服务器集群对于高度可扩展的 Java 企业级应用程序开发已司空见惯,但是应用程序级别的服务器集群感知目前并不属于 Java EE 的一部分。在本文中,Mukul Gupta 和 Paresh Paladiya 向您介绍如何利用 Apache ZooKeeper 和 LinkedIn 的 Project Norbert 这两个开源项目在分布式企业 Java 应用程序中实现服务器组协调。
2![]() 评论:
评论:
2013 年 1 月 29 日
-
 内容
内容
如今,许多企业应用程序都由一组合作的分布式进程和服务器交付。例如,可向几乎所有流行的 Java 企业服务器的 Web 请求提供服务器集群功能,这些服务器还可以提供有限的配置选项,如服务器权重和配置重新加载。
虽然大多数 Java 企业服务器具有集群的内置支持,但对于自定义用例来说,在应用程序级并没有现成提供这种支持。作为软件开发人员,我们应该如何管理涉及分布式任务协调或支持多租户应用程序的用例?(多租户应用程序 是要求实例在整体服务器集群或组的子集上被隔离的应用程序。)对于这些类型的用例,我们必须找到一种方法,使得组协调功能在应用程序软件层上可用,最好能在高级别的抽象层上提供。
在本文中,我们提供了将组成员和管理功能融合到分布式 Java 应用程序中的指南。我们将从一个基于 Spring Integration 的模拟 Java 应用程序开始,利用基于两个开源项目(Apache ZooKeeper 和 LinkedIn 的 Project Norbert)的服务器集群抽象层来进行构建。
服务器集群概述
服务器集群感知的应用程序通常至少需要以下功能:
- 具有状态维护和查询功能的组成员:需要实时组成员,以便在一组活动的服务器上分发处理。为了管理组成员,应用程序必须能够建立一个进程/服务器组,并跟踪该组中所有服务器的状态。当某台服务器停机或上线时,它还必须能够通知活动的服务器。该应用程序将只在集群中的活动服务器之间对服务请求执行路由和负载均衡,从而帮助确保实现高可用的服务。
- 主要进程或领袖进程:这是一个在集群中的进程,负责维护整个服务器集群的同步状态的协调功能。选择领袖进程的机制是被称为分布式共识 的一组更广泛的问题中的一个特例。(两阶段提交和三阶段提交是众所周知的分布式共识问题。)
- 任务协调和动态的领袖服务器选举:在应用程序级别,领袖服务器 负责任务协调,通过集群中的其他(跟随者)服务器之间分发任务来做到这一点。拥有一台领袖服务器,可以消除服务器之间潜在的争用,否则争用将需要某种形式的互斥或锁定,才可以使符合资格的任务运行(例如,服务器对来自公共数据存储的任务进行轮询)。正是动态领袖选举使得分布式处理变得可靠;如果领袖服务器崩溃,可以选举新的领袖继续处理应用程序任务。
- 组通信:在一个集群感知的应用程序中的应用程序应该能够在整个服务器集群中促进结构化数据和命令的高效交换。
- 分布式锁和共享数据:如果有需要,分布式应用程序应该能够访问的特性包括分布式锁和共享数据结构,如队列和映射。
示例:Spring Integration
我们的代表示例是一个企业应用程序集成 (EAI) 场景,我们将利用基于 Spring Integration 的模拟应用程序处理该场景。该应用程序具有以下特征和要求:
- 一个模拟源应用程序产生与集成相关的事件和消息作为其日常事务处理的一部分,并将它们存储在一个数据存储中。
- 集成事件和消息由一组分布式 Java 进程(一个服务器集群)进行处理,这些进程可以在同一台服务器上运行,也可以分布在由一个高性能网络连接的多台计算机上。需要服务器集群来实现可扩展性和高可用性。
- 每个集成事件只由任一集群成员(即特定的 JVM)处理一次。输出消息通过 Intranet 或 Internet 被传递给合作伙伴应用程序(如果适用)。
图 1 显示了集成事件和从模拟源应用程序出站的消息处理流。
图 1. 基于 Spring Integration 的示例应用程序示意图
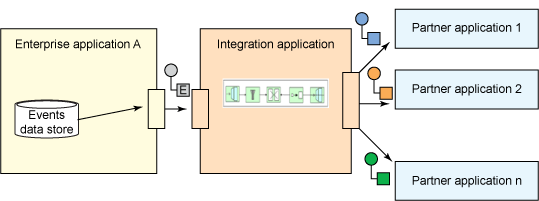
设计解决方案的架构
要为该用例开发一个解决方案,第一步是分发要在一个服务器集群上运行的集成应用程序。这应该能增加处理吞吐量,并能确保高可用性和可扩展性。单次进程的失败不会中止整个应用程序。
一旦完成分配,集成应用程序将从应用程序的数据存储中获得集成事件。服务器集群中的单台服务器将通过一个合适的应用程序适配器从事件存储获取应用程序事件,然后将这些事件分发给集群中的其余服务器进行处理。这个单台服务器担任领袖服务器,或任务协调者 的角色,负责将事件(处理任务)分发给整个集群中的其余服务器。
