简介
在当今这个互联网和经济全球化时代,需要使用越来越多的应用程序处理不同国家语言表示的数据。对开发人员而言,这就意味着在应用程序开发的各个阶段 — 数据库设计、应用程序设计和应用程序编程 — 都要考虑到不同国家的语言需求。DB2 9 支持具有不同属性的各种语言,比如重音符号(法语)、双向(阿拉伯语)和大字符集(中文)。这些语言在存储、处理、访问和表示数据方面提出了各自不同的挑战。受国家语言影响的数据不仅限于字符串数据。还包括有数值型、日期型和货币型数据。
字符与字符串数据的字节语义之间的对比
DB2 9 以前版本中的一些字符串函数从字节和双字节单元的混合角度处理字符和图形数据。正如之前解释的那样,越来越多的用户根据不同国家语言的字符来考虑数据。DB2 9 的新功能解决了字符组成及其长度计算方面的问题,本文将讨论这些新功能。
对于单字节字符编码模式,一个字节组成一个字符,单字节字符串的长度与字符串的字节长度相同。对于图形字符串,两个字节组成一个字符,使用双字节数来表示字符串的长度。但是对于多字节编码,字符的字节长度随使用编码模式的不同而不同,每个字符的长度可能是一个字节或多个字节。本文中将使用字节计算字符串长度的方法称作字节语义,而使用字符数计算字符串长度的方法称作字符语义。
考虑以下的中文字符串:
图 1. 中文字符串
如果使用字符语义计算字符串的长度,则该字符串的长度为 2。但是如果使用字节语义并使用 UTF-8 对字符进行编码,则该字符串的长度为 6 字节。
对基于字符的函数的需求
SQL 中基于字符的数据在很多上下文中都与数值有关,如下所述:
字符串变量的长度:SUBSTR 函数的输入参数,决定了结果字符串的期望长度或 LENGTH 函数的输出。
字符串中的偏移量:LOCATE 函数的第二个参数,指定了字符串中开始搜索的起始位置。
这些数值表示单字节数据的字节数和图形或双字节数据的双字节数。但是对于多字节字符编码(如 UTF-8),这些数值并不符合字符语义。下面的条件可以帮助我们理解为何需要基于字符的函数。
字符的组成
将字符看作一个单元而不是一个字节序列,这是进行多字节字符的字符串操作的必要条件。应用程序开发人员需要知道,分配缓冲区时应该给每个字符分配多大内存。因此,理解字符组成对编写应用程序处理多字节字符数据非常重要。 可以将字符定义为一个信息单元,对应于书面语言的一个原子单元。每个字符由一个使用字符编码的位序列表示。单个字符通常使用一个字节或多个字节进行编码,具体情况取决于使用的编码方式。 考虑字符 “A” 和 “上面带圈的大写拉丁字母 A”。字符 “A” 的十六进制表示是 x‘41’ 而 “上面带圈的大写拉丁字母 A” 的十六进制表示是 x‘C385’。通过 SQL 函数 hex() 可以获取此表示。
图 2. 字符的十六进制表示
从上面的表示可以看到,显示期间只存在一个字符。但是,“A” 的长度是一个字节而 “上面带圈的大写拉丁字母 A” 的长度则是两个字节。
根据代码单元计算的字符串长度
字符字符串的长度取决于用于编码字符的字符编码方式(ASCII、EBCDIC 和 Unicode)。可以使用一个或多个各自编码的代码单元来表示字符。因此,如果字符串中有相同的字符集,则其长度可能随使用编码方式的不同而有所不同。 考虑一个字符例子 “音符 G 音谱号”。考虑表 1 中对此字符的不同编码,您会发现不同代码单元中的不同编码的十六进制表示及其长度都有所不同。
表 1. 相同字符不同编码的十六进制表示
| 编码 | UTF-8 | UTF-16(Big-Endian) | UTF-32(Big-Endian) |
| 十六进制格式 | X'F09D849E' | X'D834DD1E' | X'0001D11E' |
| 各自代码单元的长度 | 4 | 2 | 1 |
从图 3 可以看出如何获取 “音符 G 音谱号” 字符按 UTF-8 编码时的字节长度。
图 3. “音符 G 音谱号” 的字节长度
搜索字符
在字符串中搜索特定的子字符串时,首先执行搜索,然后返回的结果(字符串中的位置)为字节位置数,而不是正确的字符或代码单元的位置。图 4 展示了对 “a” 的搜索,“a” 的实际字符位置是 2,而输出的位置是 3,原因在于字符串中有多字节字符。
