两种解析方式:
DOM(Document Object Model 文档对象模型)
关键字:树(Document)
优点: 把 xml 文件在内存中构造树形结构,可以遍历和修改节点
缺点: 如果文件比较大,内存有压力,解析的时间会比较长
SAX(Simple API for Xml 基于 XML 的简单 API)
关键字:流(Stream)
把 xml 文件作为输入流,触发标记开始,内容开始,标记结束等动作
优点: 解析可以立即开始,速度快,没有内存压力
缺点: 丌能对节点做修改
3) JDOM / DOM4J :目前市场上常用的 2 种解析 XML 文件的 API
dom4j-1.6.1.jar 结合了 DOM 和 SAX 两种解析方式的优点
准备:导入dom4j-1.6.1.jar 包
读取XML文件(按照文件的格式读取内容):--------------------------------------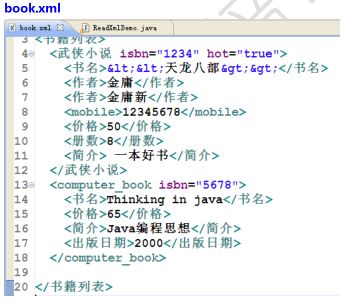
public Static void readBook(String filename){
SAXReader reader =new SAXReader(); //解析器
File file=new File(filename); //指定xml文件
try{
Document doc =reader.read(file); //开始解析,建立树形结构并返回
Element rootElmt=doc.getRootElement(); //获得根元素:书籍列表
List list= rootElmt.elements("武侠小说"); //获得所有武侠小说的元素集合
parseNovel(list);
List list2= rootElmt.elements("computer_book"); //获得所有computer_book的元素集合
parseNovel(list2);
}catch(DocumentException e){
e.printStackTrace();
}
}
public Static void parseNovel(List list){
Iterator it =list.iterator();
while(it.hasNext()){
Element novelElmt =(Element)it.next(); ----取出元素
String bookname=novelElmt.elementText("书名"); ---读取元素的内容
String editor=novelElmt.elementText("作者");
String price=novelElmt.elementText("价格");
...
//取出元素的所有属性
List attrList= novelElmt.attributes();==Iterator attrList =novelElmt.attributeIterator();
Iterator attrIt =attrList.iterator();
while(attrIt.hasNext()){
Attribute attr = (Attribute)attrIt.next();
System.out.println(attr.getName() + "=" + attr.getValue());
}
}
}
写XML文件:-------------------------------------------------------------
常用 API 方法:
1) 给元素增加子元素: elmt.addElement( "标记名称" ) ;
2) 给元素增加属性: elmt.addAttribute( "属性名" , "属性值" ) ;
3) 给叶子元素设值: elmt.setText( "元素值" ) ;
/***************************内存中构建document文档对象***********************************/
创建一个如图的xml文件:
filename.xml:本例文件是已手动建好的空文件(可在程序中生成指定路径的空文件)
public static void builXml(String filename){
//数据源(也可是数据库查询的一个集合对象)
String[][] books ={
{"1001","武侠","天龙八部","金庸","60","1965","zh"},
{"1002","科幻","哈利波特","rowLing","86","1969","en"},
....
}
//创建一个空的文档对象
Document doc =DocumentHelper.createDocument();
//创建根元素
Element rootElmt=doc.addElement("booklist");
//增加每本书(每条数据)的元素
for(String[] book : books){
Element bookElmt = rootElmt.addElement("book");
//增加每本书的子元素(每条数据的子元素)
Element titleElmt = bookElmt.addElement("title");
Element authorElmt = bookElmt.addElement("author");
Element priceElmt = bookElmt.addElement("price");
Element yearElmt = bookElmt.addElement("year");
//给子元素添加数据
titleElmt.setText(book[2]);
authorElmt.setText(book[3]);
priceElmt .setText(book[4]);
yearElmt .setText(book[5]);
//给book元素增加两个属性:isbn="1001" calalog="武侠"
bookElmt.addAttribute("isbn",book[0]);
bookElmt.addAttribute("calalog",book[1]);
//给title元素增加一个属性:lang="zh"
titleElmt.addAttribute("lang",book[6]);
}
outputXml(doc,filename);
}
/*********************输出document文档对象到指定位置的xml文件****************************************/
private static void outputXml(Document coc ,String filename){
try{
//创建一个java.io包中的FileWriter对象,指定要生成的目标文件
FileWriter fw = new FileWriter(filename);
//指定xml文件的输出格式
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");
//写xml文件到操作系统
XMLWriter xmlWriter = new XMLWriter(fw , format);
xmlWriter.write(doc);
xmlWriter.close();
}catch(IOException e){
e.printStackTrace();
}
}
XML文件中搜索某个节点的值(按照文件的格式读取内容):--------------
1) XPath:在 XML 文件中查找或定位信息的语言:XPath 可以通过元素/属性/值来定位或导航
2) 节点(Node): 相当于 XML 文件中的元素
3) 指定条件定位元素的方式
一:读取xml文件的所有元素
public Static void readBook(String filename){
SAXReader reader =new SAXReader(); //解析器
File file=new File(filename); //指定xml文件
try{
Document doc =reader.read(file); //开始解析,建立树形结构并返回
//Element rootElmt=doc.getRootElement(); //获得根元素:书籍列表
//List list= rootElmt.elements("武侠小说"); //获得所有武侠小说的元素集合
Node root = doc.selectSingleNode("/booklist");//取根节点(根元素),绝对路径:/booklist,相对路径:book
//查所有元素
List<Element> list = root.selectNodes("book");
for(Element e : list){
String title =e.elementText("title")---e元素的子元素title元素的内容
String zh =e.element("title").attributeValue("lang");---e元素的子元素title元素的属性
String isbn=e.attributeValue("isbn");---e元素的属性
}
//查询指定的元素
//查找所有中文书:lang=zh是title的属性(list中存放的都是title元素,book/title:相对路径,[@lang='zh']:过滤条件)
List<Element> list = root.selectNodes("book/title[@lang='zh'] ");
//查询所有武侠类书:book元素属性:catalog="武侠",list里的元素是book元素
List<Element> list = root.selectNodes("book[@catalog='武侠'] ");
//查询价格大于80的书:price是book的子元素,list里的每个元素是book元素
List<Element> list = root.selectNodes("book[price > 80] ");
//查询作者是金庸的书或古龙的书
List<Element> list = root.selectNodes("book[author='金庸' or author='古龙'] ");
//查询英文价格大于80的书
List<Element> list = root.selectNodes("book[price > 80 and title[@lang='en']] ");
for(Element e : list){
e.getStringValue();
}
}catch(DocumentException e){
e.printStackTrace();
}
}