支持集成应用程序的服务器集群成员在配置时已众所周知。每当有新服务器启动,或有任何服务器崩溃或停机时,集群成员信息就会动态分发给所有运行的服务器。同样,任务协调者服务器也是动态选择的,如果任务协调者服务器崩溃或变得不可用,将从其余运行中的服务器中以合作方式选一个备用的领袖服务器。集成事件可能由支持企业集成模式 (Enterprise Integration Patterns, EIP) 的多个开源 Java 框架其中之一处理(参见 参考资料)。
图 2 显示了用例解决方案的示意图和组件,我们会在下一节中进一步描述它们。
图 2. 用例解决方案的示意图和服务器集群组件
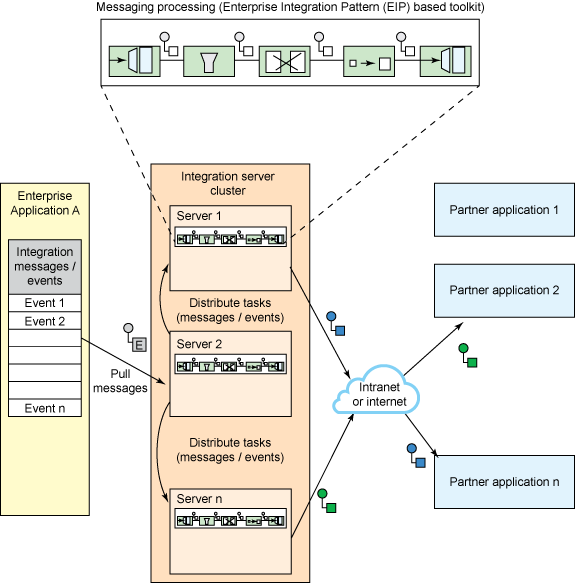
服务器集群
我们的集成应用程序需要服务器组相关的特性,但是无论是 Java 标准版 (Java SE) 还是 Java 企业版 (Java EE) 均没有现成提供这些特性。这些示例包括服务器集群和动态服务器领袖选举。
图 3 显示了我们将用于实施我们的 EAI 解决方案的开源工具,即 Spring Integration 实现事件处理,以及 Apache ZooKeeper 和 LinkedIn Project Norbert 实现集群感知。
图 3. 服务器集群的技术映射
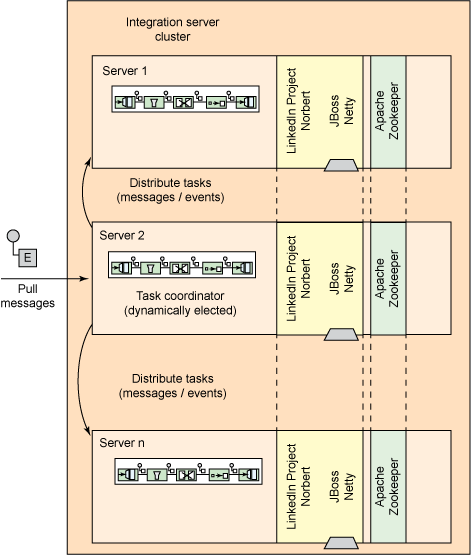
关于模拟的应用程序
模拟应用程序的目的是演示如何使用 Apache ZooKeeper 和 Project Norbert 来解决在开发基于 Java 的服务器集群中所面临的常见挑战。该应用程序的工作原理如下:
- 应用程序事件存储由一个共享文件夹来模拟,集成服务器集群内的所有服务器都可以访问该文件夹。
- 使用保存在此共享文件夹上的文件(以及其数据)来模拟集成事件。也可以使用外部脚本来不断创建文件,从而模拟事件的创建。
- 基于 Spring Integration 的文件轮询组件(入站事件适配器)从应用程序事件存储获取事件,这是由共享文件系统文件夹模拟的事件。然后,文件数据被分发到其余的服务器集群成员进行处理。
- 事件处理的模拟方法是:用简短的标头类型信息(比如
server id和timestamp)作为文件数据的前缀。 - 合作伙伴应用程序由其他一些独特的共享文件系统模拟文件夹,每个合作伙伴应用程序对应一个文件夹。
现在已概述过示例用例、建议的解决方案架构,以及模拟的应用程序。现在,我们准备介绍服务器集群和任务分发解决方案的两个主要组件:Apache ZooKeeper 和 LinkedIn 的 Project Norbert。
Apache ZooKeeper 和 Project Norbert
首先由 Yahoo Research 开发的 ZooKeeper 最初被 Apache Software Foundation 采纳为 Hadoop 的一个子项目。如今,它已是一个顶级项目,可提供分布式组协调服务。我们将使用 ZooKeeper 创建服务器集群来托管我们的模拟应用程序。ZooKeeper 也将实现应用程序所需要的服务器领袖选举功能。(领袖选举对于 ZooKeeper 提供的所有其他组协调功能是必不可少的。)
ZooKeeper 服务器通过 znode(ZooKeeper 数据节点)实现服务器协调,znode 是在内存中复制的类似于分层文件系统的数据模型。和文件一样,znode 可以保存数据,但它们也像目录一样,可以包含子级 znode。
有两种类型的 znode:常规 znode 由客户端进程显式创建和删除,而 暂时性 znode 在发起的客户端会话停止时会自动被删除。若常规或暂时性 znode 在创建时带有顺序标志,一个 10 位数字的单调递增后缀将被附加到 znode 名称。
关于 ZooKeeper 的更多信息:
- ZooKeeper 确保当服务器启动时,每台服务器都知道该组中其他服务器的侦听端口。侦听端口 支持促进领袖选举、对等通信,以及客户端与服务器的连接的服务。
- ZooKeeper 使用一个组共识算法来选举领袖,完成选举之后,其他服务器都称为跟随者。服务器集群需要服务器数量达到下限(法定数量)时才可以执行。
- 客户端进程有一组已定义的可用操作,他们使用这些操作基于 znode 编排数据模型的读取和更新。
- 所有写操作都通过领袖服务器进行路由,这限制了写操作的可扩展性。领袖使用称为 ZooKeeper Atomic Broadcast (ZAB) 的广播协议来更新跟随者服务器。ZAB 保留更新顺序。因此,在内存中的类似于文件系统的数据模型最终在组或集群中的所有服务器上保持同步。数据模型也通过持久的快照被定期写入到磁盘。
- 读操作的可扩展性比写操作高得多。跟随者从数据模型的这个同步副本响应客户端进程读取。
- znode 支持客户端的一次性回调机制,被称为 “看守者”。看守者触发一个监视客户端进程的信号,监视被看守的 znode 的更改。
