem.getFirstChild();
if (childNode instanceof Text){
System.out.println(
"Element #" + (i+1) +
" : " + countFilter(
childNode.getNodeValue(),'@'));
}
}
System.out.println("Total of "
+ nodes.getLength() + " occurrences");
System.out.println(" completed in "
+ (System.currentTimeMillis()
- starttime) + " ms");
} The countFilter() method simply looks through every character of the incoming String and counts up the number of ‘@’ signs.
private int countFilter(String
inStr, char filteredChar) {
int count = 0;
for (int i=0; i < inStr.length();
i++) {
if (inStr.charAt(i) ==
filteredChar) {
count++;
}
}
return count;
}
}
Testing the DOM parser
Assuming you have compiled the code in the previous test, and have already generated the c:\bigfile.xml. In the src directory, type the command:java -classpath c:\woodstox\stax2.jar; c:\woodstox\wstx-asl-3.2.0.jar; ..\bin uk.co.vsj.woodstox.SlowParserThis runs the DOM parser against the large XML file. After a very short while, you should see something similar to:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOfRange( Arrays.java:3209) at java.lang.String.<init>( String.java:216)The DOM parser has run out of heap space while parsing the document. You will need to increase this space. Try using the command:
java -classpath c:\woodstox\stax2.jar; c:\woodstox\wstx-asl-3.2.0.jar; ..\bin -Xmx1000m uk.co.vsj.woodstox.SlowParserThis increases the heap to 1 GB (assuming you have that much memory). This time, the parsing takes a lot longer, and output starts until somewhere half way and you get the out of memory error again.
On my system, you have to increase the heap to 1.28 GB(-Xmx1280m) before the parser can complete. Depending on the version of Java VM you use, this required size may be different. Note that this parse took over 33 seconds. The huge memory footprint of a DOM-based parser is also evident. You needed over 1.2 GB of memory to successfully parse this 380 MB XML file. You may want to run this a few times to get an average timing, as the disk cache on modern operating systems has a big effect on this sort of test.
Parsing with StAX 2
On to the more efficient alternative – using StAX 2. The code in the main() method is similar to the DOM case. It creates an instance of FastParser and call its parseFile() method.package uk.co.vsj.woodstox;
package uk.co.vsj.woodstox;
import java.io.FileInputStream;
import java.io.FilterWriter;
import java.io.IOException;
import java.io.StringWriter;
import java.io.Writer;
import
javax.xml.stream.XMLInputFactory;
import
javax.xml.stream.XMLStreamException;
import
javax.xml.stream.events.XMLEvent;
import
org.codehaus.stax2.XMLInputFactory2;
import
org.codehaus.stax2.XMLStreamReader2;
public class FastParser {
public static void main(String[]
args) throws Exception {
FastParser xfp =
new FastParser();
String filename =
"c:\\bigfile.xml";
xfp.parseFile(filename);
} To parse an XML file using StAX 2, you need to get an instance of XMLStreamReader2. This must be obtained from an instance of XMLInputFactory2. Note that you can configure the behaviour of the parser by working with the properties of the XMLInputFactory. Since our XML document has no entities, the factory is configured to ignore them. The IS_COALESCING property can be set to true if you want the character content of an XML document to be returned in one single call – this can save you from having to merge them yourself. In addition to these properties, the StAX 2 XMLInputFactory2 implementation also provides methods to tune the parser for different objectives. These methods include:
- configureForSpeed()
- configureForLowMemUsage()
- configureForRoundTripping()
- configureForXmlConformance()
- configureForConvenience()
public void parseFile(String filename){
XMLInputFactory2 xmlif = null ;
try{
xmlif = (XMLInputFactory2)
XMLInputFactory2.newInstance();
xmlif.setProperty(
XMLInputFactory.
IS_REPLACING_ENTITY_REFERENCES,
Boolean.FALSE);
xmlif.setProperty(
XMLInputFactory.
IS_SUPPORTING_EXTERNAL_ENTITIES,
Boolean.FALSE);
xmlif.setProperty(
XMLInputFactory.
IS_COALESCING,
Boolean.FALSE);
xmlif.configureForSpeed();
}catch(Exception ex){
ex.printStackTrace();
}
System.out.println(
"Starting to parse "+ filename);
System.out.println("");
long starttime =
System.currentTimeMillis() ;
int elementCount = 0;
int filteredCharCount = 0; The XMLInputFactory2 instance is used to create an instance of XMLStreamReader2 for the bigfile.xml that you will parse.
