Oracle数据库学习笔记(一)
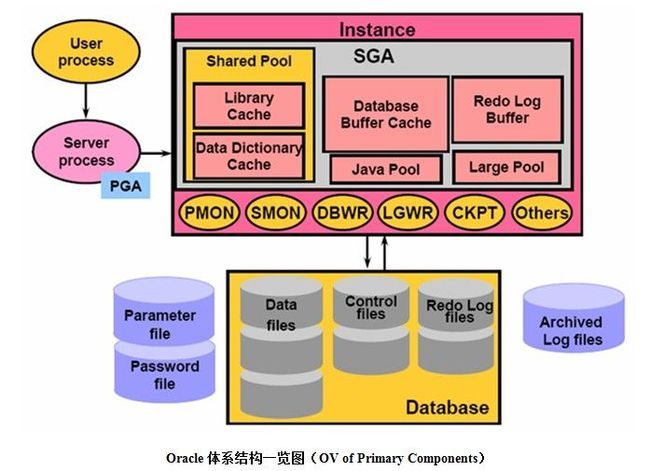
Oracle的体系结构大体上分为两部分:Instance(实例)和Database(数据库)。
- Instance(实例) :在Oracle Instance中主要包含了SGA以及一些进程(例如:PMON、SMON、DBWn、LGWR、CKPT等)。如果一个用户的进程连接到Oracle Server时,其实就是连接到Oracle Instance。在SGA中又包含了5大部件:Share Pool、Database Buffer Cache、Redo Log Buffer、Java Pool、Large Pool。
- Database(数据库) :Database其实就是一堆文件组成的,主要是用于存储着数据,Database中主要包含三种类型的文件:Data Files、Control Files、Redo Log Files。
下面介绍几个Oracle重要概念:
Oracle Server(Oracle服务器)
Oracle Server又包含两部分:Oracle Instance和Oracle Database(Oracle Server是一个比较大的概念,我们通常说的Oracle服务器就是指的Oracle Server)。
Oracle Instance(Oracle实例)
Oracle Server用于管理数据,数据存储在Oracle Database中,其表现形式为存储在磁盘上的一堆文件,如果要去访问这堆文件,需要有一个媒介------Oracle Instance,Oracle Instance是访问Oracle Database的一种手段。
一个Oracle Instance对应一个且只能对应一个Oracle Database,而一个Oracle Database可以有多个Instance来访问他,也就是说Oracle Instance和Oracle Database是多对一的方式。一般情况下我们以一台机器上安装Oracle时都是以Instance和Database一对一的方式,但是在Oracle集群(Oracle RAC环境)的情况下他是多个Instance对应一个Database。
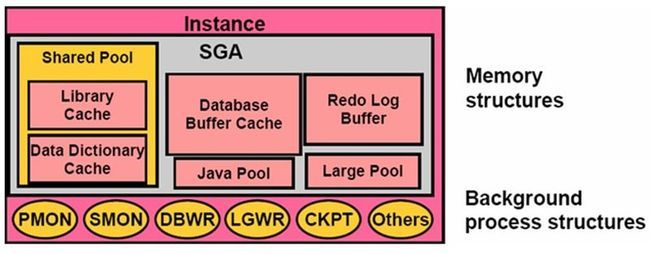
Oracle Instance有两部分组成:
- Memory Structures(内存结构) :Memory Structures就是Oracle Instance中的SGA。
- Background Process Structures(后台进程结构) :Background Process Structures就是指PMON、SMON、DBWR、LGWR、CKPT等后台进程。
