克服长尾挑战 (Overcoming the Long Tail Challenge)
意义:数据挖掘中的用户行为数据也遵循着幂律分布
1. 幂律分布无处不在
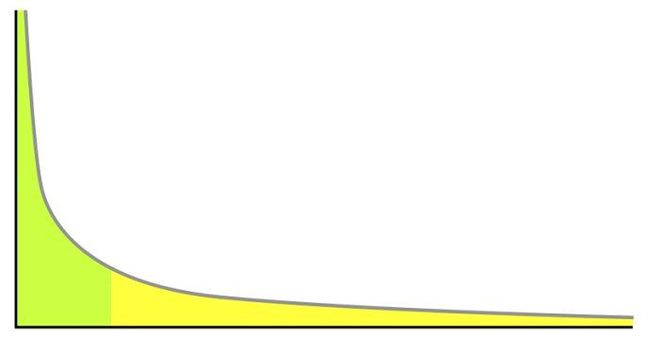
自然和社会中,许多事物的特征,其发生频率遵循幂律分布(power law distribution)。幂律分布的密度函数是如图所示的幂函数。幂律分布的特点是,20%的高频特征的频率大约占整体的80%,称为头部(head,图中浅绿色部分);另一方面,低频特征的频率逐渐减小,形成一个长长的尾部(tail,图中黄色部分)。Zipf在语言学中,Pareto在经济学中,最早研究了幂律分布,也被简化为80/20规则。
幂律分布无处不在,有很多例子。若用80/20规则来描述,则成为以下现象。语言中,20%的常用词汇占据80%的文章篇幅;社会中,20%的富裕阶层拥有80%的财富;商业中,20%的优质客户带来80%的营业收入;蚁群中,20%的“勤奋”蚂蚁承担80%的工作;公司中,20%的核心员工创造80%的产值。注意这里20%-80%只是个近似,在具体实例中其比例会有不同。
2. 头部的成功
近十年来,随着计算机处理能力的提高,海量数据得以收集、存储、处理,大规模数据挖掘、大规模机器学习被广泛应用的各个领域,给产业界带来巨大变化。其中,用户行为数据(user behavior data)是一种具有代表性的数据,被成功地利用到不同的产品、服务中。用户行为数据也遵循幂律分布,其成功主要在于头部数据利用的成功,如以下微软Office产品与互联网搜索的例子所示。
2-1.微软Office产品
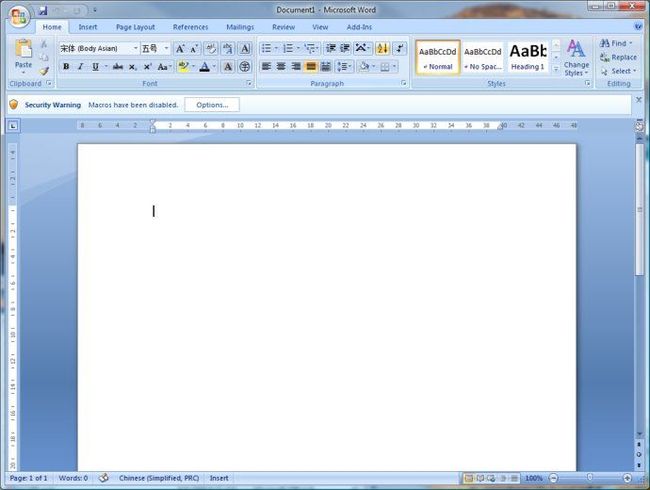
微软从Office 2007起对Office产品的用户界面做了全面的更新;之前的菜单形式的工具栏被Ribbon形式的工具栏所替代。Ribbon中,功能按照用户使用特点被分类。大家有没有产生过这样的疑问。为什么粘贴(paste)被放在了Ribbon的最左边?如上图所示。其实这一设计是基于大规模用户行为数据挖掘的 [1]。
Office产品在其发展过程中,遇到了很大的挑战。一方面,用户希望添加各种新功能;随着版本升级,新功能不断增加,如上图所示。另一方面,用户又发现菜单变得越来越复杂,在系统中经常难于找到要找的功能。

从Office2003开始,微软公司在争得许可的条件下,记录并收集了部分用户使用Office的行为数据。这些用户使用Office时的操作,如菜单选项的点击,都会被记录下来,并送到Office的数据中心。微软进行了基于大规模数据挖掘的用户界面设计,在Office 2007中推出了全新的Ribbon界面。数据挖掘结果发现,全球用户中,最常用的命令是:paste, save, copy, undo, bold。这就是paste被放在最醒目的界面左上角的原因。
Ribbon界面得到了广大用户的支持,取得了很大成功,至少是部分解决了上述难题。用户行为数据挖掘也为工业设计开辟了一条新路。产品功能的使用频率也是符合幂律分布的;可以说,Ribbon界面仅仅有效地利用了头部数据,并未触及尾部数据的使用。
2-2. 互联网搜索
互联网搜索在近十几年里经历了两次大的技术革新。第一次以锚文本(anchor text)的使用和PageRank算法为代表,第二次以日志数据挖掘(log data mining)为代表。而日志数据就是搜索引擎记录的用户搜索行为数据。两次技术革新都使搜索引擎的相关排序(relevance ranking)结果有了很大的提高。下面介绍第二次技术革新的两个例子:点击数据(click through data)的使用与BrowseRank算法。
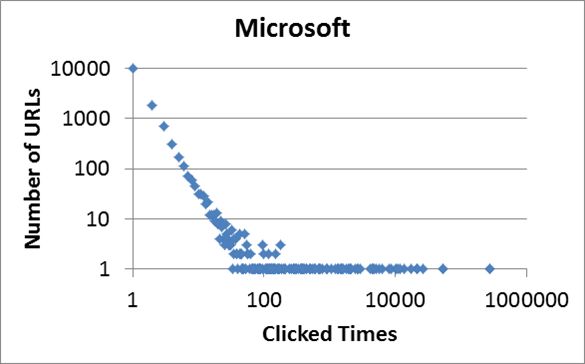
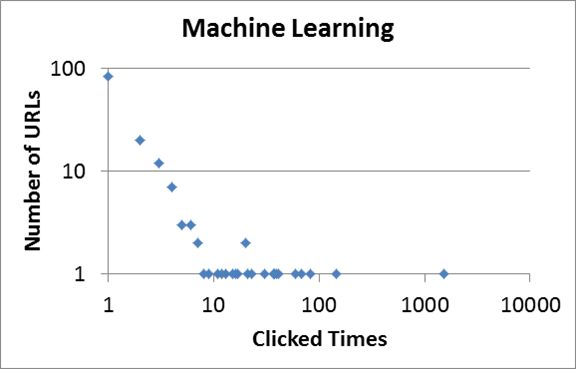