图 4. 字符串中的搜索结果
字符分解
将多字节字符数据看作字节序列可能导致字符串函数执行意外的字符分解。在图 5 中,已经指定字符串第一个字节的长度为 1 的子字符串。由于第一个字符是多字节的,因此会导致字符分解和错误输出。
图 5. SUBSTR 函数分解字符
指定起始位置
可能需要为 LOCATE 之类的函数提供输入以指定搜索的起始位置。对于多字节数据可能会存在一些问题,可能得不到预期的结果。在图 6 中,搜索第三个字节后的字符,如果所有的字符都是单字节字符的话应该搜索到第二次出现的 “a” 字符。但是由于第一个字符是多字节字符,因此得到结果 3,它是搜索字符串的第一次出现的位置。
图 6. 使用 LOCATE 指定起始位置
基于字符的函数
除了 DB2 早期版本中使用字节语义处理字符数据的字符串函数之外,DB2 9 还引入了一组理解字符语义的基于字符的字符串函数。如果采用特殊编码的某个字符的长度跨越了多个字节,则基于字符的字符串函数可以将每个字符处理为一个单元而不是一个字节序列。
引入字符串长度单元
DB2 的基于字符的字符串函数引入了字符串长度单元的概念来理解字符编码,根据该概念,考虑使用输入字符串来进行字符串操作。DB2 9 for Linux, UNIX, and Windows 的字符串单元分别为 OCTETS、CODEUNITS16 和 CODEUNITS32。
字符串函数拥有数值规范,或者说结果是输入数据相关的数值。字符串长度单元属于数值。待执行的字符串操作可能导致不同的输出,取决于计算字符所使用的字符串长度单元。一些函数的输入是数值,比如字符串函数的起始、长度和偏移量参数。而其他一些函数的返回结果是数值,比如搜索字符串中指定的子字符串的出现位置,首先执行搜索然后结果返回为字符串长度单元中隐式或显式指定的数字。
使用 OCTETS 作为字符串长度单元时,通过简单地计算字符串的字节数即可确定字符串的长度。CODEUNITS16 指定将 Unicode UTF-16 用于字符语义。同样,CODEUNITS32 指定使用 Unicode UTF-32 来理解多字节字符的字符边界。
使用 CODEUNITS16 或 CODEUNITS32 计算代码单元得到的结果是相同的,除非使用了增补字符和代理对。使用增补字符时,对于一个增补字符,使用 CODEUNITS16 计算是两个 UTF-16 代码单元,而使用 CODEUNITS32 计算则是一个 UTF-32 代码单元。
如果使用 CODEUNITS 来获取字符的长度,则用作字符串函数输入的 CODEUNITS 的不同会导致输出的不同。
清单 1. 使用不同的 CODEUNITS 所得到的字符串长度
VALUES CHARACTER_LENGTH(X'F09D849E', OCTETS)
1
-----------
4
1 record(s) selected.
VALUES CHARACTER_LENGTH(X'F09D849E', CODEUNITS16)
1
-----------
2
1 record(s) selected.
VALUES CHARACTER_LENGTH(X'F09D849E', CODEUNITS32)
1
-----------
1
1 record(s) selected.
DB2 9 中基于字符的字符串函数
CHARACTER_LENGTH
如 SQL 标准中所述,此函数使用字符语义查找字符字符串的长度。此函数与 DB2 中的 LENGTH 函数类似,并拥有一个可选的字符串长度单元,可以用来表示结果。与 LENGTH 函数不同,CHARACTER_LENGTH 只接受基于字符串的输入数据。该函数包含两个参数,第一个参数是字符串,而第二个参数是代码单元。在很多情形下,您需要根据代码单元计算的字符串长度,可以使用基于字符的函数来获取根据字符串单元计算的字符串长度。
考虑之前讨论的 “音符 G 音谱号” 字符例子。
清单 2. 使用 CHARACTER_LENGTH 获取基于 CODEUNITS 的字符串长度
VALUES CHAR_LENGTH(X'F09D849E',CODEUNITS16)
1
-----------
2
1 record(s) selected.
