http://www.infoq.com/articles/no-reliable-messaging
Author: Marc
A received view in SOA and Web Services is the need for reliable messaging. Reliable messaging is the guarantee that a message sent by a sending application is indeed received at the other end, and received only once. One of the most common objections against REST is that REST doesn't offer reliable messaging. Stefan Tilkov writes: 'It’s often pointed out that there is no equivalent to WS-ReliableMessaging for RESTful HTTP, and many conclude that because of this, it can’t be applied where reliability is an issue (which translates to pretty much every system that has any relevance in business scenarios)'[1]. Tilkov does not agree, of course, and prefers a solution on the application level. Joe Gregorio made a similar point in RESTify DayTrader [2]. Rightly so, the assumption: for business purposes we need reliable messaging, is simply false. The reverse is true: from a business perspective, there is absolutely no need for reliable messaging. If we have well-defined business semantics and business logic, separate reliable messaging is redundant.
Web Services and Reliability
Web Services offer a way of insulating message exchange details from business logic. Basically the idea is we describe our business in terms of services (i.e. 'browse catalog', 'place order', check order status' etc.). The services are implemented by exchanging business documents, which embody the business semantics. If we use Web Services, the business documents are carried in SOAP Envelopes. The SOAP Envelopes also may carry SOAP Headers, which implement pieces of messaging functionality: message security, integrity, addressing, reliability et cetera. Each piece of messaging functionality is independent of the other pieces: i.e. it is possible to do message integrity without reliability, the reverse, neither or both.
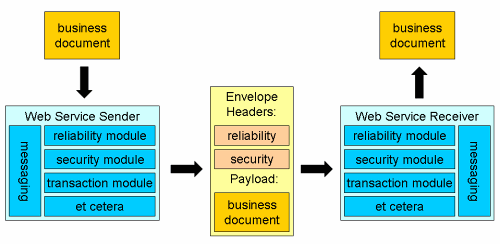
The above picture highlights some important features of SOA as implemented using Web Services:
- the business layer is independent of the messaging layer;
- Web Services add independent 'plug & play' pieces of message functionality;
- message headers carry information on required messaging functionality.
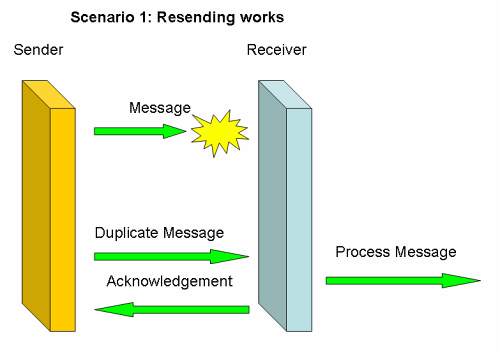
Web Services are not always reliable by themselves. The basic problem: if I send a message, say I order a book, and through some netwok glitch the message never arrives, I get no book. Simply resending the message would solve this, as scenario 1 shows.
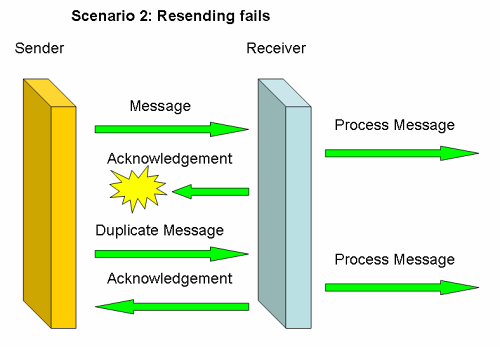
However, if the message arrives, but the response is lost, resending will not work: if I've ordered a book, I'll receive two books in scenario 2.
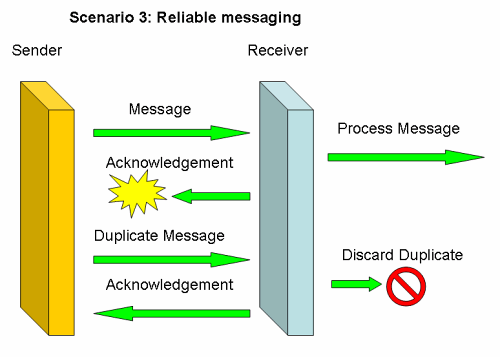
Reliable messaging solutions usually solve this problem through acknowledgements, duplicate detection and duplicate removal, as scenario 3 shows.
Web Services offer WS-ReliableMessaging[3] as the standard for reliable messaging. WS-ReliableMessaging can offer several guarantees: that messages sent arrive at least once, at most once, exactly once and/or in order. Since what one usually wants is that messages arrive once and only once, I'll only discuss the 'exactly once' and 'in order' cases. Let's start with in order arrival of messages.
