hadoop如何恢复namenode
Namenode恢复
1.修改 conf/core-site.xml,增加
fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。
fs.checkpoint.size表示一次记录多大的size,默认64M
2.修改 conf/hdfs-site.xml,增加
0.0.0.0改为namenode的IP地址
3.重启hadoop,然后检查是否启动是否成功。
登录secondarynamenode所在的机器,输入jps查看secondarynamenode进程
进入secondarynamenode的目录/data/work/hdfs/namesecondary
正确的结果:
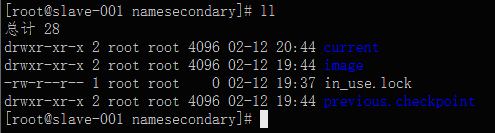
如果没有,请耐心等待,只有到了设置的checkpoint的时间或者大小,才会生成。
4.恢复
制造namenode宕机的情况
1) kill 掉namenode的进程
2)删除dfs.name.dir所指向的文件夹,这里是/data/work/hdfs/name
删除name目录下的所有内容,但是必须保证name这个目录是存在的
3)从secondarynamenode远程拷贝namesecondary文件到namenode的namesecondary
4)启动namenode
正常启动以后,屏幕上会显示很多log,这个时候namenode就可以正常访问了
5)检查
使用hadoop fsck /user命令检查文件Block的完整性
6)停止namenode,使用crrl+C或者会话结束
7)删除namesecondary目录下的文件(保存干净)
8)正式启动namenode
恢复工作完成,检查hdfs的数据
balancer
在使用start-balancer.sh时,
默认使用1M/S(1048576)的速度移动数据(so slowly...)
修改hdfs-site.xml配置,这里我们使用的是20m/S
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>20971520</value>
<description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description>
</property>
然后结果是导致job运行变得不稳定,出现一些意外的长map单元,某些reduce时间处理变长(整个集群负载满满的情况下,外加20m/s的balance),据说淘宝的为10m/s,需要调整后实验,看看情况如何。
安全模式
有两个方法离开这种安全模式:
(1)修改dfs.safemode.threshold.pct为一个比较小的值,缺省是0.999。
dfs.safemode.threshold.pct(缺省值0.999f)
HDFS启动的时候,如果DataNode上报的block个数达到了元数据记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。
(2)hadoop dfsadmin -safemode leave命令强制离开
dfsadmin -safemode value 参数value的说明:
enter - 进入安全模式
leave - 强制NameNode离开安全模式
get - 返回安全模式是否开启的信息
wait - 等待,一直到安全模式结束。
1.修改 conf/core-site.xml,增加
Xml代码


- <property>
- <name>fs.checkpoint.period</name>
- <value>3600</value>
- <description>The number of seconds between two periodic checkpoints. </description>
- </property>
- <property>
- <name>fs.checkpoint.size</name>
- <value>67108864</value>
- <description>The size of the current edit log (in bytes) that triggers a periodic checkpoint even if the fs.checkpoint.period hasn't expired. </description>
- </property>
- <property>
- <name>fs.checkpoint.dir</name>
- <value>/data/work/hdfs/namesecondary</value>
- <description>Determines where on the local filesystem the DFS secondary name node should store the temporary images to merge. If this is a comma-delimited list of directories then the image is replicated in all of the directories for redundancy. </description>
- </property>
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints. </description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers a periodic checkpoint even if the fs.checkpoint.period hasn't expired. </description>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/data/work/hdfs/namesecondary</value>
<description>Determines where on the local filesystem the DFS secondary name node should store the temporary images to merge. If this is a comma-delimited list of directories then the image is replicated in all of the directories for redundancy. </description>
</property>
fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。
fs.checkpoint.size表示一次记录多大的size,默认64M
2.修改 conf/hdfs-site.xml,增加
Xml代码
- <property>
- <name>dfs.http.address</name>
- <value>master:50070</value>
- <description> The address and the base port where the dfs namenode web ui will listen on. If the port is 0 then the server will start on a free port. </description>
- </property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
<description> The address and the base port where the dfs namenode web ui will listen on. If the port is 0 then the server will start on a free port. </description>
</property>
0.0.0.0改为namenode的IP地址
3.重启hadoop,然后检查是否启动是否成功。
登录secondarynamenode所在的机器,输入jps查看secondarynamenode进程
进入secondarynamenode的目录/data/work/hdfs/namesecondary
正确的结果:
如果没有,请耐心等待,只有到了设置的checkpoint的时间或者大小,才会生成。
4.恢复
制造namenode宕机的情况
1) kill 掉namenode的进程
Java代码
- [root@master name]# jps
- 11749 NameNode
- 12339 Jps
- 11905 JobTracker
- [root@master name]# kill 11749
[root@master name]# jps 11749 NameNode 12339 Jps 11905 JobTracker [root@master name]# kill 11749
2)删除dfs.name.dir所指向的文件夹,这里是/data/work/hdfs/name
Java代码
- [root@master name]# rm -rf *
[root@master name]# rm -rf *
删除name目录下的所有内容,但是必须保证name这个目录是存在的
3)从secondarynamenode远程拷贝namesecondary文件到namenode的namesecondary
Java代码
- [root@master hdfs]# scp -r slave-001:/data/work/hdfs/namesecondary/ ./
[root@master hdfs]# scp -r slave-001:/data/work/hdfs/namesecondary/ ./
4)启动namenode
Java代码
- [root@master /data]# hadoop namenode –importCheckpoint
[root@master /data]# hadoop namenode –importCheckpoint
正常启动以后,屏幕上会显示很多log,这个时候namenode就可以正常访问了
5)检查
使用hadoop fsck /user命令检查文件Block的完整性
6)停止namenode,使用crrl+C或者会话结束
7)删除namesecondary目录下的文件(保存干净)
Java代码
- [root@master namesecondary]# rm -rf *
[root@master namesecondary]# rm -rf *
8)正式启动namenode
Java代码
- [root@master bin]# ./hadoop-daemon.sh start namenode
[root@master bin]# ./hadoop-daemon.sh start namenode
恢复工作完成,检查hdfs的数据
balancer
在使用start-balancer.sh时,
默认使用1M/S(1048576)的速度移动数据(so slowly...)
修改hdfs-site.xml配置,这里我们使用的是20m/S
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>20971520</value>
<description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description>
</property>
然后结果是导致job运行变得不稳定,出现一些意外的长map单元,某些reduce时间处理变长(整个集群负载满满的情况下,外加20m/s的balance),据说淘宝的为10m/s,需要调整后实验,看看情况如何。
Java代码
- hadoop balancer -threshold 5
hadoop balancer -threshold 5
安全模式
有两个方法离开这种安全模式:
(1)修改dfs.safemode.threshold.pct为一个比较小的值,缺省是0.999。
dfs.safemode.threshold.pct(缺省值0.999f)
HDFS启动的时候,如果DataNode上报的block个数达到了元数据记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。
(2)hadoop dfsadmin -safemode leave命令强制离开
dfsadmin -safemode value 参数value的说明:
enter - 进入安全模式
leave - 强制NameNode离开安全模式
get - 返回安全模式是否开启的信息
wait - 等待,一直到安全模式结束。
-

- 大小: 8.1 KB