利用 Project Norbert 实现组管理
LinkedIn 的 Project Norbert 挂接到一个基于 Apache ZooKeeper 的集群,以提供具有服务器集群成员感知的应用程序。Norbert 在运行时动态完成该操作。Norbert 也封装了一个 JBoss Netty 服务器,并提供了相应的客户端模块来支持应用程序交换消息。需要注意的是,早期版本的 Norbert 需要使用 Google Protocol Buffers 对象序列化消息库。目前的版本支持自定义对象的序列化。(请参阅 参考资料 了解更多信息。)
构建一个服务器集群
准备好所有组件之后,我们就可以开始配置事件处理服务器集群了。配置集群的第一步是建立服务器法定数量,之后,新当选的领袖服务器会自动启动本地文件轮询流。文件轮询通过 Spring Integration 发生,Spring Integration 模拟一个入站应用程序事件适配器。使用一个循环任务分配策略,将轮询过的文件(模拟应用程序事件)分发到可用的服务器中。
需要注意的是,ZooKeeper 将有效的法定数量定义为服务器进程的大多数。因此,一个集群至少由三个服务器组成,在至少两个服务器处于活动状态时建立法定数量。此外,在我们的模拟应用程序中,每台服务器都需要两个配置文件:一个属性文件,由引导整个服务器 JVM 的驱动程序使用,还有一个单独的属性文件供基于 ZooKeeper 的服务器集群(在该集群中,每个服务器都是一个部分)使用。
第 1 步:创建一个属性文件
Server.java(参见 参考资料)是一个控制器和条目类,用来启动我们的分布式 EAI 应用程序。应用程序的初始参数是从属性文件中读取的,如 清单 1 所示:
清单 1. 服务器属性文件
# Each server in group gets a unique id:integer in range 1-255 server.id=1 # zookeeper server configuration parameter file -relative path to this bootstrap file zookeeperConfigFile=server1.cfg #directory where input events for processing are polled for - common for all servers inputEventsDir=C:/test/in_events #directory where output / processed events are written out - may or may not be shared by #all servers outputEventsDir=C:/test/out_events #listener port for Netty server (used for intra server message exchange) messageServerPort=2195
注意,在这个最小的服务器集群中,每一台服务器都需要一个惟一的 server id(整数值)。
输入事件目录被所有服务器共享。输出事件目录模拟一个合作伙伴应用程序,并可以视情况由所有服务器共享。ZooKeeper 分发提供了一个类,用于解析服务器集群的每个成员服务器或 “法定数量对等服务器” 的配置信息。因为我们的应用程序重用了这个类,所以它需要相同格式的 ZooKeeper 配置。
还需要注意的是,messageServerPort 是 Netty 服务器(由 Norbert 库启动和管理)的侦听器端口。
第 2 步:为进程中的 ZooKeeper 服务器创建一个配置文件
清单 2. ZooKeeper 的配置文件 (server1.cfg)
tickTime=2000 dataDir=C:/test/node1/data dataLogDir=C:/test/node1/log clientPort=2181 initLimit=5 syncLimit=2 peerType=participant maxSessionTimeout=60000 server.1=127.0.0.1:2888:3888 server.2=127.0.0.1:2889:3889 server.3=127.0.0.1:2890:3890
ZooKeeper 文档(参见 参考资料)中介绍了在 清单 2 中显示的参数(以及一些可选参数,这些参数均使用默认值,覆盖的参数除外)。需要注意的是,每个 ZooKeeper 服务器使用三个侦听器端口。clientPort(在上面的配置文件中是 2181)由连接到服务器的客户端进程使用;第二个侦听器端口用于实现对等通信(对于服务器 1 的值是 2888);第三个侦听器端口支持领袖选举协议(对于服务器 1 的值是 3888)。每台服务器都支持集群的整体服务器拓扑结构,所以 server1.cfg 也列出了服务器 2 和服务器 3 及其对等端口。