Oracle Instance启动时就会启动一些Background Process并且分配内存,Oracle Instance是易于消失的。(相对于数据库文件来说,例如:一断电就没有了)。
Oracle数据库Connection & Session
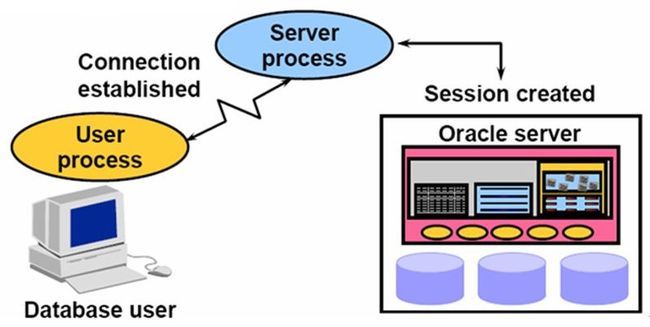
Oracle Connection
Oracle中的Connection是指一个Oracle的客户端和后台的服务器建立的一个TCP连接,一定是Oracle客户端和后台的进程(Server Process)建立的TCP连接。
在Oracle Process中有三种类型:
- Background process(后台进程)他是Oracle Instance的基本组成部分
- Server process(服务器进程)其实Background Process和Server Process都是Oracle的后台进程。其中Background Process是专注于数据库核心服务的进程;而Server process是处理客户端和服务器之间连接的进程。
- User process(客户端进程) 客户端要与服务器连接,那么在客户端启动起来的进程就是User Process(例如:SQL*Plus、Toad等)。用户登录到Oracle Server就是User Process和Server Process建立Connection。
Oracle Session
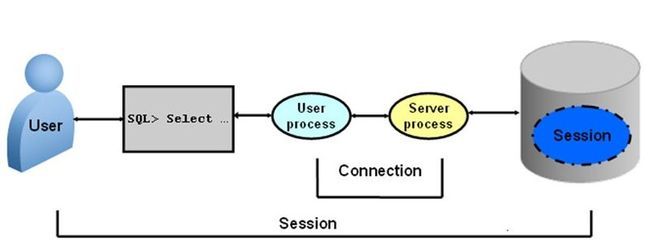
Connection建立的过程其实就是首先建立TCP连接,Oracle对用户的身份进行认证、进行安全审计等等,当这些都通过后Oracle的Server Process才会允许客户端使用Oracle提供的服务,当Oracle的连接建立起来以后,就意味着开始了一个会话,当连接断开的时候这个回话就消失了。Session是和Connection相辅相成的。Session信息会存储在Oracle的Data Dictionary中。
下图为在Linux中启动Oracle Instance
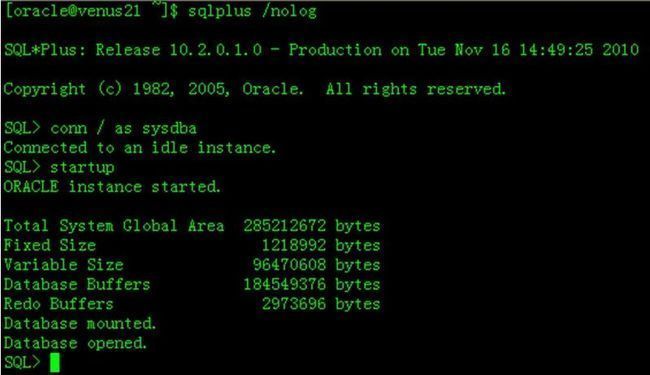
输入一个【!】便可以切换到shell中。后续如果想返回sqlplus中输入【exit】即可。
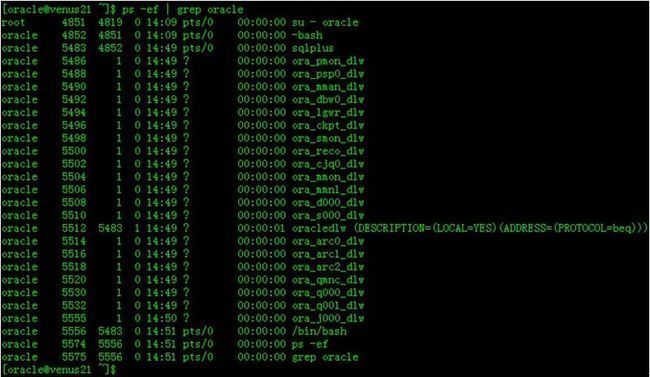
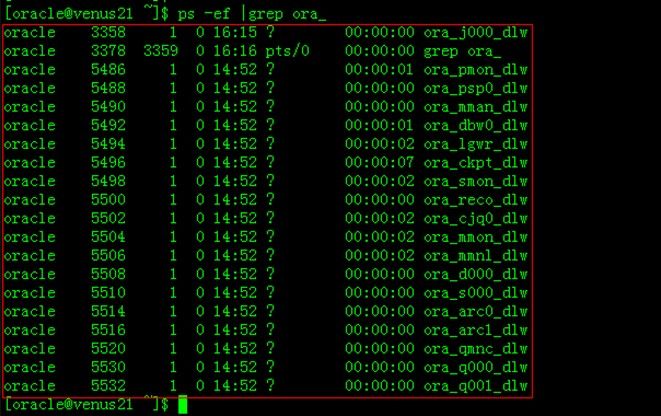
通过Linux命令ps –ef可以查看Oracle进程(Oracle Instance)
Oracle Database(Oracle数据库)
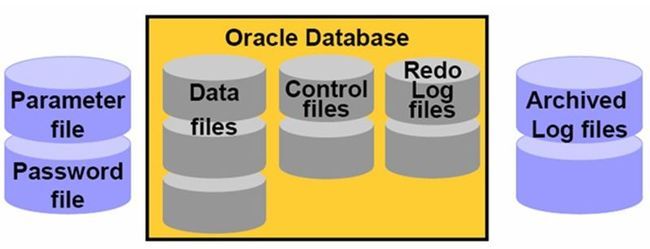
