The Apache Crunch Java library provides a framework for writing, testing, and running MapReduce pipelines. Its goal is to make pipelines that are composed of many user-defined functions simple to write, easy to test, and efficient to run. Running on top of Hadoop MapReduce, the Apache Crunch library is a simple Java API for tasks like joining and data aggregation that are tedious to implement on plain MapReduce. The APIs are especially useful when processing data that does not fit naturally into relational model, such as time series, serialized object formats like protocol buffers or Avro records, and HBase rows and columns. For more information, you can visit Apache Crunch Homepage.
In this blog post, I'll show you how to write a word counting programming that you might familiar with if you know Hadoop, it's Hello World in Hadoop world. Firstly, let's look at the basic concepts in Crunch, including its type system and pipelined architecture.
The crunch pipeline is represented with the Pipeline interface and MRPipeline implementation class, as you can see in below class outline:
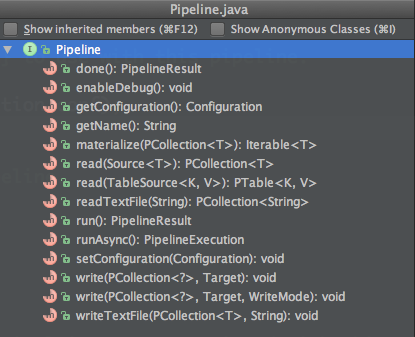 As you can see, the pipeline class contains methods to read and write collections. These collection classes have methods to perform operations on the contents of collections to produce a new result collection. Therefore, a pipeline consists of the definition of one or more input collections, a number of operations on these intermediary collections, and the writing of the collections to data sinks. The execution of all the actual pipeline operations is delayed until the run or done methods are called, at which point Crunch translates the pipeline into one or more MapReduce jobs and starts their execution.
The Pipeline interface defines a readTextFile method that takes in a String and returns a PCollection of Strings. In addition to text files, the library supports reading data from SequenceFiles and Avro container files, via the SequenceFileSource and AvroFileSource classes defined in the org.apache.crunch.io package. Note that each PCollection is a reference to a source of data, no data is actually loaded into a PCollection on the client machine.
As you can see, the pipeline class contains methods to read and write collections. These collection classes have methods to perform operations on the contents of collections to produce a new result collection. Therefore, a pipeline consists of the definition of one or more input collections, a number of operations on these intermediary collections, and the writing of the collections to data sinks. The execution of all the actual pipeline operations is delayed until the run or done methods are called, at which point Crunch translates the pipeline into one or more MapReduce jobs and starts their execution.
The Pipeline interface defines a readTextFile method that takes in a String and returns a PCollection of Strings. In addition to text files, the library supports reading data from SequenceFiles and Avro container files, via the SequenceFileSource and AvroFileSource classes defined in the org.apache.crunch.io package. Note that each PCollection is a reference to a source of data, no data is actually loaded into a PCollection on the client machine.
In Crunch the collection interface represent a distributed set of elements. A collection can be created in one of two ways: as a result of a read method invocation on the Pipeline class, or as a result of an operation on another collection. There are three types of collections in Crunch, as below figure shown: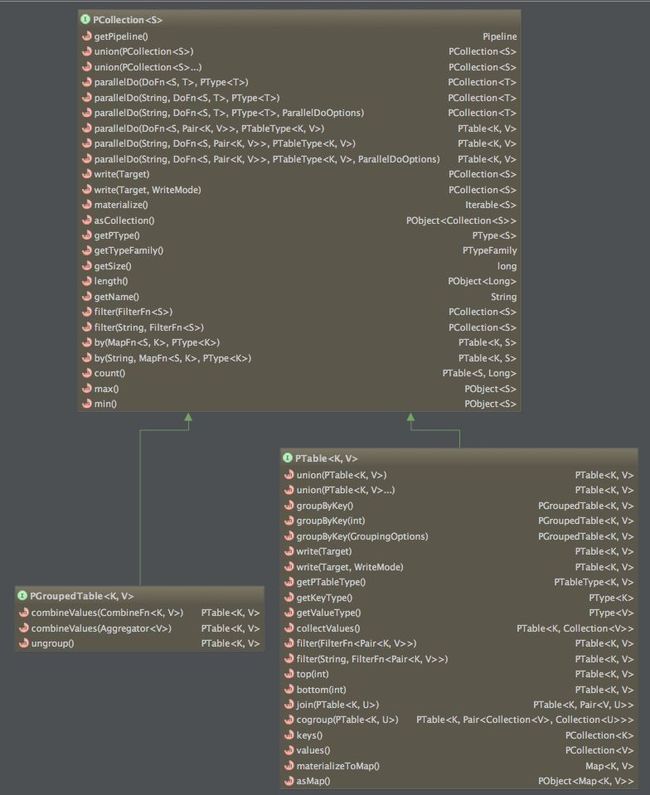 Collection classes contains a number of methods, which operate on the contents of the collections, these operations are executed in either the map or reduce phase. Among them, the PGroupedTable is a special collection that's a result of calling groupByKey method on the PTable, this results in a reduce phase being executed to perform the grouping.
