原文:http://blog.csdn.net/shirdrn/article/details/7055355
附件为配置的core之间的索引数据复制,其中core0为master,core1为slave,在core0中提交数据和优化数据时,core1复制core0中的索引数据。
Solr作为一个搜索服务器,在并发搜索请求的场景下,可能一台服务器很容易就垮掉,这是我们可以通过使用集群技术,设置多台Solr搜索服务器同时对外提供搜索服务,在前端使用类似Nginx的负载均衡软件,可以通过配置使得并发到达的搜索请求均匀地反向代理到Solr集群中的每一台服务器上,这样每台Solr搜索服务器搜索请求的压力可以大大减小,增强了每台服务器能够持续提供服务器的能力。
然而,这时我们面临的问题有:
- 集群中的每台服务器在线上要保证索引数据都能很好地的同步,使得每台搜索服务器的索引数据在一定可以承受的程度上保持一致性;
- 集群中某台服务器宕机离线,人工干预重启后继续与集群中其它服务器索引数据保持一致,继续提供搜索服务;
- 集群中某台服务器的索引数据,由于硬盘故障或人为原因无法提供搜索服务,需要一种数据恢复机制;
- 集群中最先接受数据更新的Master服务器,在将索引更新传播到Slave服务器上时,避免多台Slave服务器同一时间占用大量网络带宽,从而影响了Master提供搜索服务。
事实上,Solr框架在上面的几个方面都能做到不错的支持,具有很大的灵活性。基于上述的几个问题,我们来配置Solr集群的Replication,并实践集群复制的功能。
单机实例Replication
Solr支持在单机上配置多个实例(MultiCore),每个实例都可以独立对外提供服务,共享同一网络带宽。同时,也可以实现单机实例之间Replication,在实例之间复制数据,保证数据的可用性,从而提高系统的服务能力。
我们看一下,这种复制模式的结构图,如下所示:
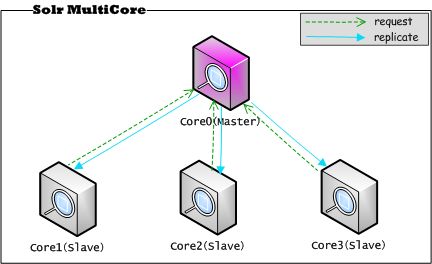
上图,在同一台服务器上,启动Solr的多个实例,将这些实例(通过Core来区分)作为单机上的伪分布式集群,这些Core实例都是在同一个JVM中。选择其中的一个实例Core0作为Master,每次索引更新都首先从这个实例Core0进行传播,直到Master实例Core0与Slave实例Core1、Core2、Core3上的数据同步为止。其中,每个实例都可以独立对外提供服务,因为这种模式保证多个实例上的数据都是同一份数据,起到数据备份的作用,一般不建议让多个实例同时提供服务。下面给出上图复制模式下Solr的配置。
Core0作为Master,对应的solrconfig.xml配置内容,如下所示:
- <?xml version="1.0" encoding="UTF-8" ?>
- <config>
- <luceneMatchVersion>LUCENE_35</luceneMatchVersion>
- <directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.StandardDirectoryFactory}" />
- <updateHandler class="solr.DirectUpdateHandler2" />
- <requestDispatcher handleSelect="true">
- <requestParsers enableRemoteStreaming="false" multipartUploadLimitInKB="2048" />
- </requestDispatcher>
- <requestHandler name="standard" class="solr.StandardRequestHandler" default="true" />
- <requestHandler name="/update" class="solr.JsonUpdateRequestHandler" />
- <requestHandler name="/admin/" class="org.apache.solr.handler.admin.AdminHandlers" />
- <queryParser name="dismax" class="solr.DisMaxQParserPlugin" />
- <requestHandler name="/dismax" class="solr.SearchHandler">
- <lst name="defaults">
- <str name="defType">dismax</str>
- <str name="qf">title content</str>
- <bool name="hl">true</bool>
- <str name="hl.fl">title content</str>
- <int name="hl.fragsize">200</int>
- <int name="hl.snippets">1</int>
- <str name="fl">*,score</str>
- <str name="qt">standard</str>
- <str name="wt">standard</str>
- <str name="version">2.2</str>
- <str name="echoParams">explicit</str>
- <str name="indent">true</str>
- <str name="debugQuery">on</str>
- <str name="explainOther">on</str>
- </lst>
- </requestHandler>
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="master">
