Redis Java Client Jedis 源码分析
由于项目中使用Redis,所以使用它的Java客户端Jedis也有大半年的时间(后续会分享经验)。
最近看了一下源码,源码清晰、流畅、简洁,学到了不少东西,在此分享一下。
(源码地址:https://github.com/xetorthio/jedis)
协议
和Redis Server通信的协议规则都在redis.clients.jedis.Protocol这个类中,主要是通过对RedisInputStream和RedisOutputStream对读写操作来完成。
命令的发送都是通过redis.clients.jedis.Protocol的sendCommand来完成的,就是对RedisOutputStream写入字节流
private void sendCommand(final RedisOutputStream os, final byte[] command, final byte[]... args) { try { os.write(ASTERISK_BYTE); os.writeIntCrLf(args.length + 1); os.write(DOLLAR_BYTE); os.writeIntCrLf(command.length); os.write(command); os.writeCrLf(); for (final byte[] arg : args) { os.write(DOLLAR_BYTE); os.writeIntCrLf(arg.length); os.write(arg); os.writeCrLf(); } } catch (IOException e) { throw new JedisConnectionException(e); } }
从这里可以看出redis的命令格式
[*号][消息元素个数]\r\n ( 消息元素个数 = 参数个数 + 1个命令)
[$号][命令字节个数]\r\n
[命令内容]\r\n
[$号][参数字节个数]\r\n
[参数内容]\r\n
[$号][参数字节个数]\r\n
[参数内容]\r\n
返回的数据是通过读取RedisInputStream 进行解析处理后得到的
private Object process(final RedisInputStream is) {
try {
byte b = is.readByte();
if (b == MINUS_BYTE) {
processError(is);
} else if (b == ASTERISK_BYTE) {
return processMultiBulkReply(is);
} else if (b == COLON_BYTE) {
return processInteger(is);
} else if (b == DOLLAR_BYTE) {
return processBulkReply(is);
} else if (b == PLUS_BYTE) {
return processStatusCodeReply(is);
} else {
throw new JedisConnectionException("Unknown reply: " + (char) b);
}
} catch (IOException e) {
throw new JedisConnectionException(e);
}
return null;
}
通过返回数据的第一个字节来判断返回的数据类型,调用不同的处理函数
[-号] 错误信息
[*号] 多个数据 结构和发送命令的结构一样
[:号] 一个整数
[$号] 一个数据 结构和发送命令的结构一样
[+号] 一个状态码
连接
和Redis Sever的Socket通信是由 redis.clients.jedis.Connection 实现的
Connection 中维护了一个底层Socket连接和自己的I/O Stream 还有Protocol
I/O Stream是在Connection中Socket建立连接后获取并在使用时传给Protocol的
Connection还实现了各种返回消息由byte转为String的操作
private String host;
private int port = Protocol.DEFAULT_PORT;
private Socket socket;
private Protocol protocol = new Protocol();
private RedisOutputStream outputStream;
private RedisInputStream inputStream;
private int pipelinedCommands = 0;
private int timeout = Protocol.DEFAULT_TIMEOUT;
public void connect() {
if (!isConnected()) {
try {
socket = new Socket();
socket.connect(new InetSocketAddress(host, port), timeout);
socket.setSoTimeout(timeout);
outputStream = new RedisOutputStream(socket.getOutputStream());
inputStream = new RedisInputStream(socket.getInputStream());
} catch (IOException ex) {
throw new JedisConnectionException(ex);
}
}
}
可以看到,就是一个基本的Socket
这里分享个经验,timeout这个参数默认是2000,我做的项目中有部分是离线运算的,如果读取比较大的数据(大Set 大List之类的)有可能会超过这个时间,可以在JedisPool的构造参数中增大这个值。在线服务一般不要修改。
原生客户端
redis.clients.jedis.BinaryClient 继承 Connection, 封装了Redis的所有命令(http://redis.io/commands)
从名子可以看出 BinaryClient 是Redis客户端的二进制版本,参数都是byte[]的
BinaryClient 是通过Connection的sendCommand 调用Protocol的sendCommand 向Redis Server发送命令
public void get(final byte[] key) {
sendCommand(Command.GET, key);
}
redis.clients.jedis.Client可以看成是BinaryClient 的高级版本,函数的参数都是String int long 这类的,并由redis.clients.util.SafeEncoder 转成byte后 再调用BinaryClient 对应的函数
public void get(final String key) {
get(SafeEncoder.encode(key));
}
这二个client只完成了发送命令的封装,并没有处理返回数据
Jedis客户端
我们平时用的基本都是由redis.clients.jedis.Jedis类封装的客户端
Jedis是通过对Client的调用, 完成命令发送和返回数据 这个完整过程的
以GET命令为例,其它命令类似
Jedis中的get函数如下
public String get(final String key) {
checkIsInMulti();
client.sendCommand(Protocol.Command.GET, key);
return client.getBulkReply();
}
checkIsInMulti();
是进行无事务检查 Jedis不能进行有事务的操作 带事务的连接要用redis.clients.jedis.Transaction类
client.sendCommand(Protocol.Command.GET, key);
调用Client发送命令
return client.getBulkReply();
处理返回值
分析到这里 一个Jedis客户端的基本实现原理应该很清楚了
连接池
在实现项目中,要使用连接池来管理Jedis的生命周期,满足多线程的需求,并对资源合理使用。
jedis有两个连接池类型, 一个是管理 Jedis, 一个是管理ShardedJedis(jedis通过java实现的 多Redis实例的自动分片功能,后面会分析)
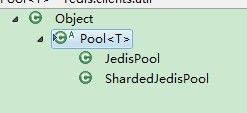
他们都是Pool<T>的不同实现
public abstract class Pool<T> {
private final GenericObjectPool internalPool;
public Pool(final GenericObjectPool.Config poolConfig,
PoolableObjectFactory factory) {
this.internalPool = new GenericObjectPool(factory, poolConfig);
}
@SuppressWarnings("unchecked")
public T getResource() {
try {
return (T) internalPool.borrowObject();
} catch (Exception e) {
throw new JedisConnectionException(
"Could not get a resource from the pool", e);
}
}
......