Functions can be applied to the collections that you just saw using parallelDo method in the collection interface. All the parallelDo methods take a DoFn inplementation, which perform the actual operation on the collection in MapReduce, you can see the DoFn class in below figure:
Collection classes contains a number of methods, which operate on the contents of the collections, these operations are executed in either the map or reduce phase. Among them, the PGroupedTable is a special collection that's a result of calling groupByKey method on the PTable, this results in a reduce phase being executed to perform the grouping.
Functions can be applied to the collections that you just saw using parallelDo method in the collection interface. All the parallelDo methods take a DoFn inplementation, which perform the actual operation on the collection in MapReduce, you can see the DoFn class in below figure:
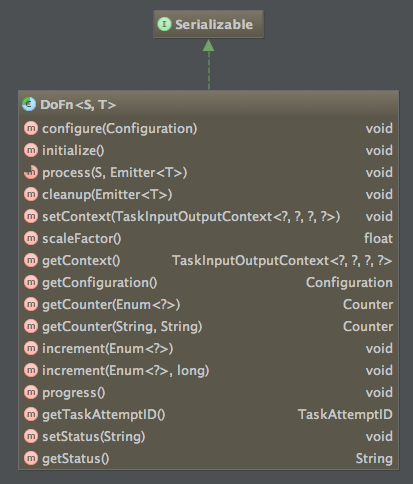 As you can see, all DoFn instances are required to be java.io.Serializable. This is a key aspect of the library's design: once a particular DoFn is assigned to the Map or Reduce stage of a MapReduce job, all of the state of that DoFn is serialized so that it may be distributed to all of the nodes in the Hadoop cluster that will be running that task. There are two important implications of this for developers:
As you can see, all DoFn instances are required to be java.io.Serializable. This is a key aspect of the library's design: once a particular DoFn is assigned to the Map or Reduce stage of a MapReduce job, all of the state of that DoFn is serialized so that it may be distributed to all of the nodes in the Hadoop cluster that will be running that task. There are two important implications of this for developers:
- All member values of a DoFn must be either serializable or marked as transient.
- All anonymous DoFn instances must be defined in a static method or in a class that is itself serializable.
Sometimes you will need to work with non-serializable objects inside of a DoFn, every DoFn provides an initialize method that is called before the process method is ever called so that any initialization tasks, such as creating a non-serializable member variable, can be performed before processing begins. Similarly, all DoFn instances have a cleanup method that may be called after processing has finished to perform any required cleanup tasks.
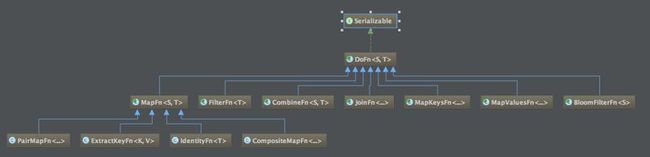
Crunch comes with a bunch of built-in operations (joining, grouping, counting, etc.), which represent MapReduce operations that you commonly perform on you data. Because Crunch already has these operations defined, you don't need to wrestle with MapReduce to write your own. You can also define your own custom operations if you want to. The class hierarchy of built-in operations shown as below figure:
The parallelDo method on the PCollection interface all take either a PType or PTableType argument, depending on whether the result was a PCollection or PTable. These interfaces are used by Crunch to map between the data types used in the Crunch pipeline, and the serialization format used when reading or writing data in HDFS. The class hierarchy of types in Crunch shown as below:
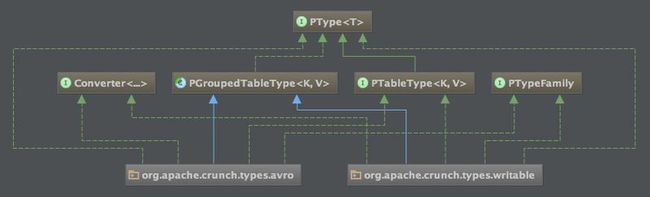
As you can see, Crunch has serializatio support for both native Hadoop Writable classes as well as Avro types.
Now let's look at the WordCount in Crunch:
package crunch;
import org.apache.crunch.*;
import org.apache.crunch.impl.mr.MRPipeline;
import org.apache.crunch.lib.Aggregate;
import org.apache.crunch.types.writable.Writables;
public class WordCount {
public static void main(String[] args) throws Exception {
Pipeline pipeline = new MRPipeline(WordCount.class);
PCollection<String> lines = pipeline.readTextFile(args[0]);
PCollection<String> words = lines.parallelDo("my splitter", new DoFn<String, String>() {
public void process(String line, Emitter<String> emitter) {
for (String word : line.split("\\s+")) {
emitter.emit(word);
}
}
}, Writables.strings());
PTable<String, Long> counts = Aggregate.count(words);
pipeline.writeTextFile(counts, args[1]);
pipeline.run();
}
}
Simple enough, right? Let's go through this example line by line.
Step 1: creating a Pipeline and reference a text file. Note the keyword reference here, no data is actually loaded into a PCollection on the client machine.