- <str name="replicateAfter">startup</str>
- <str name="replicateAfter">commit</str>
- <str name="commitReserveDuration">00:00:10</str>
- </lst>
- </requestHandler>
- <admin>
- <defaultQuery>solr</defaultQuery>
- </admin>
- </config>
上述配置中,提供了一个/dismax搜索接口,对外提供搜索服务。配置中name为/Replication的requestHandler,即为Solr提供的复制请求处理接口,配置中replicateAfter表示在startup和commit之后才允许Slave的复制请求。
Solr支持索引数据Replication,同时也支持配置数据的复制。如果需要复制配置数据做好配置备份,可以在Master的solrconfig.xml中配置如下内容:
- <str name="confFiles">schema.xml,stopwords.txt,solrconfig.xml,synonyms.txt</str>
指定需要从Master上复制的配置文件名即可。
对于Core1~Core3都为Slave,即请求复制数据,我们拿Core1为例,其它配置均相同,但是我们不希望Slave实例对外提供服务,所以只需要配置Slave的/replication复制请求处理接口即可,配置内容如下所示:
- <?xml version="1.0" encoding="UTF-8" ?>
- <config>
- <luceneMatchVersion>LUCENE_35</luceneMatchVersion>
- <directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.StandardDirectoryFactory}" />
- <updateHandler class="solr.DirectUpdateHandler2" />
- <requestDispatcher handleSelect="true">
- <requestParsers enableRemoteStreaming="false" multipartUploadLimitInKB="2048" />
- </requestDispatcher>
- <requestHandler name="standard" class="solr.StandardRequestHandler" default="true" />
- <requestHandler name="/update" class="solr.JsonUpdateRequestHandler" />
- <requestHandler name="/admin/" class="org.apache.solr.handler.admin.AdminHandlers" />
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="slave">
- <str name="masterUrl">http://192.168.0.195:8080/solr35/core0/replication</str>
- <str name="pollInterval">00:00:20</str>
- <str name="compression">internal</str>
- <str name="httpConnTimeout">5000</str>
- <str name="httpReadTimeout">10000</str>
- <str name="httpBasicAuthUser">username</str>
- <str name="httpBasicAuthPassword">password</str>
- </lst>
- </requestHandler>
- <admin>
- <defaultQuery>solr</defaultQuery>
- </admin>
- </config>
Slave配置中masterUrl和pollInterval是必选的,masterUrl指定为core0的复制请求接口,pollInterval是指Slave周期地向Master询问是否数据有所更新,如果发生变更则进行复制。其它的参数可以根据需要进行配置。一般情况下,单机多个实例之间的Replication不需要配置上述httpBasicAuth*的参数的。
启动Solr之前,没有任何索引数据。只有执行了commit和optimize操作,才会触发Slave复制Master的索引数据。我测试了一下通过solr管理页面增加一条数据也不能触发复制,但是通过solrj调用commit提交数据后能够触发复制。
在Master和Slave数据同步的情况下,Master收到Slave的Replication请求:
- 2011-12-9 15:18:00 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
- 2011-12-9 15:18:20 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
- 2011-12-9 15:18:40 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
- 2011-12-9 15:19:00 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
每隔20s间隔,Slave请求一次,这个时间间隔可以根据需要进行配置。