try{
XMLStreamReader2 xmlr =
(XMLStreamReader2)
xmlif.createXMLStreamReader(
filename, new
FileInputStream(filename)); The parsing involve a loop that calls the next() method on the XMLStreamReader2. Each time this method is called, the next event is returned as an int. The event can be decoded by comparing them with constants on the XMLEvent interface. Since an int is returned for each event, there is no Java object creation overhead between the parser code and your code. Note how you are “pulling” events one at a time from the StAX parsing engine. The available XMLEvent code includes:
- START_DOCUMENT
- END_DOCUMENT
- START_ELEMENT
- END_ELEMENT
- ENTITY_DECLARATION
- ENTITY_REFRERENCE
- NAMESPACE
- CDATA
- CHARACTERS
- COMMENTS
- ATTRIBUTE
- PROCESSING_INSTRUCTION
Depending on the event, the parser can be in different state. For example, when you have rectrieved the XMLEvent.CHARACTERS event, you can use the getText() method to access the content of the element. If you are at the XMLEvent.START_ELEMENT, however, this method is not available. On the other hand, while you are at the XMLEvent.START_ELEMENT, the name of the element is available, and you should save this information if you need it in your parsing.
There are a few variations of getText(). In this case, you call one that takes a Writer as an argument. The content of the element will be written to the Writer when you call getText(). This is an efficient way to access large content – since no additional copy or instantiation is required. A custom Writer, called a CountingWriter is supplied to getText(). This writer examines every written content character and counts up the ‘@’ occurrences.
int eventType =
xmlr.getEventType();
String curElement = "";
CountingWriter cw =
new CountingWriter(
new StringWriter(), '@');
while(xmlr.hasNext()){
eventType = xmlr.next();
switch (eventType) {
case XMLEvent.START_ELEMENT:
curElement =
xmlr.getName().toString();
filteredCharCount = 0;
break;
case XMLEvent.CHARACTERS:
if (curElement.equals(
"bigelement")) {
cw.resetCount();
xmlr.getText(cw,true);
filteredCharCount += cw.getCount();
}
break;
case XMLEvent.END_ELEMENT:
if (curElement.equals(
"bigelement")) {
elementCount++;
System.out.println("Element #" +
elementCount + " : "
+ filteredCharCount);
}
break;
case XMLEvent.END_DOCUMENT:
System.out.println(
"Total of "
+ elementCount
+ " occurrences");
}
if (eventType == XMLEvent.START_ELEMENT) {
curElement =
xmlr.getName().toString();
} else {
if (eventType ==
XMLEvent.CHARACTERS) {
}
}
}
}
catch(XMLStreamException ex){
System.out.println(
ex.getMessage());
if(ex.getNestedException()
!= null) {
ex.getNestedException().
printStackTrace();
}
}
catch(Exception ex){
ex.printStackTrace();
}
System.out.println(" completed in "
+ (System.currentTimeMillis()
- starttime) + " ms");
} This following is the implementation of the CountingWriter class. It extends FilterWriter for convenience, overriding the write() methods. The write() methods are overridden to not produce output, but simply count up the number of occurrences of a filter character.
class CountingWriter extends
FilterWriter {
long filtCount = 0;
char filteredChar = 0;
public CountingWriter(Writer out,
char filter) {
super(out);
filteredChar = filter;
filtCount = 0;
}
public long getCount() {
return filtCount;
}
public void resetCount() {
filtCount = 0;
}
public void write(int c) throws
IOException {
if (filteredChar == c) {
//out.write(c);
filtCount++;
}
}
public void write(char[] cbuf,
int off, int len) throws
IOException{
int idx = off;
int count = 0;
while (count < len) {
write(cbuf[idx]);
idx++;
count++;
}
}
public void write(String str,
int off, int len) throws
IOException {
int idx = off;
int count = 0;
while (count < len) {
write(str.charAt(idx));
idx++;
count++;
}
}
}
Testing the Woodstox StAX 2 parser
You should have the code compiled and be in the src directory – type the command:java -classpath c:\woodstox\stax2.jar; c:\woodstox\wstx-asl-3.2.0.jar; ..\bin uk.co.vsj.woodstox.FastParserNote you don’t need to set a large heap value, StAX parsers have very small memory footprint – even when parsing very large documents. Instead of a long pulse before seeing output, you will see the output right away. However, the rate of output is slower than the DOM parser – since the file is processed on-the-fly with StAX; whereas the DOM parser is querying an in-memory document tree during processing.
The output is identical to the DOM Parser test, on my machine the timing is:
completed in 6547 msThis is almost five times faster than the DOM implementation! Again, you may want to run this a few times to get an average timing – and get rid of the disk cache effect.
Conclusion
While StAX-based XML parsing may not be the easiest way to code an XML parser, it certainly provides the highest performance and most efficient possible access to the underlying XML document. Woodstox is a well-tested and high performance implementation of StAX 2, providing several time-saving value-added APIs that greatly simplify typical XML processing work. When your XML parsing work is hampered by the weight of DOM, or the awkward push model of SAX, it is time to integrate Woodstox with StAX 2 to give them a new life.
Sing Li has been writing software, and writing about software, for over twenty years. His specialities include scalable distributed computing systems and peer-to-peer technologies. He now spends a lot of time working with open source Java technologies. Sing’s recent publications include Professional Geronimo and Professional Apache Tomcat from Wrox Press.