用户搜索的每次查询,包括查询语句、点击网页的URL等都会被搜索引擎记录下来。将一段时间内的所有查询汇总,就会得到点击数据。点击数据表示,对每个查询语句,用户在搜索结果中点击URL的次数。以上两图显示在Bing的日志数据中得到的关于查询“microsoft”与“machine learning”的点击数据。对查询“microsoft”,microsoft.com的点击次数最多,有27万以上;相反,有1万个URL其点击次数仅为1。对查询“machine learning”,点击最多的URL其点击次数有1千多;相反,有近1百个URL其点击次数仅为1。可以看出,点击数据是符合幂律分布的。
头部查询(高频查询),往往有丰富的点击数据,成为搜索引擎的宝贵资源。它告诉搜索引擎,针对每个查询,用户最想要什么结果,结果的排序是什么。事实上,现在的搜索引擎都在不同程度上使用点击数据,特别是头部点击数据。但是,大部分查询属于尾部查询(低频查询),其点击数据极其稀少,比如只有一两次,可信度较低。所以尾部数据不能简单地直接使用。如何有效地利用尾部点击数据成为互联网搜索的一个重要课题。
BrowseRank是我们开发的一个网页重要度的算法[2]。网页重要度是网页相关度排序的一个重要特征,搜索引擎一般将相关度与重要度都高的网页排在前面。
传统的网页重要度算法是PageRank。直观上,有许多链接指向的网页重要,网页的重要度通过链接可以在网上传播;PageRank用马尔可夫模型实现这一直观。具体地,PageRank将互联网当作一个有向图,在有向图上定义马尔可夫过程,通过马尔可夫过程中的随机游动(random walk)实现网页重要度的传播。最后,PageRank用马尔可夫过程的平稳分布表示网页的重要度。
可以认为BrowseRank是PageRank的扩展。BrowseRank首先根据用户行为数据构建用户浏览图。图上的结点表示网页,边表示用户在网页间的转移。结点上记录了用户在网页上的平均停留时间,边上记录了用户在网页间转移的次数。BrowseRank然后再在用户浏览图上定义连续时间马尔可夫过程,用其平稳分布表示网页的重要度。直观上,用户在网页上平均停留时间越长,网页就越重要;被指向的边越多,且边上的转移次数越高,网页就越重要。PageRank基于离散时间马尔可夫过程,所以是BrowseRank的特殊情况。
BrowseRank通过用户行为数据计算网页重要度,与PageRank成互补关系,是一个有效的算法。它对头部网页(热门网页)的重要度计算可以很准确,而对尾部网页(冷门网页)的重要度计算却常常是鞭长莫及的。在这一点上PageRank也是一样的。
3. 长尾挑战

互联网搜索主要还是基于关键字匹配。尾部查询(低频查询)是不容易做好的,因为没有足够多的信号(signal),包括锚文本与点击数据。这时,查询语句与网页不能有很好的匹配,搜索引擎常常无法做出正确的相关度判断。比如,查询语句是“zhongguanchun swimming pool schedule”,网页只含有“zhongguanchun pool schedule”。由于swimming一词没有出现在网页中,如果这个网页没有锚文本与点击数据,就不容易准确地判断它们之间的相关度;很有可能这个网页不会被找到,或排在前面。
Goel等对用户搜索,以及其他信息访问的需求做了研究[3]。他们发现,用户需求的分布呈幂律分布,每个用户都有头部的需求与尾部的需求。有些用户头部的需求多一些,有些用户尾部的需求多一些。所以,互联网搜索中仅把容易做的头部查询做好是不足以满足绝大多数用户需求的。
互联网搜索中,提供高质量的尾部查询服务能够极大提高用户的满意度。互联网搜索引擎,不但应做好头部查询,而且应做好尾部查询,使用户无论找什么东西都能很快、很全、很准地找到。做好尾部查询是互联网搜索不可回避的,需要不断努力的目标。长尾挑战不仅在互联网搜索中,在其他产品、服务中也都存在。
4. 可能的解决途径
4-1.康德哲学的启示
怎样让计算机克服长尾挑战呢?我们可以看一看人是如何拥有知识,如何做智能性活动的。