第 3 步:在服务器启动时初始化 ZooKeeper 集群
控制器类 Server.java 启动一个单独的的线程 (ZooKeeperServer.java),该线程封装基于 ZooKeeper 的集群成员,如 清单 3 所示:
清单 3. ZooKeeperServer.java
package ibm.developerworks.article;
…
public class ZooKeeperServer implements Runnable
{
public ZooKeeperServer(File configFile) throws ConfigException, IOException
{
serverConfig = new QuorumPeerConfig();
…
serverConfig.parse(configFile.getCanonicalPath());
}
public void run()
{
NIOServerCnxn.Factory cnxnFactory;
try
{
// supports client connections
cnxnFactory = new NIOServerCnxn.Factory(serverConfig.getClientPortAddress(),
serverConfig.getMaxClientCnxns());
server = new QuorumPeer();
// most properties defaulted from QuorumPeerConfig; can be overridden
// by specifying in the zookeeper config file
server.setClientPortAddress(serverConfig.getClientPortAddress());
…
server.start(); //start this cluster member
// wait for server thread to die
server.join();
}
…
}
…
public boolean isLeader()
{
//used to control file poller. Only the leader process does task
// distribution
if (server != null)
{
return (server.leader != null);
}
return false;
}
第 4 步:初始化基于 Norbert 的消息传送服务器
建立了服务器法定数量后,我们可以启动基于 Norbert 的 Netty 服务器,该服务器支持快速的服务器内部消息传送。
清单 4. MessagingServer.java
public static void init(QuorumPeerConfig config) throws UnknownHostException
{
…
// [a] client (wrapper) for zookeeper server - points to local / in process
// zookeeper server
String host = "localhost" + ":" + config.getClientPortAddress().getPort();
//[a1] the zookeeper session timeout (5000 ms) affects how fast cluster topology
// changes are communicated back to the cluster state listener class
zkClusterClient = new ZooKeeperClusterClient("eai_sample_service", host, 5000);
zkClusterClient.awaitConnectionUninterruptibly();
…
// [b] nettyServerURL - is URL for local Netty server URL
nettyServerURL = String.format("%s:%d", InetAddress.getLocalHost().getHostName(),
Server.getNettyServerPort());