VALUES CHAR_LENGTH(X'F09D849E',CODEUNITS32)
1
-----------
1
1 record(s) selected.
使用基于字符的字符串函数可以解决获取基于 CODEUNITS 的字符串长度时的问题。
OCTET_LENGTH
如 SQL 标准中所述,此函数返回输入字符串的八位字节长度或字节长度。它与对单字节数据类型使用 LENGTH 函数类似。如果使用双字节数据类型作为输入,它就会给出双倍的 LENGTH 函数值。使用 CHARACTER_LENGTH 并使用 OCTETS 作为字符串长度单元时也会产生同样的功能。
清单 3. 使用 OCTECT_LENGTH 获取字符串的字节长度
VALUES OCTET_LENGTH(X'F09D849E')
1
-----------
4
1 record(s) selected.
LOCATE
LOCATE 函数返回一个字符串在另一个字符串中第一次出现的起始位置。如果没有找到搜索字符串,并且参数都不为空,则所得的结果是零。如果找到搜索字符串,则所得结果是一个从 1 到源字符串实际长度之间的一个数字。如果指定了可选的起始位置,则表明它是源字符串中开始进行搜索的字符位置。可以指定一个可选的字符串长度单元来指明在哪些单元中表示函数的起始位置和结果。
可以使用基于字符的函数来解决在 LOCATE 函数中指定起始位置的问题,如图 7 所示:
图 7. 通过 CODEUNITS 使用 LOCATE
POSITION
POSITION 函数返回一个字符串在另一个字符串中第一次出现的起始位置。如果没有找到搜索字符串,并且参数都不为空,则所得的结果是 0。如果找到搜索字符串,则所得结果是一个从 1 到输入字符串实际长度之间的一个数字,使用显式指定的代码单元来表示。POSITION 函数是在 SQL 标准中进行定义的。它与 DB2 家族之间实现的 POSSTR 函数相似但不相同。
使用基于字符的函数可以解决将字节位置返回为字符位置的问题。图 8 展示了如何使用 LOCATE 函数来实现此目的。
图 8. 通过 CODEUNITS 使用 POSITION
SUBSTRING
SUBSTRING 函数返回字符串的子字符串。子字符串是输入字符串的零个或多个相邻字符串长度单元。除了输入字符串之外,SUBSTRING 函数还有其他三个参数,它们分别是:起始位置、长度和代码单元指定。起始位置指定了输入字符串中结果的第一个字符串长度单元所在的位置。长度参数指定了所需子字符串的长度。使用基于字符的函数时不会发生用于构建字符的 CODEUNITS 分解。图 9 展示了如何防止多字节字符的分解。
图 9. 通过 CODEUNITS 使用 SUBSTRING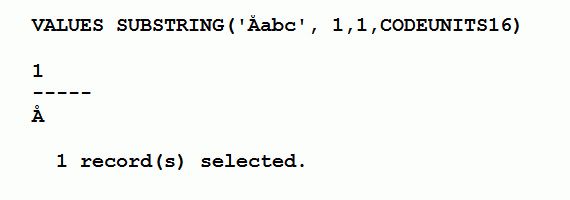
图片看不清楚?请点击这里查看原图(大图)。
处理不正确的数据或不完整的数据
涉及多字节字符的字符串操作可能遇到字符不正确(编码中没有定义字节合并)或字符不完整(拥有多字节字符的部分字节)的情形。考虑在使用新的基于字符的字符串函数执行字符串操作时可能导致这一状况的常见情形。字符 “音符 G 音谱号”(UTF-8 十六进制格式为 X‘F09D849E’)就是这样的例子,使用 CODEUNITS16 时其长度为 2。
输入字符串的问题
不完整的字符串数据
可以将拥有部分字符的字符串数据称为不完整的字符串数据。假设您拥有一个 UTF-8 编码的字符,其长度为 3 字节,而字符串只拥有编码的前两个字节。如果您使用 CODEUNITS16 来计算前两个字节的长度,则函数将给出一个警告。
清单 4. 使用不完整的输入字符串数据
VALUES CHARACTER_LENGTH(X'849E',CODEUNITS16)
1
-----------
2
SQL1289W During conversion of an argument to "SYSIBM.CHARACTER_LENGTH"
from code page "1208" to code page "1200", one or more invalid characters were
replaced with a substitute character, or a trailing partial multi-byte character was
omitted from the result. SQLSTATE=01517
1 record(s) selected with 1 warning messages printed.