Oracle Database其实就是一堆文件,这堆文件是一堆数据,他们是作为一个整体。Oracle Database包含三种基本的核心文件类型Data File、Control File、Redo Log File。
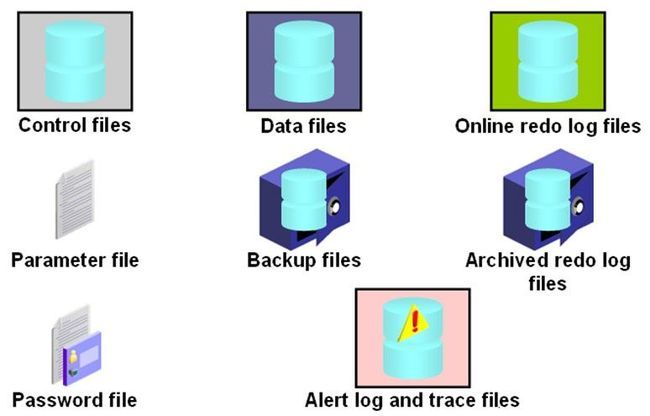
- Data Files(数据文件) :Data Files就是用于存储数据的,Table中的数据都是保存在Data File中的。
- Control Files(控制文件) :Oracle为了操作Data File,提供了一些Control files,这些Control File主要是记录数据库的一些控制信息。
- Redo Log Files(重做日志文件) :Redo Log Files记录着数据库的改变,如果向数据库中放入数据或者是修改里面的数据,只要对数据库作了修改,那么就要将修改之前的状态、修改之后的状态都会记录在Redo Log Files中,其作用就是恢复Data File。例如:数据库有一个事务需要提交,但是提交失败了,事务就要回滚,那么事务回滚的依据就来自于这个Redo Log Files。Redo Log Files中记录着数据库的改变,关于这个事务的改变,如果需要回滚就需要把Redo Log Files中的数据取出来,依照Redo Log Files中的数据把Data Files恢复到修改之前的状态。
- Parameter File(参数文件) :任何一个数据库都必须要有参数文件,这个参数文件就规定了Oracle中的一些基本的参数、初始化的参数的值。
- Archived Log Files(归档日志文件) :Archived Log Files和Redo Log Files是相辅相成的,Redo Log Files其实是一个反复利用的过程,他会有几个(一般为3个)固定的文件,这些固定文件他会被依次使用,用满了以后,Oracle就会在此写这个文件头,就把以前的东西冲掉了。为了进一步加强数据库的备份恢复能力,在覆盖之前把这些修改的信息都把他归档到Archived Log Files中。
- Password File :用与户客户端连接到后台数据库系统时候存储口令的。
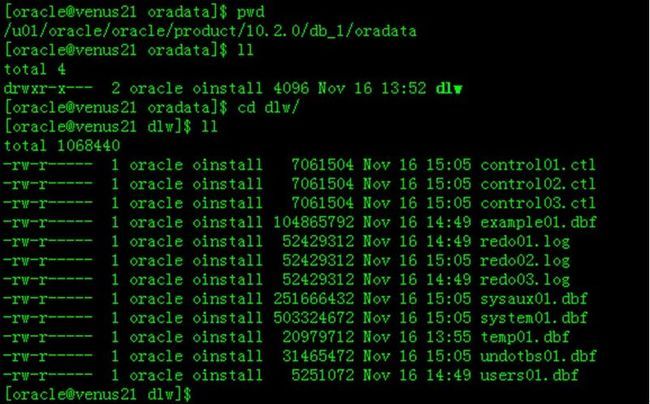
下面显示在Linux安装的Oracle的Database部分。下面显示的这一大堆文件就是Oracle Database(一般存放在数据库安装路径下的实例名对应的目录下)。
- *.tcl控制文件
- *.dbf数据文件
- *.log重做日志文件
Memory Structures
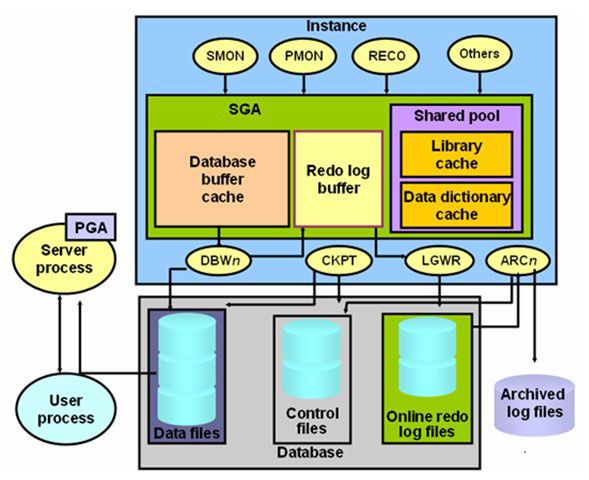
Oracle的Memory Structures实际上包含两部分内容:SGA和PGA:
- SGA(System Global Area系统全局区) 一个Oracle Instance对应一个SGA,SGA在Oracle Instance启动的时候被分配,SGA是Oracle Instance的基本组成部分。一个Oracle Instance就仅有一块SGA,SGA是一个非常大的内存空间,甚至可以占据物理内存的80%。
- PGA(Program Global Area程序全局区) 一个Server Process启动的时候就会分配一个PGA。
整个Oracle Instance只有一个SGA,一个Server Process就会有一个PGA。在Oracle Instance中PGA可能会很多。例如启动10个Server Process就会有10个PGA。无论启动多少个进程,只要有一个Oracle Instance那么他就仅有一个SGA。
Oracle的使用场景一般为管理海量数据,那么大量的数据都是存储在磁盘上的,为了提高存储、访问的效率,那么Oracle必然会在内存中开辟一块很大的内存区域(内存的访问速度要快几千倍几万倍)。Oracle是一个比较耗费内存的软件,一般他会把可用的内存全部用完,他的内存一般是消耗在SGA上。
当Linux/Unix下的Oracle进程启动,我们可以在Linux/Unix的shell中输入【ipcs】命令查看系统共享内存分配的情况(IPC是进程间通讯的一种机制,ipcs命令是用于查看ipc资源的、ipc状态的)。在Linux/Unix中Oracle的SGA的实现方式就是利用Shared Memory Segments(共享内存),对于Windows的实现方式可能不同。SGA的大小是可以配置的,随着数据库的负载加大,Oracle Instance对内存的需求加大,那么SGA也会扩张甚至会把整个内存都消耗掉。
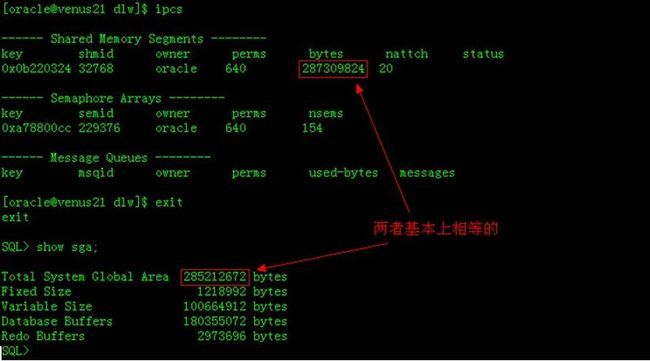
SGA(System Global Area)
SGA(System Global Area系统全局区),其中包含以下几大块的基本内存:
- Shared Pool
- Database Buffer Cache
- Redo Log Buffer
- Large Pool
- Java Pool
其中Shared Pool、Database Buffer Cache、Redo Log Buffer是核心的内存区域,其中Large Pool和Java Pool是可选项的(在Oracle 11g中又包含了String Pool)。
对于一个启动好的Oracle数据库,怎样去查看他的SGA?以Linux为例,首先可以通过命令【ps –ef | grep oracle】查看Oracle 的Background Process。
输入命令【show sga;】便可以查看SGA的信息了。
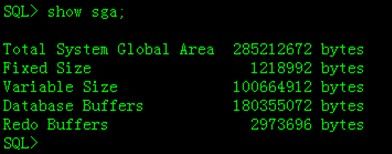
