批量下载魔兽replays录像文件
自己是个war3爱好者,也经常去浩方或者VS平台去打打,技术不怎么样但也偶尔去http://w3g.replays.net上去下载些replays学习学习,不过Replays_Net上的录像下载确实麻烦,每个链接都得单个点击进去才能下载,看到有人开发过mp3的批量下载器,所以想想就自己开发个类似这样的下载魔兽replays录像文件的东西,方便自己使用,也方便和我一样的war3爱好者。实现思路很简单,参考一些批量下载的程序,技术没什么新的,实用就行了。
已经修改为Form版本(有需要的留言):
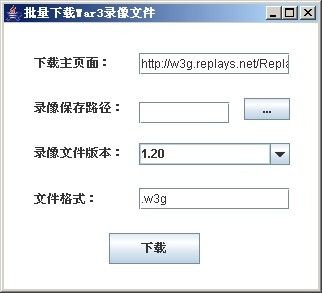
主要代码如下:
War3Replays.java:
package com.moonights.war3replays;
/**
*
* @author moonights
*
*/
public class War3Replays {
/**录像文件名称*/
private String fileName;
/**录像文件大小*/
private String fileSize;
/**录像文件格式*/
private String fileFormat=".w3g";
/**下载地址*/
private String fileUrl;
private String savePath;
public String getFileFormat() {
return fileFormat;
}
public void setFileFormat(String fileFormat) {
this.fileFormat = fileFormat;
}
public String getFileName() {
return fileName;
}
public void setFileName(String fileName) {
this.fileName = fileName;
}
public String getFileSize() {
return fileSize;
}
public void setFileSize(String fileSize) {
this.fileSize = fileSize;
}
public String getFileUrl() {
return fileUrl;
}
public void setFileUrl(String fileUrl) {
this.fileUrl = fileUrl;
}
public String getSavePath() {
return savePath;
}
public void setSavePath(String savePath) {
this.savePath = savePath;
}
}
War3ReplaysDowner.java:
package com.moonights.war3replays;
import java.io.*;
import java.net.*;
import java.util.*;
import java.util.regex.*;
import com.moonights.utils.Configuration;
import com.moonights.utils.HttpGet;
/**
* http://w3g.replays.net 批量下载war3Replays文件的工具,方便喜爱下载魔兽录像的人员使用.
* 目前只实现到解析到二级目录下的页面,可增加递归实现多级页面解析....
*
* @author moonights
*
*/
public class War3ReplaysDowner {
private static Configuration config = new Configuration("config/war3.properties");
private static String DOWNLOAD_INDEX_URL = config.getValue("DOWNLOAD_INDEX_URL");
private static String DOWNLOAD_MAIN_URL = config.getValue("DOWNLOAD_MAIN_URL");// "http://w3g.replays.net/Default.aspx?PageNo=2";
private static String FILE_SAVE_PATH = config.getValue("FILE_SAVE_PATH");// "E:\\temp";
private static String FILE_SAVE_TYPE = config.getValue("FILE_SAVE_TYPE");// ".w3g";
/**
* * 只针对这种类型的url:<a
* href="http://w3g.replays.net/doc/cn/2010-1-25/12644174774532572561.html"
* target="_blank">*
*/
private static final String url_regexp_resources = "<a href=\"(\\w+://[^/:]+[^#\\s]*)\" target=\"_blank\">";
private static final String url_regexp_downloadFile = "<a href=\"(.*?)\">Download REP</a>";
private static final String url_regexp_downloadFileName = "<h3><span id=\"ctl00_Content_labTitle\">(.*?)</span></h3>";
/**
* 根据 URL 读取应对页面的HTML源码
*
* @param url
* 文件的URL
* @return String URL应对页面的HTML源码, 如果连接到指定URL, 则返回一个空字符串("")
*/
public String getHtmlCode(String url) {
try {
URL u = new URL(url);
URLConnection urlConnection = u.openConnection();
urlConnection.setAllowUserInteraction(false);
// 使用openStream得到一输入流并由此构造一个BufferedReader对象
BufferedReader in = new BufferedReader(new InputStreamReader(u
.openStream()));
String inputLine;