不正确的字符串数据
每种字符编码都具有针对特殊字符的字节集或字节组合集。字符串函数的输入字符串数据可能拥有源字符串中的一些错误字符或无效字符。如果 DB2 在执行 CODEUNITS16 或 CODEUNITS32 计算时遇到无效字符,则它在字节序列形成部分函数结果时用替代字符替换任何此类的字节序列。十六进制格式的 X‘80’ 用 UTF-8 编码是无效的,遇到它时会抛出警告。
清单 5. 使用不完整的字符数据
VALUES CHARACTER_LENGTH(X'80',CODEUNITS16)
1
-----------
1
SQL1289W During conversion of an argument to "SYSIBM.CHARACTER_LENGTH"
from code page "1208" to code page "1200", one or more invalid characters were
replaced with a substitute character, or a trailing partial multi-byte character
was omitted from the result. SQLSTATE=01517
1 record(s) selected with 1 warning messages printed.
OCTETS 和 图形字符串输入
在 SUBSTRING FUNCTION 中,指定了 OCTETS 并且函数的输入是图形数据,而 <start> 参数不是奇数或 <length> 参数不是偶数,则会导致类似将图形字符分解为两个字节那样的错误。
清单 6. 字符分解 VALUES SUBSTRING(GRAPHIC('K'),2,1,OCTETS)
1
--
SQL20289N Invalid string length unit "OCTETS" in effect for function
"SYSIBM.SUBSTRING". SQLSTATE=428GC
输出字符串的问题
独立代理或不完整的字符串数据
当使用两个 16 位代码单元序列表示字符时,将该字符称为代理对。代理对可以区分为高代理和低代理。在字符串函数中使用 CODEUNITS16 时,DB2 进行单一代码单元或独立代码单元的区分。即,如果您拥有一个代理对,则使用 CODEUNITS16 的字符长度为 2,而使用 CODEUNITS32 的字符长度为 1。因此如 SUBSTRING 之类的函数可以根据您提供的参数分解代理对。
替换字符插入导致缓冲区溢出
插入替换字符时,字符串的字节长度可能增加。如果长度增加超出了输出所能使用的缓冲区空间,则字符串的尾部将被截断,而且将收到一个警告:将字符串指派给另一个长度较短的字符串数据类型时字符串的值将被截断。
向后兼容
注意:新的字符串函数位于 SYSIBM 函数路径下,而旧一些的函数位于 SYSFUN 路径下。希望您使用新的 SYSIBM 函数路径,既便您没有使用字符串单元参数也是如此。默认情况下,在默认的 CURRENT PATH 中 SYSIBM 函数路径位于 SYSFUN 之前。所有的旧函数仍然受到支持。
性能考虑
基于字符的函数可能需要将输入数据字符串转换为一个中间的 UNICODE 代码页,比如 UTF-16 或 UTF-32,然后才能对它进行处理。如果结果数据是一个字符串,那么中间结果也要转换回输入代码页。OCTETS 作为一种字符串单元指定不需要任何转换,而且使用起来更加有效。CODEUNITS16 和 CODEUNIST32 作为字符串单元可能导致代码页转换。虽然 DB2 执行自我优化,但是是否需要代码页转换还不清楚。转换成本对 LOB 输入更加重要,因为输入字符串的大小可能很大。
结束语
本文向您简要地介绍了 DB2 数据服务器中新增的基于字符的字符串函数。首先介绍了一些关键概念,如针对字符串数据的字符语义和字节语义。接着讨论了需要使用这些函数的原因,并举例说明了一些常见的场景。还了解了代码单元和基于字符的函数的概念。然后解释了这些函数如何帮助您解决之前讨论的问题,并对每个场景进行举例说明。最后,讨论了使用这些函数时的常见问题和性能考虑。理想情况下,应该使用这些函数更好地执行字符串操作,将更多的应用程序逻辑植入 SQL 层而不是在应用程序中实现这些逻辑。