The Right Order
There is a friction between the guarantees of WS-Reliable Messaging and the ordinary processing of messages from a business perspective. A common case where in-order processing is important, is in online banking. If I transfer money from my savings account to my checking account, which is near-zero, and subsequently transfer money from my checking account to a third party, I want the money transfers to be processed in order: otherwise the second transfer might bounce due to insufficient funds. I know this is important: my bank doesn't offer in-order processing, and my transfers regularly bounce when I forget to submit them in two separate sessions...
It seems WS-Reliable Messaging is ideally positioned to cure such situations. However, on further inspection, it's not that crystal-clear. What does WS-Reliable Messaging do to achieve in-order processing? Unsurprisingly, it attaches an incremental sequence number to each message. If the messages arrive out of order (i.e. 2-1-4), the WS-Reliable Messaging software at the receiving end waits till the missing messages arrive, and then submits them to the next layer which contains business logic in-order (i.e. it submits 1 and 2, waits for 3, then submits 3 and 4). The first strange thing is that apparently the order is a property of messages which is important to the business layer. So if it is important to the business layer, why isn't there a sequence number in the business message itself? We have a message, with its own business-level semantics, and the order is important: so why isn't there some element or attribute in the message, on a business level, which indicates the order?
There are two possible answers. First: there is also a sequence number in the payload, with business semantics regarding order attached to it. If there is, why do we need WS-Reliable Messaging? It's doing things twice. Maybe, in a few cases, doing things twice may be the thing to do (say my very fast and efficient WS-Reliable Messaging box can do this really really fast, and then the business layer receives only in-order messages and just checks to make sure) but in general doings things twice makes me wary. It introduces redundancy. If the sequence indicators in the WS-Reliable Messaging headers and in the payload differ, what do I do? How do I make sure the same rules apply to errors in in-order processing in both levels (say a missing message never arrives: do I submit none of the remaining messages, or all with an error condition, or alarm a human to sort things out?). Things will only work if both levels, WS-Reliable Messaging and business, conform to the same logic.
The second answer is: there is no sequence number in the business payload. After all, one might say, we've got WS-Reliable Messaging, so why do we need it? This, frankly, is turning the world upside down. If the order is important on the business level, the business level needs to indicate order, ensure its proper processing and persist it as well. If we make the order, important on a business level, dependent on the order in which messages are shoved into a WS-Reliable Messaging-bus at one side, and the order in which they come out at the other side, we make apermanent feature of the business logic (order) dependent on a transient feature of the message processing: the order in which they come out of a message bus. The WS-ReliableMessaging sequence number is lost after the WS-Reliable Messaging bus has done its work, making any decent logging or auditing impossible. Of course it is possible to attach a new sequence number to the messages, which indicates the order in which the messages came out of the WS-Reliable Messaging box, but still, without logging the entire WS-Reliable Messaging stream this carries little weight for serious auditing purposes. And logging the entire WS-Reliable Messaging stream is certainly possible, but it all seems so much doing things at the wrong places.
Moreover, the in-order processing is not just a feature of the interaction between the WS-Reliable Messaging bus and the business layer. If my bank has resulted from a merger of two banks, and my savings account happens to be in a different database than my checking account, on a different machine in a different location: then just submitting the messages from the WS-Reliable Messaging bus to the business layer in the right order doesn't do the job at all. The business layer needs to make sure the savings software and the checking software do their jobs in the right order too. This example shows how deeply embedded in-order processing may be into the business logic. Implementing this without order indicators in the message payload itself is insanity.
To summarize: if in-order processing of messages is a property of the business we're conducting, we need order indicators in the messages on the business level, with appropriate business semantics and business logic attached. If we follow this simple and sound design guideline, then we don't need WS-Reliable Messaging. Maybe in some cases using WS-ReliableMessaging might be more efficient. From a business perspective, however, functionally there is no need for WS-Reliable Messaging in a properly implemented business layer.
Once, and Only Once
A similar line of reasoning applies to exactly-once delivery. I've got a message for you: and on a business level, it's important that it's delivered once and just once. Say I have a book order: I don't want to receive the same title twice, nor do I want it not at all. Now, if it's important to us, on a business level, that I get my book exactly once, what does the assurance that my message has been received exactly once really bring me? I want to know that your book ordering system has received it. If the WS-Reliable Messaging bus accepts it, and subsequently the book system rejects it because I've entered a wrong client number or a non-existent catalog item, knowing the message has been received brings me preciously little assurance. And even when the message is syntactically and semantically correct, it's no good if the title is out of stock: I want my book, not just the certainty my message has been received well. If the processing of my message once, and exactly once, is important on a business level, I need to confirm the exactly-once processing on a business level. As the figure below shows, the transport acks are pretty meaningless on a business level: we need the business ack.