StringBuffer tempHtml = new StringBuffer();
while ((inputLine = in.readLine()) != null) { // 从输入流不断的读数据,直到读完为止
tempHtml.append(inputLine).append("\n");
}
return tempHtml.toString();
} catch (IOException e) {
return "";
}
}
/**
* 根据 URL 读取应对页面的HTML源码
*
* @param url
* 文件的URL
* @return String URL应对页面的HTML源码, 如果连接到指定URL, 则返回一个空字符串("")
*/
public static String getHtml(String urlString) {
try {
StringBuffer html = new StringBuffer();
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
InputStreamReader isr = new InputStreamReader(conn.getInputStream());
BufferedReader br = new BufferedReader(isr);
String temp;
while ((temp = br.readLine()) != null) {
html.append(temp).append("\n");
}
br.close();
isr.close();
return html.toString();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 根据url获取该url页面中的所有包含下载资源的url链接() 只针对这种类型的url:<a
* href="http://w3g.replays.net/doc/cn/2010-1-25/12644174774532572561.html"
* target="_blank">
*
* @param 文件的URL
* @return List
* URL应对页面中的所有指定URL:http://w3g.replays.net/doc/cn/2010-1-25/12644174774532572561.html
*/
public List<String> getUrlByURLPage(String url) {
List<String> list = new ArrayList<String>();
String htmlCode = getHtmlCode(url);
Pattern p = Pattern.compile(url_regexp_resources,
Pattern.CASE_INSENSITIVE);
Matcher matcher = p.matcher(htmlCode);
String id = null;
while (matcher.find()) {
id = matcher.group(1);
if (!list.contains(id)) {
list.add(id);
}
}
return list;
}
/**
* 根据获取的包含下载资源的url查询下载资源url连接以及文件名称 (文件名如下:[SW]GaB.RohJinWook vs ieS.Check
* #1.w3g,解析页面中的标题获取,中文有乱码,和手动下载的名称不一致但类似)
*
* @param List
* @return Vector
* {("http://w3g.replays.net/Download.aspx?ReplayID=41162&File=%2fReplayFile%2f2010-1-26%2f100126_%5bUD%5dfantafiction_VS_%5bORC%5dmmmgbp_TwistedMeadows_RN.w3g",
* "e:\\temp\\dmmmgbp_TwistedMeadows_RN.w3g")}
*/
public Vector getWar3ReplaysByTitle(List url_list) {
Vector vector = new Vector();
for (int i = 0; i < url_list.size(); i++) {
String temp_url = url_list.get(i).toString();
String temp_htmlCode = this.getHtmlCode(temp_url);
String fileUrl = getMatcher(url_regexp_downloadFile, temp_htmlCode,
1);
String fileName = getMatcher(url_regexp_downloadFileName,
temp_htmlCode, 1);
if (!fileUrl.equals("") && !fileName.equals("")) {
War3Replays war3Replays = new War3Replays();
fileUrl = DOWNLOAD_INDEX_URL + fileUrl;// 将相对URL修改为绝对URL
// fileName = FILE_SAVE_PATH+"\\"+fileName+FILE_SAVE_TYPE;//
war3Replays.setFileName(fileName);
war3Replays.setFileUrl(fileUrl);
war3Replays.setSavePath(this.FILE_SAVE_PATH);
war3Replays.setFileFormat(this.FILE_SAVE_TYPE);
vector.add(war3Replays);
}
if (i > 0 && i % 10 == 0) {
// 每循环10次后休息2秒再进行请求, 否则可能被当作网络攻击
try {
Thread.sleep(2000);
System.out
.println(">>>>>>>>>>>>>>>>>>>暂停页面抓取,2秒后继续<<<<<<<<<<<<<<<<<<<<<<");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
return vector;
}
/**
* 根据获取的包含下载资源的url链接查询下载War3Replays文件
* (文件名如下:_ReplayFile_2010-1-24_100124__NE_mTw.DIDI8_VS__HM_VeryB1gman._AncientIsles_RN.w3g,解析url获取的)
* 待优化:待简略一些..