…
// [c]
…
zkClusterClient.addNode(nodeId, nettyServerURL);
// [d] add cluster listener to monitor state
zkClusterClient.addListener(new ClusterStateListener());
// Norbert - Netty server config
NetworkServerConfig norbertServerConfig = new NetworkServerConfig();
// [e] group coordination via zookeeper cluster client
norbertServerConfig.setClusterClient(zkClusterClient);
// [f] threads required for processing requests
norbertServerConfig.setRequestThreadMaxPoolSize(20);
networkServer = new NettyNetworkServer(norbertServerConfig);
// [g] register message handler (identifies request and response types) and the
// corresponding object serializer for the request and response
networkServer.registerHandler(new AppMessageHandler(), new CommonSerializer());
// bind the server to the unique server id
// one to one association between zookeeper server and Norbert server
networkServer.bind(Server.getServerId());
}
请注意,基于 Norbert 的消息传送服务器包括一个连接到 ZooKeeper 集群的客户端。配置此服务器,连接到本地(进程中)的 ZooKeeper 服务器,然后为 ZooKeeper 服务器创建一个客户端。会话超时将影响集群的拓扑结构更改可以多快传回应用程序。这将有效地创建一个较小的时间窗口,在该时间窗口内,集群拓扑结构的记录状态将与集群拓扑结构的实际状态不同步,这是因为新的服务器启动或现有的服务器崩溃。应用程序需要在这段时间内缓冲消息或实施消息发送失败的重试逻辑。
MessagingServer.java (清单 4) 执行以下任务:
- 为 Netty 服务器配置端点 (URL)。
- 将本地
node Id或server Id与已配置的 Netty 服务器相关联。 - 关联一个集群状态侦听器(我们将会简略介绍)实例。Norbert 将使用该实例将集群拓扑结构更改推送回应用程序。
- 将 ZooKeeper 集群客户端分配给正在进行填充的服务器配置实例。
- 为请求/响应对关联一个惟一的消息处理程序类。也需要一个序列化程序类来对请求和响应对象进行编组和解组。(您可以在 GitHub 上访问相应的类,其中包括解决方案代码,具体参见 参考资料)链接。
还要注意的是,消息传送的应用程序回调需要一个线程池。
第 5 步:初始化 Norbert 集群客户端
接下来,初始化 Norbert 集群客户端。MessagingClient.java(如 清单 5 所示)配置集群客户端,并使用一个负载均衡策略初始化该客户端:
清单 5. MessagingClient.java
public class MessagingClient
{
…
public static void init()
{
…
NetworkClientConfig config = new NetworkClientConfig();
// [a] need instance of local norbert based zookeeper cluster client
config.setClusterClient(MessagingServer.getZooKeeperClusterClient());
// [b] cluster client with round robin selection of message target
nettyClient = new NettyNetworkClient(config,
new RoundRobinLoadBalancerFactory());
…
}
...