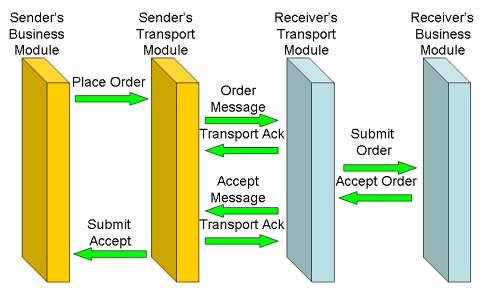
Some may argue that the WSRM module should do syntax checks on incoming messages as well. And of course a WSRM module could do most of the syntax check, say a schema validation. But look at customer numbers, or catalog items: it is impossible to know whether a certain customer number or catalog item is a valid one without doing a database lookup. And knowing whether a title is in stock isn't possible at all on a syntactical level. There is no way to guarantee that a message will be acceptable to the business level without actually submitting it to the business level. And if the business level may refuse my message, knowing the WSRM module has properly received it is not what I need. I need a business reply, assuring my message has been accepted once, and only once, on a business level. If receiving every message exactly once is important on the business level, the business level should respond with a message saying it has received, and accepted, the message. Again, if this simple design guideline is followed, there is functionally no need for separate reliable messaging from a business point of view.
Let's look at the 'exactly once' requirement in some more detail. Stating that it is important on the business level that every message is received exactly once, like it is in order processing, means that every message constitutes a unique business transaction. Like with in-order processing, WSRM guarantees exactly-once delivery through attaching unique numbers to messages, acknowledging receipt, and possibly resending or duplicate removal. Again, if every message is a unique business transaction, clearly there must be a unique id on the business level: an order id, a reservation number, some unique token. And if we need such a unique token on the business level, the business level should assert it's uniqueness. Uniqueness on the business level should not be dependent on the transient uniqueness on the message level, but must be a persistent feature of the business message, and business semantics must guarantee it.
Idempotency to the Rescue
When the business logic requires in-order processing or exactly once delivery, I clearly need a business reply: the business reply is the only guarantee that, on the business level, my message was received and processed correctly. Simply returning the business reply instead of all the WSRM magic does the trick, and way better than WSRM can do. And what happens if we do implement unique business transaction ids and business acks on the business level? Basically we make every message idempotent on the message transport level. If we have unique business id's, duplicate detection on the business level, and business acks, it is always safe to resend a message on the message level. This makes reliable messaging a no-brainer: if I receive a HTTP 200 OK response (or some other 'success' response) on my message, everything is fine: my message has been received, and if the business response is not sent in the HTTP response, I may wait till I get it. Of course, in implementing the web service, we need to make sure the incoming message is stored on some persistent medium before we respond with '200 OK' - otherwise the message would still be lost if a computer crashes. But with WSRM we would need a similar guarantee, WSRM by itself doesn't offer it. And if I don't receive a '200 OK' through some communication glitch, it is safe to resend the now idempotent message until a response is received.
The Case of Dutch Healthcare
In the Netherlands, we're setting up a national healthcare infrastructure. All healthcare organizations will exchange information through a central Healthcare Information Broker. All healthcare professionals with relevant credentials will be able to access information for their patients through the national exchange. A national standardization organization, Nictiz[4], develops the relevant national standards based on HL7v3, the medical vocabulary and messaging framework, and Web Services.
Originally there was no standard for reliable messaging available: in 2003 and 2004, the turf wars about WS-Reliability versus WS-ReliableMessaging where still going on, and we decided to use a temporary home-grown solution till the dust had settled. In 2008 and 2009 we returned to the reliability issue: since the national exchange was coming up to steam quickly, the temporary solution was no longer viable. We designed a solution based on WS-ReliableMessaging and decided against it. Let's look at some of the details.
In order processing was hardly relevant in our case: exactly once delivery was, or so we thought. We use synchronous communication, SOAP over HTTP, where a message is sent as HTTP request and the business answer is carried over the HTTP response. There are, simplifying a bit, two kinds of transactions:
- queries, such as a query for a patients medication history, where the query response is returned as HTTP response;
- orders, such as a medical prescription, where a business response (usually a HL7v3 acknowledgement) is carried over the HTTP response.
In the first case, queries, there is simply no need for reliable messaging. If, through some communication glitch, the query or the answer is lost, the query can simply be submitted again. Queries are safe: the state of the server is not changed in any way (other than maybe traffic counters and other non-relevant side-effects).