......
从代码中可以看出,Pool<T>是通过 Apache Commons Pool 中的GenericObjectPool这个对象池来实现的
(Apache Commons Pool内容可参考http://phil-xzh.iteye.com/blog/320983 )
在JedisPool中,实现了一个符合 Apache Commons Pool 相应接口的JedisFactory,GenericObjectPool就是通过这个JedisFactory来产生Jedis对你的
其实JedisPoolConfig也是对Apache Commons Pool 中的Config进行的一个封装
当你在调用 getResource 获取Jedis时, 实际上是Pool<T>内部的internalPool调用borrowObject()借给你了一个实例
而internalPool 这个 GenericObjectPool 又调用了 JedisFactory 的 makeObject() 来完成实例的生成 (在Pool中资源不够的时候)
public Object makeObject() throws Exception {
final Jedis jedis;
if (timeout > 0) {
jedis = new Jedis(this.host, this.port, this.timeout);
} else {
jedis = new Jedis(this.host, this.port);
}
jedis.connect();
if (null != this.password) {
jedis.auth(this.password);
}
return jedis;
}
客户端的自动分片
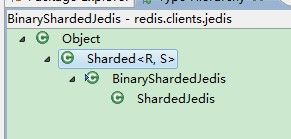
从这个结构图上可以看出 ShardedJedis 和 BinaryShardedJedis 正好是 Jedis 和 BinaryJedis 的分片版本
其实它们都是 先获取hash(key)后对应的 Jedis 再有这个Jedis进行操作
public String get(String key) {
Jedis j = getShard(key);
return j.get(key);
}
分片逻辑都是在 Sharded<R, S extends ShardInfo<R>> 中实现的
它的构造函数如下
public Sharded(List<S> shards, Hashing algo, Pattern tagPattern) {
this.algo = algo;
this.tagPattern = tagPattern;
initialize(shards);
}
shards是一组ShardInfo, 具体实现是JedisShardInfo, 每个里面记录分片信息和权重,并负责完成分片对应Jedis实例创建
Sharded的初始化和一致性哈希(Consistent Hashing)的思想是一样的,但这个并不能实现节点的动态变更,只能体现出节点的 权重分配
nodes = new TreeMap<Long, S>();
这个nodes就是一个虚拟的结点分布环,由TreeMap实现,保证按Key有序,Value就是对应的ShardInfo
160 * shardInfo.getWeight()
根据每个shard的weight值,默认是1,生成160倍的虚拟节点,hash后放到nodes中,也就是分布到环上
resources.put(shardInfo, shardInfo.createResource());
每个shardInfo对应的jedis,也就是真正的操作节点,放到resources中
private void initialize(List<S> shards) {
nodes = new TreeMap<Long, S>();
for (int i = 0; i != shards.size(); ++i) {
final S shardInfo = shards.get(i);
if (shardInfo.getName() == null)
for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
else
for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash(shardInfo.getName() + "*" + shardInfo.getWeight() + n), shardInfo);
}
resources.put(shardInfo, shardInfo.createResource());
}
}
通过Key获取对应的jedis时,先对key进行hash,和前面初始化节点环时,使用相同的算法
再从nodes这个虚拟的环中取出 大于等于 这个hash值的第一个节点(shardinfo),没有就取nodes中第一个节点(所谓的环 其实是逻辑上实现的)
最后从resources中取出jedis来
public S getShardInfo(byte[] key) {
SortedMap<Long, S> tail = nodes.tailMap(algo.hash(key));
if (tail.size() == 0) {
return nodes.get(nodes.firstKey());
}
return tail.get(tail.firstKey());
}
public R getShard(String key) {
return resources.get(getShardInfo(key));
}