*
* @param url_list
* @return
*/
public Vector getWar3ReplaysByUrl(List url_list) {
Vector vector = new Vector();
for (int i = 0; i < url_list.size(); i++) {
String temp_url = url_list.get(i).toString();
String temp_htmlCode = this.getHtmlCode(temp_url);
String fileUrl = getMatcher(url_regexp_downloadFile, temp_htmlCode,
1);
if (!fileUrl.equals("")) {
War3Replays war3Replays = new War3Replays();
fileUrl = DOWNLOAD_INDEX_URL + fileUrl;// 将相对URL修改为绝对URL
war3Replays.setFileUrl(fileUrl);
String regex = "&File=(.*?).w3g";
String fileName = getMatcher(regex, fileUrl, 1);
fileName = fileName.replaceAll("(%2f|%5b|%5d)", "_");
war3Replays.setFileName(fileName);
war3Replays.setSavePath(this.FILE_SAVE_PATH);
war3Replays.setFileFormat(this.FILE_SAVE_TYPE);
vector.add(war3Replays);
}
if (i > 0 && i % 10 == 0) {
// 每循环10次后休息2秒再进行请求, 否则可能被当作网络攻击
try {
Thread.sleep(2000);
System.out
.println(">>>>>>>>>>>>>>>>>>>暂停页面抓取,2秒后继续<<<<<<<<<<<<<<<<<<<<<<");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
return vector;
}
public static String getMatcher(String regex, String source, int group) {
String result = "";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(source);
while (matcher.find()) {
result = matcher.group(group);
}
return result;
}
/**
* 下载获取到的war3replays录像文件 方法一
*/
public void downWar3Replays_WAY1() {
List url_list = this.getUrlByURLPage(DOWNLOAD_MAIN_URL);
Vector vector = this.getWar3ReplaysByUrl(url_list);
HttpGet downer = new HttpGet();
if (vector.size() > 0) {
for (int i = 0; i < vector.size(); i++) {
War3Replays war3Replays = (War3Replays) vector.get(i);
try {
// 增加下载列表(此处用户可以写入自己代码来增加下载列表)
downer.addItem(war3Replays.getFileUrl(), war3Replays
.getSavePath()
+ "\\"
+ war3Replays.getFileName()
+ war3Replays.getFileFormat());
// 开始下载
} catch (Exception err) {
System.out.println(err.getMessage());
}
}
System.out.println("开始下载.");
downer.downLoadByList();
System.out.println("下载完毕.");
}
}
/**
* 下载获取到的war3replays录像文件 方法二
*/
public void downWar3Replays_WAY2() {
List url_list = this.getUrlByURLPage(DOWNLOAD_MAIN_URL);
Vector vector = this.getWar3ReplaysByTitle(url_list);
HttpGet downer = new HttpGet();
if (vector.size() > 0) {
for (int i = 0; i < vector.size(); i++) {
War3Replays war3Replays = (War3Replays) vector.get(i);
try {
// 增加下载列表(此处用户可以写入自己代码来增加下载列表)
downer.addItem(war3Replays.getFileUrl(), war3Replays
.getSavePath()
+ "\\"
+ war3Replays.getFileName()
+ war3Replays.getFileFormat());
// 开始下载
} catch (Exception err) {
System.out.println(err.getMessage());
}
}
System.out.println("开始下载.");
downer.downLoadByList();
System.out.println("下载完毕.");
}
}
}
HttpGet.java:
package com.moonights.utils;
import java.io.*;
import java.net.*;
import java.util.*;
/**
* Description: 将指定的HTTP网络资源在本地以文件形式存放
*/
public class HttpGet {
public final static boolean DEBUG = true;// 调试用
private static int BUFFER_SIZE = 8096;// 缓冲区大小