…
// [c] – if server id <0 – used round robin strategy to choose target
// else send to identified target server
public static Future<String> sendMessage(AppRequestMsg messg, int serverId)
throws Exception
{
…
// [d] load balance message to cluster- strategy registered with client
if (serverId <= 0)
{
…
return nettyClient.sendRequest(messg, serializer);
}
else
{
// [e] message to be sent to particular server node
…
if (destNode != null)
{
…
return nettyClient.sendRequestToNode(messg, destNode, serializer);
}
…
}
}
…
}
注意,在 清单 5 中,如果没有由一个正的 server Id 值识别目标服务器,根据已配置的负载均衡策略从活动的组中选择服务器会发出消息。应用程序可以配置和实现它们自己的消息处理策略,也许以其他服务器属性为依据。(考虑多租户应用程序,其中的请求可以转发到已识别的服务器子集群,每个租户对应一个子集群;参见 参考资料 了解更多讨论。)
状态监测和任务分发
模拟的应用程序还有三个组件,我们将在下面的章节中进行介绍:
- 一个组件用于监视集群的状态(服务器成员)。
- 一个 Spring Integration 流定义文件。进程定义文件定义基于 EIP 的消息流,包括从模拟应用程序的任务池流到中心任务分发程序。任务分发程序最终将每个任务路由到其中一个可用的集群成员,以进行处理。
- 一个任务分发程序,该程序实施最终的任务路由,将任务路由到其中一个集群成员。
集群状态(拓扑结构)侦听器
集群状态侦听器 确保消息传送客户端拥有最新的可用节点列表。该侦听器也在领袖服务器上启动惟一的事件适配器实例(文件轮询程序)。文件轮询程序将轮询过的文件移交给消息处理器组件(一个 POJO),这就是实际的任务分发程序。由于集群内只有一个任务分发程序实例,所以不需要进一步的应用程序级同步。清单 6 显示了集群状态侦听器:
清单 6. ClusterStateListener.java
public class ClusterStateListener implements ClusterListener
{
…
public void handleClusterNodesChanged(Set<Node> currNodeSet)
{
…
// [a] start event adapter if this server is leader
if (Server.isLeader() && !Server.isFilePollerRunning())
{
Server.startFilePoller();
}
}
…
}
基于 Spring Integration 的文件轮询程序
Spring Integration 流执行以下任务(如 清单 7 所示):
- 创建一条称为
messageInputChannel的消息通道或管道。 - 定义一个入站通道适配器,每隔 10 秒轮询一次从 JVM 系统属性读取的目录(即 property input.dir)中的文件。被轮询和定位的任何文件都被向下传递给消息通道
messageInputChannel。 - 配置任务分发程序 Java Bean,用于从消息通道接收消息。调用其方法
processMessage来运行任务分发函数。
清单 7. 基于 Spring Integration 的流:FilePoller_spring.xml
…
<integration:channel id="messageInputChannel" />
<int-file:inbound-channel-adapter channel="messageInputChannel"
directory="file:#{ systemProperties['input.dir'] }"
filename-pattern="*.*" prevent-duplicates="true" >
<integration:poller id="poller" fixed-rate="10" />
</int-file:inbound-channel-adapter>
<integration:service-activator input-channel="messageInputChannel"
