
写道
在SQL中使用GROUP BY来对SELECT的结果进行数据分组,在具体使用GROUP BY之前需要知道一些重要的规定。
•GROUP BY子句可以包含任意数目的列。也就是说可以在组里再分组,为数据分组提供更细致的控制。
•如果在GROUP BY子句中指定多个分组,数据将在最后指定的分组上汇总。
•GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用了表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
•出了聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
•如果分组列中有NULL值,则NULL将作为一个分组返回。如果有多行NULL值,它们将分为一组。
•GROUP BY子句必须在WHERE子句之后,ORDER BY之前。
过滤分组
对分组过于采用HAVING子句。HAVING子句支持所有WHERE的操作。
•GROUP BY子句可以包含任意数目的列。也就是说可以在组里再分组,为数据分组提供更细致的控制。
•如果在GROUP BY子句中指定多个分组,数据将在最后指定的分组上汇总。
•GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用了表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
•出了聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
•如果分组列中有NULL值,则NULL将作为一个分组返回。如果有多行NULL值,它们将分为一组。
•GROUP BY子句必须在WHERE子句之后,ORDER BY之前。
过滤分组
对分组过于采用HAVING子句。HAVING子句支持所有WHERE的操作。
HAVING与WHERE的区别在于WHERE是过滤行的,而HAVING是用来过滤分组。
另一种理解WHERE与HAVING的区别的方法是,WHERE在分组之前过滤,而HAVING在分组之后以每组为单位过滤。
分组与排序
一般在使用GROUP BY子句时,也应该使用ORDER BY子句。这是保证数据正确排序的唯一方法。
SQL SELECT语句的执行顺序:
1.from子句组装来自不同数据源的数据;
2.where子句基于指定的条件对记录行进行筛选;
3.group by子句将数据划分为多个分组;
4.使用聚集函数进行计算;
5.使用having子句筛选分组;
6.计算所有的表达式;
7.使用order by对结果集进行排序;
8.select 集合输出。
举个例子吧。
select 考生姓名, max(总成绩) as max总成绩
from tb_Grade
where 考生姓名 is not null
group by 考生姓名
having max(总成绩) > 600
order by max总成绩
另一种理解WHERE与HAVING的区别的方法是,WHERE在分组之前过滤,而HAVING在分组之后以每组为单位过滤。
分组与排序
一般在使用GROUP BY子句时,也应该使用ORDER BY子句。这是保证数据正确排序的唯一方法。
SQL SELECT语句的执行顺序:
1.from子句组装来自不同数据源的数据;
2.where子句基于指定的条件对记录行进行筛选;
3.group by子句将数据划分为多个分组;
4.使用聚集函数进行计算;
5.使用having子句筛选分组;
6.计算所有的表达式;
7.使用order by对结果集进行排序;
8.select 集合输出。
举个例子吧。
select 考生姓名, max(总成绩) as max总成绩
from tb_Grade
where 考生姓名 is not null
group by 考生姓名
having max(总成绩) > 600
order by max总成绩
在上面的示例中 SQL 语句的执行顺序如下:
1.首先执行 FROM 子句, 从 tb_Grade 表组装数据源的数据
2.执行 WHERE 子句, 筛选 tb_Grade 表中所有数据不为 NULL 的数据
3.执行 GROUP BY 子句, 把 tb_Grade 表按 "学生姓名" 列进行分组
4.计算 max() 聚集函数, 按 "总成绩" 求出总成绩中最大的一些数值
5.执行 HAVING 子句, 筛选课程的总成绩大于 600 分的.
6.执行 ORDER BY 子句, 把最后的结果按 "Max 成绩" 进行排序.