从我们向Master发送索引数据更新索引请求后,在Master和Slave之间执行的数据的复制,处理日志内容可以参考后面附录的内容。
通过日志信息可以看到,Slave在Master更新索引(通过add可以看到更新了5篇文档,日志中给出了文档编号;更新时,每次发送2篇文档执行一次commit,全部发送完成后执行一次commit和optimize操作)之后,通过发送请求获取复制文件列表,然后执行复制过程,最后Slave索引数据发生变化,为保证实时能够搜索到最新内容,重新打开了一个IndexSearcher实例。日志最后面的部分,Slave的索引数据与Master保持同步,不需要复制。
集群结点Replication
在Solr集群中进行配置,与上面单机多实例的情况基本上一致,基本特点是:每个结点上的实例(Core)在同一个JVM内,不同结点之间进行复制——实际上是不同结点上的实例之间进行Replication。集群复制模式架构图,如下所示:
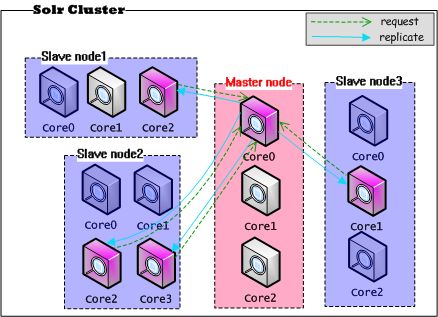
在一个Solr集群中执行Replication,复制请求与动作发生在一个网络内部。而replication的端点是不同结点上的实例(Core),很可能Slave结点上的其它实例在提供其他的服务。
通过上图可以看到,在只有一个Master的Solr集群中,如果存在大量的Slave要求Replication,势必会造成对Master服务器的压力(网络带宽、系统IO、系统CPU)。很可能因为外部大量搜索请求达到,使Master持续提供服务的能力降低,甚至宕机。Solr也考虑到这一点,通过在Master和Slave之间建立一个代理的结点来改善单点故障,代理结点既做Master的Slave,同步Master的数据,同时又做Slave的Master,将最新的数据同步复制到Slave结点,这个结点叫做Repeater,架构图如下所示:
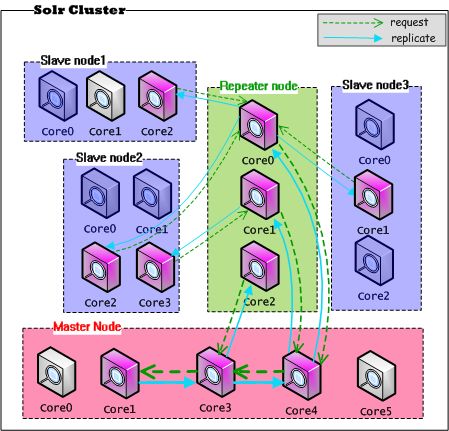
由图可见,Master的压力一下转移到了Repeater结点上,在一定程度上解决了Master的单点问题。对于Reaper结点,它具有双重角色,显而易见,在配置的时候需要配置上Master和Slave都具有的属性。我们给出一个Repeater的配置示例。
Master配置:
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="master">
- <str name="replicateAfter">startup</str>
- <str name="replicateAfter">commit</str>
- <str name="confFiles">schema.xml,stopwords.txt,solrconfig.xml,synonyms.txt</str>
- <str name="commitReserveDuration">00:00:10</str>
- </lst>
- </requestHandler>
Repeater配置:
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="master">
- <str name="replicateAfter">startup</str>
- <str name="replicateAfter">commit</str>
- <str name="commitReserveDuration">00:00:10</str>
- </lst>
- <lst name="slave">
- <str name="masterUrl">http://192.168.0.184:8080/masterapp/master/replication</str>
- <str name="pollInterval">00:00:20</str>
- <str name="compression">internal</str>
- <str name="httpConnTimeout">5000</str>
- <str name="httpReadTimeout">10000</str>
- <str name="httpBasicAuthUser">username</str>
- <str name="httpBasicAuthPassword">password</str>
- </lst>
- </requestHandler>
Slave配置:
- <requestHandler name="/replication" class="solr.ReplicationHandler" >
- <lst name="slave">
- <str name="masterUrl">http://192.168.0.174:8080/repeaterapp/repeater/replication</str>
- <str name="pollInterval">00:00:20</str>
- <str name="compression">internal</str>
- <str name="httpConnTimeout">5000</str>
- <str name="httpReadTimeout">10000</str>
- <str name="httpBasicAuthUser">username</str>
- <str name="httpBasicAuthPassword">password</str>
- </lst>
- </requestHandler>
可见,Solr能够支持这种链式Replication配置,甚至可以配置更多级,但具体如何配置还要依据你的应用的特点,以及资源条件的限制。总之,Solr Replication的目标就是让你系统的数据可用性变得更好。任何时候发生机器故障、硬盘故障、数据错误,都可以从其他的备机上同步数据。