Step 2: Splitting the lines of text into words.
- The first argument to parallelDo is a string that is used to identify this step in the pipeline. When a pipeline is composed into a series of MapReduce jobs, it is often the case that multiple stages will run within the same Mapper or Reducer. Having a string that identifies each processing step is useful for debugging errors that occur in a running pipeline.
- The second argument to parallelDo is an anonymous subclass of DoFn. Each DoFn subclass must override the process method, which takes in a record from the input PCollection and an Emitter object that may have any number of output values written to it. In this case, our DoFn splits each lines up into words, using a blank space as a separator, and emits the words from the split to the output PCollection.
- The last argument to parallelDo is an instance of the PType interface, which specifies how the data in the output PCollection is serialized. While the API takes advantage of Java Generics to provide compile-time type safety, the generic type information is not available at runtime. The job planner needs to know how to map the records stored in each PCollection into a Hadoop-supported serialization format in order to read and write data to disk. Two serialization implementations are supported in Crunch via the PTypeFamily interface: a Writable-based system that is defined in the org.apache.crunch.types.writable package, and an Avro-based system that is defined in the org.apache.crunch.types.avro package. Each implementation provides convenience methods for working with the common PTypes (Strings, longs, bytes, etc.) as well as utility methods for creating PTypes from existing Writable classes or Avro schemas.
Step 3: counting the words. This is acomplished by the Aggregate.count(...) method, let's look at it's implementation.
/**
* Returns a {@code PTable} that contains the unique elements of this collection mapped to a count
* of their occurrences.
*/
public static <S> PTable<S, Long> count(PCollection<S> collect) {
// get the PTypeFamily that is associated with the PType for the collection.
PTypeFamily tf = collect.getTypeFamily();
return collect.parallelDo("Aggregate.count", new MapFn<S, Pair<S, Long>>() {
public Pair<S, Long> map(S input) {
return Pair.of(input, 1L);
}
}, tf.tableOf(collect.getPType(), tf.longs())).groupByKey()
.combineValues(Aggregators.SUM_LONGS());
}
The call to parallelDo converts each record in this PCollection into a Pair of the input record and the number 1 by extending the MapFn convenience subclass of DoFn, and uses the tableOf method of the PTypeFamily to specify that the returned PCollection should be a PTable instance, with the key being the PType of the PCollection and the value being the Long implementation for this PTypeFamily.
The groupByKey operation may only be applied to a PTable, and returns an instance of the PGroupedTable interface, which references the grouping of all of the values in the PTable that have the same key. The groupByKey operation is what triggers the reduce phase of a MapReduce.
// In Aggregators.java
/**
* Sum up all {@code long} values.
* @return The newly constructed instance
*/
public static Aggregator<Long> SUM_LONGS() {
return new SumLongs();
}
private static class SumLongs extends SimpleAggregator<Long> {
private long sum = 0;
@Override
public void reset() {
sum = 0;
}
@Override
public void update(Long next) {
sum += next;
}
@Override
public Iterable<Long> results() {
return ImmutableList.of(sum);
}
}
The combineValues operator takes a CombineFn as an argument, which is a specialized subclass of DoFn that operates on an implementation of Java's Iterable interface. The use of combineValues (as opposed to parallelDo) signals to the planner that the CombineFn may be used to aggregate values for the same key on the map side of a MapReduce job as well as the reduce side.
Step 4: writing the output and running the pipeline. The writeTextFile convenience method indicating that a PCollection should be written to a text file. There are also output targets for SequenceFiles and Avro container files, available in the org.apache.crunch.io package.
Step 5: after you are finished constructing a pipeline and specifying the output destinations, call the pipeline's blocking run method in order to compile the pipeline into one or more MapReduce jobs and execute them. You can also call the non-blocking runAsync() method to return PipeLineExecution object to allow clients to control job execution.
/**
* Constructs and executes a series of MapReduce jobs in order to write data
* to the output targets.
*/
PipelineResult run();
/**
* Constructs and starts a series of MapReduce jobs in order ot write data to
* the output targets, but returns a {@code ListenableFuture} to allow clients to control
* job execution.
* @return
*/
PipelineExecution runAsync();
The class hierarchy of PipelineExecution shown as below:
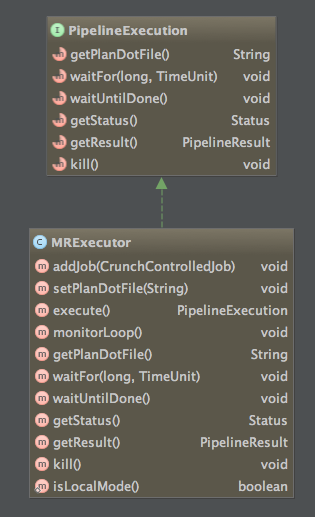
With the returned instance of PipelineExecution, you can control a Crunch pipeline as it runs, this interface is implemented to be thread safe. For example, you can query the job status by calling getStatus(), wait for a specified time interval by calling waitFor(long, TimeUnit), kill the job by calling kill() and so on, see the class diagram for details.