private Vector vDownLoad = new Vector();// URL列表
private Vector vFileList = new Vector();// 下载后的保存文件名列表
/**
* 构造方法
*/
public HttpGet() {
}
/**
* 清除下载列表
*/
public void resetList() {
vDownLoad.clear();
vFileList.clear();
}
/**
* 增加下载列表项
*
* @param url
* String
* @param filename
* String
*/
public void addItem(String url, String filename) {
vDownLoad.add(url);
vFileList.add(filename);
}
/**
* 根据列表下载资源
*/
public void downLoadByList() {
String url = null;
String filename = null;
// 按列表顺序保存资源
for (int i = 0; i < vDownLoad.size(); i++) {
url = (String) vDownLoad.get(i);
filename = (String) vFileList.get(i);
try {
saveToFile(url, filename);
} catch (IOException err) {
if (DEBUG) {
System.out.println("资源[" + url + "]下载失败!!!");
}
}
/*if(i>0 && i%5==0){
// 每循环5次后休息2秒再进行请求, 否则可能被当作网络攻击
try {
//Thread.sleep(2000);
//System.out.println(">>>>>>>>>>>>>>>>>>>暂停下载,2秒后继续<<<<<<<<<<<<<<<<<<<<<<");
}catch (InterruptedException e) {
e.printStackTrace();
}
}*/
}
if (DEBUG) {
System.out.println("下载完成!!!");
}
}
/**
* 将HTTP资源另存为文件
*
* @param destUrl
* String
* @param fileName
* String
* @throws Exception
*/
public void saveToFile(String destUrl, String fileName) throws IOException {
FileOutputStream fos = null;
BufferedInputStream bis = null;
HttpURLConnection httpUrl = null;
URL url = null;
byte[] buf = new byte[BUFFER_SIZE];
int size = 0;
// 建立链接
url = new URL(destUrl);
httpUrl = (HttpURLConnection) url.openConnection();
// 连接指定的资源
httpUrl.connect();
// 获取网络输入流
bis = new BufferedInputStream(httpUrl.getInputStream());
// 建立文件
fos = new FileOutputStream(fileName);
//判断是否存在该文件,如果存在将文件名称修改为另外一个。。。。
if (this.DEBUG)
System.out.println("正在获取链接[" + destUrl + "]的内容...\n将其保存为文件["
+ fileName + "]");
// 保存文件
while ((size = bis.read(buf)) != -1)
fos.write(buf, 0, size);
fos.close();
bis.close();
httpUrl.disconnect();
}
/**
* 设置代理服务器
*
* @param proxy
* String
* @param proxyPort
* String
*/
public void setProxyServer(String proxy, String proxyPort) {
// 设置代理服务器
System.getProperties().put("proxySet", "true");
System.getProperties().put("proxyHost", proxy);
System.getProperties().put("proxyPort", proxyPort);
}
/**
* 设置认证用户名与密码
*
* @param uid
* String
* @param pwd
* String
*/
/*public void setAuthenticator(String uid, String pwd) {
Authenticator.setDefault(new MyAuthenticator(uid, pwd));
}*/
/**
* 主方法(用于测试)
*
* @param argv
* String[]
*/
public static void main(String argv[]) {
HttpGet oInstance = new HttpGet();
try {
// 增加下载列表(此处用户可以写入自己代码来增加下载列表)
oInstance.addItem("http://xiazai.xiazaiba.com/0905/0504/2k3IIS6_XiaZaiBa.rar","e:\\temp\\iis6_2.rar");
// 开始下载
oInstance.downLoadByList();
} catch (Exception err) {
System.out.println(err.getMessage());
}
}
}
Configuration.java:
package com.moonights.utils;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
/**
* 读取properties文件
* @author moonights
*
*/
public class Configuration
{
private Properties propertie;