<!-- 本文来源于 简明现代魔法 http://www.nowamagic.net/ ,转载请务必注明出处 -->
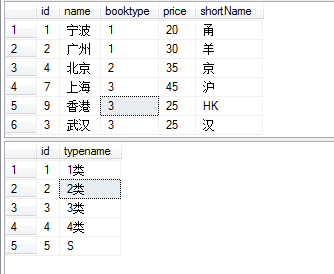
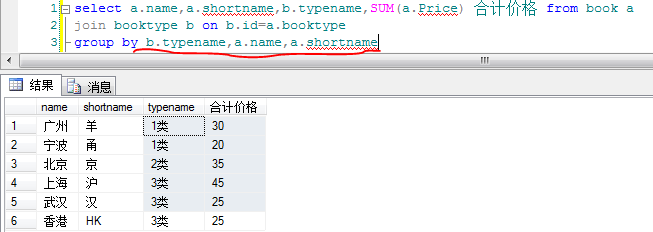
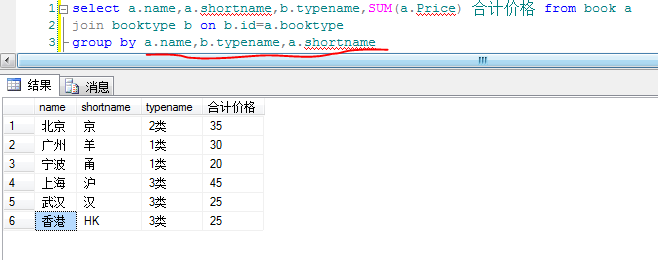
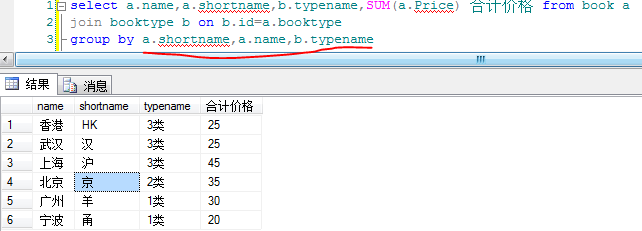
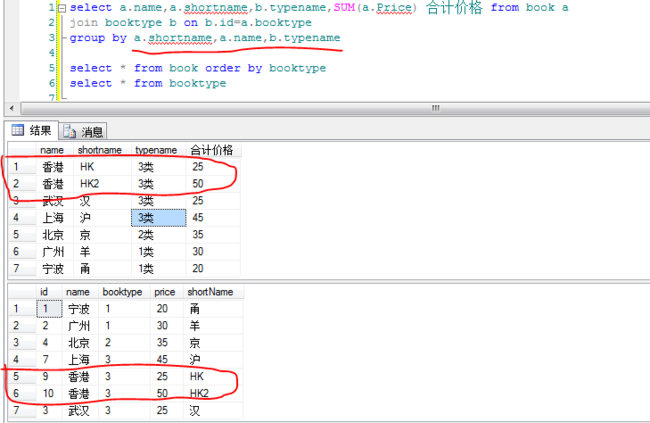
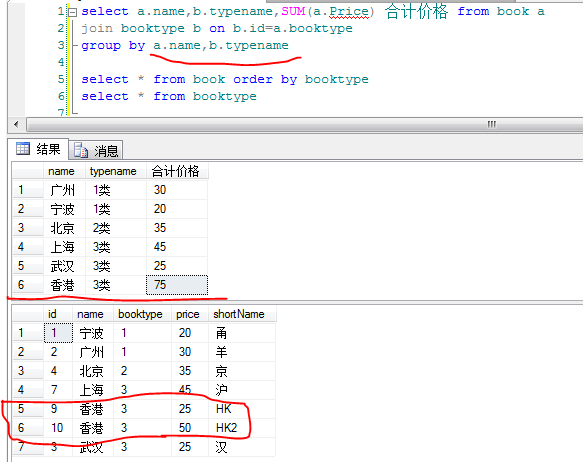
以上只解决了一部分疑问,关于group by后的字段的次序问题还没得到解决
于是自己动手建了两个表,写了几个sql
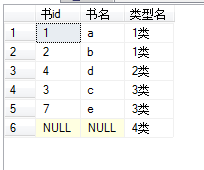
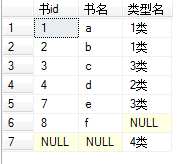
1).两个表的源数据