For orders, the case is different. If a GP sends a prescription to a pharmacist, it is important to know that is has been received, and received only once. If all goes well, there is no problem: the GP sends a prescription, the pharmacist's server returns an HTTP '200 OK' response, and the GP's application reports the prescription has arrived. If things do not go well, there is a problem. If the GP's application does not receive a '200 OK' response, what to do? If the prescription never arrived at the pharmacist's server, it should be resent. If it did not arrive, it may not be resent: that might be interpreted as a second prescription, not a duplicate.
However, prescriptions already carry an unique prescription id.
<Prescription>
<id extension="0003000201"
root="2.16.840.1.113883.2.4.6.1.6005465.12.1"/>
This XML fragment shows the prescription identifier in HL7v3 format. The 'root' part is an OID, which is assigned to each healthcare provider's application: no two applications will have the same root attribute. The 'extension' part is a local unique key for the prescription: the same number which appears in print on prescriptions as well. Together they constitute a globally unique identifier.
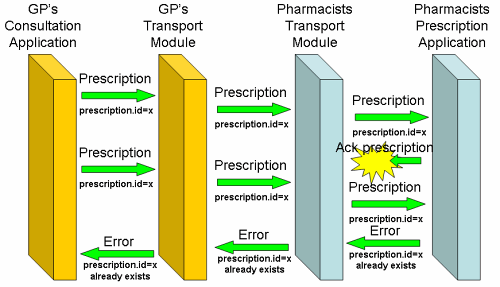
Since the prescription id is unique, we require a receiver to check for double prescriptions, using the prescription id. If a prescription is received twice, an error message is returned. (In some cases, where needed, we also require the receiver to return a duplicate of the original answer, if it contains information which is needed.) What does this do? Since duplicates are removed on the business level, all messages become idempotent: it is always permitted to resend a message in case of doubt about the communication.
Much of the use case for transport level reliable messaging is gone: if no acknowledgement is received, the prescription is simply resent. The error which is received when the first prescription has been received after all, is as much proof of successful transmission as the original acknowledgement. We've tightened our specs a bit on returning and interpreting this specific error condition, and all of a sudden separate reliable messaging is no longer necessary. It's even hardly an effort: since HL7v3 has a prescription id, which must be unique, each healthcare application has to handle duplicate prescription id's anyway. If the acknowledgement carries information which the GP has to receive, we could require the pharmacist to reconstitute the original acknowledgement and return it on receiving a duplicate prescription: the situation doesn't occur too often though, and for simple acks it is not needed. So a bit of tightening of the business rules has removed the case for separate transport reliability: all it would do is add another layer which assigns unique id's and handles duplicates again. Note that it isn't just WS-ReliableMessaging. It may be the main contender, but for alternatives such as ebMXL Messaging or WS-Reliability, the same line of reasoning applies.
WS-ReliableMessaging alone isn't good enough for synchronous messaging either. In cases where the client is behind a firewall, or has an unreliable mobile connection, the client isn't addressable directly by the server. So the server has no way to resend unacknowledged responses to the client if the HTTP connection is closed unexpectedly. Another WS-* specification is needed for this case: WS-MakeConnection, which enables the client to set up a new HTTP connection and poll for potentially waiting response messages. Since all our traffic in Dutch healthcare is synchronous, this addition is necessary. So instead of upgrading all necessary clients with just WS-ReliableMessaging capabilities, the much newer WS-MakeConnection is also needed (and most clients today simply do not have the necessary libraries yet). WS-MakeConnection also basically makes all synchronous traffic asynchronous in case of failure. While this not necessarily a bad thing, it would make the Dutch healthcare specification much more complex. The WS-* mantra is often: the complexity of the specification is hidden from the developer by the software: install your WS-* libraries, and they will do the magic for you! I never believed in this 'complexity-hiding-philosophy'. Any developer worth her salt will want to know what's going on behind the curtains on this level. It's impossible to debug a live session if you do not even understand whether your traffic is synchronous or secretly split up.
Conclusion
In Dutch healthcare, given the complexities of reliable messaging, and given the fact that the use case from a business perspective mostly evaporates, we've decided not to use reliable messaging on the transport level. With a bit further tightening of the business logic, which requires unique prescriptions anyway, we can have a much simpler solution.
To summarize: if reliability is important on the business level, do it on the business level. A Reliable Messaging layer can handle only generic logic, but that's not what we want: we want business-specific logic for in-order and exactly-once processing. WS-Reliable Messaging (or its competitors) may sometimes have some value in optimizing solutions, especially point-to-point. But from a business perspective, a well-designed business solution does not need reliable messaging.