现在我们普遍认为人的知识是由先天的能力与后天的实践相结合产生的。有大量的证据可以证明这一点。但是人类达到这一认识是从十八世纪康德开始的。在他之前有理性主义与经验主义之争。前者的代表有笛卡儿、斯宾诺莎、莱布尼兹,后者的代表有培根、洛克、休谟。理性主义认为理性是人的知识的基础,是普遍的、生来就有的。笛卡尔说:“在这个世界上,良知是被分配得最为公平的东西”(Good sense is of all things in the world the most equally distributed)。相反,经验主义认为人的知识是通过实践得来的。理性主义很难解释为什么人可以通过实践获得新知识,经验主义很难解释为什么人的知识会有普遍性。康德站在理性主义的立场上,提出了将理性主义与经验主义结合的想法,即,知识是基于先天的能力通过后天的实践得到的。只有这样看待这个问题,才能将理性主义与经验主义的矛盾同时解决。
人在学习中并不会感受到长尾现象的困扰。从康德的观点来看,这是因为人有一定的先验知识。所以,要让计算机战胜长尾挑战就需要将更多的先验知识赋予计算机。这或许是解决长尾问题的唯一途经。
4-2.互联网搜索中的尝试
近年来,我和同事们一起从事互联网相关排序的研究,重点是提高尾部查询的相关排序结果。我们开发了一系列新算法,其核心想法是,假设头部与尾部遵循同样的规律,或拥有同样的知识,从头部数据学习知识,并将这些知识推广到尾部数据。下面介绍一个例子。
据统计,有10%-15%的英文查询语句含有拼写错误。查询语句中的拼写错误自动纠正是互联网搜索的一个重要研究课题。我们提出了一个新的机器学习算法,能够很好地解决这个问题[4]。这个方法首先从搜索日志数据中自动找出用户输入的拼写错误及其纠正。用户经常会输入含有拼写错误的查询语句,但有时会马上对其纠正。从日志数据中可以发现大量的此类数据;当然它们都是头部数据。我们的方法从这些数据中自动找出大量的拼写转换规则,比如,ni到mi,shi到si,并自动学习转换规则的权值,构建一个拼错纠正模型。比如,转换规则ni到mi可以用于从ninecraft到minecraft的拼写错误纠正。这些规则虽然是从头部学到的,但它们具有普遍性,在尾部也适用。这样,就可以将从头部学到的知识推广到尾部。
5.总结
长尾问题是机器学习、数据挖掘需要解决的重大问题之一。可能的解决途径是将先验知识与机器学习相结合;目前已有一些尝试,取得了一些进展。但是,如何将更多的先验知识加入计算机中,如何在计算机中表示先验知识,如何将先验知识有机地融合到机器学习,在我们面前,还有许多待解的难题。
参考:
[1] Jensen Harris: An Office User Interface Blog,http://blogs.msdn.com/b/jensenh/archive/tags/why+the+new+ui_3f00_/default.aspx
[2] Yuting Liu, Bin Gao, Tie-Yan Liu, Ying Zhang, Zhiming Ma, Shuyuan He, Hang Li. BrowseRank: Letting Users Vote for Page Importance, In Proceedings of the 31st Annual International ACM SIGIR Conference (SIGIR’08), pages 451-458, 2008. (SIGIR’08 Best Student Paper Award).
[3] Sharad Goel, Andrei Z. Broder, Evgeniy Gabrilovich, Bo Pang: Anatomy of the long tail: ordinary people with extraordinary tastes. WSDM 2010: 201-210.
[4] Ziqi Wang, Gu Xu, Hang Li and Ming Zhang, A Fast and Accurate Method for Approximate String Search, In Proceedings of the 49th Annual Meeting of Association for Computational Linguistics: Human Language Technologies (ACL-HLT’11), 52-61, 2011.