1.s option
$ cat pets.txt This is my cat my cat's name is betty This is my dog my dog's name is frank This is my fish my fish's name is george This is my goat my goat's name is adam
sed "s/my/Fei's/g" pets.txt
sed "s/my/Fei's/g" pets.txt > fei_pets.txt
sed -i "s/my/Fei's/g" pets.txt
sed 's/^/#/g' pets.txt
sed 's/$/ --- /g' pets.txt
regex tips:
^ 表示一行的开头。如:/^#/ 以#开头的匹配。
$ 表示一行的结尾。如:/}$/ 以}结尾的匹配。
\< 表示词首。 如 \<abc 表示以 abc 为首的詞。
\> 表示词尾。 如 abc\> 表示以 abc 結尾的詞。
. 表示任何单个字符。
* 表示某个字符出现了0次或多次。
[ ] 字符集合。 如:[abc]表示匹配a或b或c,还有[a-zA-Z]表示匹配所有的26个字符。如果其中有^表示反,如[^a]表示非a的字符
$ cat html.txt:
<b>This</b> is what <span style="text-decoration: underline;">I</span> meant. Understand?
sed 's/<[^>]*>//g' html.txt
=>This is what I meant. Understand?
sed "3s/my/your/g" pets.txt #replace third row
sed "3,6s/my/your/g" pets.txt #replace third to sixth rows
$ cat my.txt This is my cat, my cat's name is betty This is my dog, my dog's name is frank This is my fish, my fish's name is george This is my goat, my goat's name is adam
sed 's/s/S/1' my.txt #replace only first 's'
sed 's/s/S/2' my.txt #replace only second 's'
sed 's/s/S/3g' my.txt #replace after third(contain) 's'
$ sed 's/\<Thi/Tha/g' my.txt Thas is my cat, my cat's name is betty Thas is my dog, my dog's name is frank Thas is my fish, my fish's name is george Thas is my goat, my goat's name is adam $ sed 's/his\>/hat/g' my.txt That is my cat, my cat's name is betty That is my dog, my dog's name is frank That is my fish, my fish's name is george That is my goat, my goat's name is adam
2.Multiple matching
sed '1,3s/my/your/g; 3,$s/This/That/g' my.txt
sed -e '1,3s/my/your/g' -e '3,$s/This/That/g' my.txt
#use & replace matched var
sed 's/my/[&]/g' my.txt
3.() matching
#use \1,\2,... replace matched ()
sed 's/This is my \([^,]*\),.*is \(.*\)/\1:\2/g' my.txt
4.sed command
1)N : Read/append the next line of input into the pattern space.
sed 'N;s/my/your/' pets.txt
sed 'N;s/\n/,/' pets.txt
2)add new row
a : after append row
i : before insert row
#specify row number,1 first isrow, $ is last row
sed "1 i This is my monkey, my monkey's name is wukong" my.txt
sed "1 a This is my monkey, my monkey's name is wukong" my.txt
#pattern match
sed "/fish/a This is my monkey, my monkey's name is wukong" my.txt
sed "/my/a ----" my.txt
3)c : replace matched row
sed "2 c This is my monkey, my monkey's name is wukong" my.txt
sed "2 c This is my monkey, my monkey's name is wukong" my.txt
4)d : delete matched rows
sed '/fish/d' my.txt
sed '2d' my.txt
sed '2,$d' my.txt
5)p : print rows,like grep
sed -n '/fish/p' my.txt
#print from dog to fish rows
sed -n '/dog/,/fish/p' my.txt
sed -n '1,/fish/p' my.txt
sed -n '/fish/,/$/p' my.txt
5.Other knowledge points
1)Pattern Space
-n parameter
2)Address
#relative position, +3
sed '/dog/,+3s/^/# /g' pets.txt
3)Command Package
sed '3,6 {/This/d}' pets.txt
sed '3,6 {/This/{/fish/d}' pets.txt
sed '1,$ {/This/d; s/^ *//g' pets.txt
4)Hold Space
g|G : rewrite|append content from hold space to pattern spac.
h|H : rewrite|append content from pattern space to hold space
x : swap content between pattern space and hold space
$ cat t.txt one two three
$sed 'H;g' t.txt

$sed '1!G;h;$!d' t.txt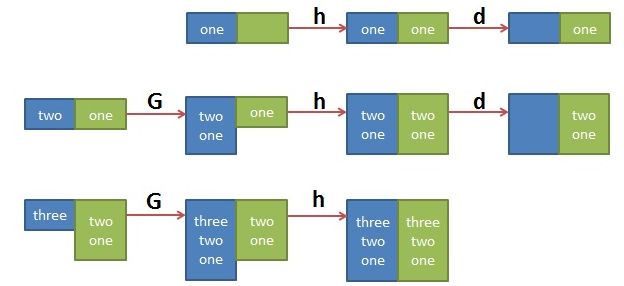
Refers:
http://coolshell.cn/articles/9104.html