method="processMessage" ref="taskDistributor" />
<bean
id="taskDistributor"
class="ibm.developerworks.article.TaskDistributor" >
</bean>
…
任务分发程序
任务分发程序包含跨集群成员路由请求的逻辑。文件轮询程序组件仅在领袖服务器上激活,并且将轮询过的文件(在本例中为模拟的集成事件)传递到任务分发程序。任务分发程序使用 Norbert 客户端模块,将请求(即封装成消息的轮询过的文件)路由到集群中的活动服务器。任务分发程序如 清单 8 所示:
清单 8. Spring Integration 流控制的任务分发程序(一个 Java Bean)
{
…
// [a] invoked by spring integration context
public void processMessage(Message<File> polledMessg)
{
File polledFile = polledMessg.getPayload();
…
try
{
logr.info("Received file as input:" + polledFile.getCanonicalPath());
// prefix file name and a delimiter for the rest of the payload
payload = polledFile.getName() + "|~" + Files.toString(polledFile, charset);
…
// create new message
AppRequestMsg newMessg = new AppRequestMsg(payload);
// [b]load balance the request to operating servers without
// targeting any one in particular
Future<String> retAck = MessagingClient.sendMessage(newMessg, -1);
// block for acknowledgement - could have processed acknowledgement
// asynchronously by repositing to a separate queue
String ack = retAck.get();
…
logr.info("sent message and received acknowledgement:" + ack);
…
}
}
请注意,服务激活器 方法的调用是通过在文件轮询程序找到一个文件进行处理之后控制 Spring Integration 上下文来完成。另外请注意,文件的内容是序列化的,并形成一个新请求对象的有效负载。消息传送客户端的 sendMessage() 方法被调用,但没有针对某一特定的目标服务器。然后,Norbert 客户端模块将结果消息负载均衡到集群的其中一台运行的服务器。
运行模拟的应用程序
一个 “可运行” 的 JAR 文件 (ZooKeeper-Norbert-simulated-app.jar) 与三个服务器集群的样例配置文件都包含在本文的源代码中(参见 参考资料)。
若要测试应用程序,您可以在本地的单台计算机上启动所有三个服务器,或在整个网络中分发它们。为了在多台计算机上运行应用程序,需要一个可从网络安装/访问的公共输入事件文件夹。通过创建相应的配置文件,每增加一台服务器就创建两个配置文件,并更新现有的配置文件之后,您就可以在集群中增加服务器的数量。
触发器事件处理,将包含文本内容的文件复制到指定的输入文件夹。连续文件由不同的服务器进行处理。通过停止其中一台服务器可测试服务的可靠性。(请注意,由三个服务器组成的集群的法定数量规定,在任何时候都只能有一台服务器停机,以保持应用程序正常运行)。默认情况下,所包含的 log4j.properties 文件启用 TRACE 级的日志记录;请注意,服务器拓扑结构将随正在运行的服务器更新。如果您让领袖服务器停机,那么将选出新的领袖,并在那台服务器上激活文件轮询流,从而保证进行连续的处理。
请参阅 参考资料 部分,了解有关使用 Apache ZooKeeper 和 Project Norbert 进行服务器集群感知的应用程序开发的更多信息。
源于:http://www.ibm.com/developerworks/cn/java/j-zookeeper/index.html
<!--CMA ID: 856165--><!--Site ID: 10--><!--XSLT stylesheet used to transform this file: dw-document-html-7.0.xsl-->