private InputStream inputFile;
private FileOutputStream outputFile;
/**
* 初始化Configuration类
*/
public Configuration(){
propertie = new Properties();
}
/**
* 初始化Configuration类
* @param filePath 要读取的配置文件的路径+名称
*/
public Configuration(String filePath){
propertie = new Properties();
try {
//inputFile = (InputStream) this.getClass().getResourceAsStream(filePath);
inputFile = this.getClass().getClassLoader().getResourceAsStream(filePath);
propertie.load(inputFile);
inputFile.close();
} catch (FileNotFoundException ex) {
System.out.println("读取属性文件--->失败!- 原因:文件路径错误或者文件不存在");
ex.printStackTrace();
} catch (IOException ex) {
System.out.println("装载文件--->失败!");
ex.printStackTrace();
}
}//end ReadConfigInfo()
/**
* 重载函数,得到key的值
* @param key 取得其值的键
* @return key的值
*/
public String getValue(String key){
if(propertie.containsKey(key)){
String value = propertie.getProperty(key);//得到某一属性的值
return value;
}
else
return "";
}
/**
* 重载函数,得到key的值
* @param fileName properties文件的路径+文件名
* @param key 取得其值的键
* @return key的值
*/
public String getValue(String fileName, String key){
try {
String value = "";
inputFile = new FileInputStream(fileName);
propertie.load(inputFile);
inputFile.close();
if(propertie.containsKey(key)){
value = propertie.getProperty(key);
return value;
}else
return value;
} catch (FileNotFoundException e) {
e.printStackTrace();
return "";
} catch (IOException e) {
e.printStackTrace();
return "";
} catch (Exception ex) {
ex.printStackTrace();
return "";
}
}//end getValue()
/**
* 清除properties文件中所有的key和其值
*/
public void clear(){
propertie.clear();
}//end clear();
/**
* 改变或添加一个key的值,当key存在于properties文件中时该key的值被value所代替,
* 当key不存在时,该key的值是value
* @param key 要存入的键
* @param value 要存入的值
*/
public void setValue(String key, String value){
propertie.setProperty(key, value);
}//end setValue()
/**
* 将更改后的文件数据存入指定的文件中,该文件可以事先不存在。
* @param fileName 文件路径+文件名称
* @param description 对该文件的描述
*/
public void saveFile(String fileName, String description){
try {
outputFile = new FileOutputStream(fileName);
propertie.store(outputFile, description);
outputFile.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException ioe){
ioe.printStackTrace();
}
}//end saveFile()
/**
* 测试
* @param args
*/
}
Main.java:程序入口
package com.moonights.war3replays;
/**
* 程序入口。
* @author moonights
*
*/
public class Main {
public static void main(String[] args) {
War3ReplaysDowner war3_Downer = new War3ReplaysDowner();
//war3_Downer.downWar3Replays_WAY1();
war3_Downer.downWar3Replays_WAY2();
}
}
war3.properties:配置文件
##下载首页面 DOWNLOAD_INDEX_URL = http://w3g.replays.net ##下载主页面(修改该变量即可) DOWNLOAD_MAIN_URL = http://w3g.replays.net/ReplayList.aspx?GameRace=3&PageNo=6 ##灵活下载多个页面中的资源 (暂时未实现) PageNo=5 MAX_PageNo=50 ##文件保存路径 FILE_SAVE_PATH=F:\\1.22\\hum ##文件格式 FILE_SAVE_TYPE=.w3g
程序还有挺多需要改进的地方,文件路径必须先有,时间问题没有做过多的考虑,希望有哪位提提意见,优化一下。如果有人修改成界面的,那就更好了。![]()