在早期的Oracle版本中,在Oracle启动之后SGA就是固定不变的,在Oracle 9i以后的版本就可以在运行时发生改变,即在线动态调整SGA的值。Oracle Instance启动起来就会分配一个SGA,用户便可以向数据库服务发送请求,随着用户发出的请求负荷增大,Oracle需要的内存资源就越大,因此SGA就需要扩张,所以便有了可以动态变化SGA的需求。
在SGA中有一个重要的参数 SGA_MAX_SIZE ,该参数决定了Oracle Instance SGA的最大值,在这个上限的范围内,SGA可以分配他的每个部件占用多少内存。SGA可以动态增长或缩小,SGA每次增大或缩小的单位granules(granules是SGA分配内存的基本单位,通常对于SGA小于128M的情况granules=4M,SGA超过128M的情况granules=16M )。SGA是一个连续分配的内存区域,而且他的分配最小单位是granules但是他的最大尺寸不能超过SGA_MAX_SIZE。
执行下图中的SQL语句便可以查看当前Oracle系统的granules。下图显示了SGA的组成部分以及每个组成部分的granules。
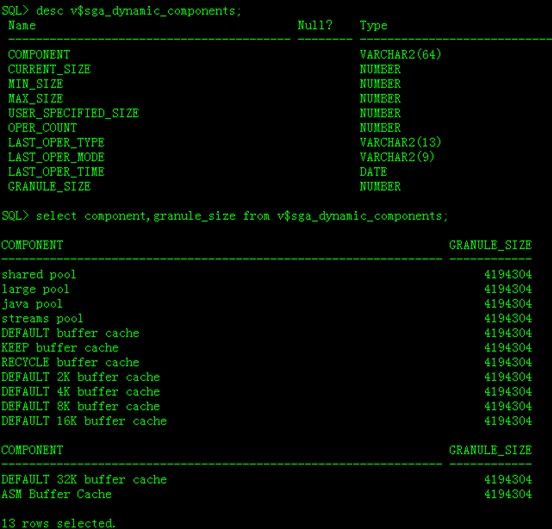
SGA最大值是由SGA_MAX_SIZE决定的,它里面又包含了不同的组件(Shared Pool、Database Buffer Cache、Redo Log Buffer、Large Pool、Java Pool),这些内部组件也有其内存大小设置的参数:
- DB_CACHE_SIZE 用于设置Database Buffer Cache的内存大小
- LOG_BUFFER 用于设置Redo Log Buffer的内存大小
- SHARED_POOL_SIZE 用于设置Shared Pool的内存大小
- LARGE_POOL_SIZE 用于设置Large Pool的内存大小
- JAVA_POOL_SIZE 用于设置 Java Pool的内存大小
Oracle10g引入了一个功能,就是自动内存分配功能,例如:已经制定了SGA_MAX_SIZE,在这个上限范围内,具体每个部件最优的尺寸设置有Oracle自动来进行分配。这样便可以减少对如果设置SGA内部各组件的内存大小设置的问题。随着Oracle负荷的变化,Oracle会自动去调整内存分配的最佳布局。
Shared Pool
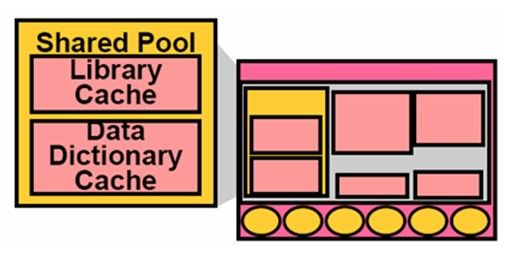
Shared Pool(共享池)的主要作用是存储SQL解析后的内容。例如:发出一个SQL语句或命令让数据库执行,SQL就需要在数据库内部就需要被解析,建立执行计划,然后按照执行计划去执行,每个SQL语句都要被解析成原始操作去执行,解析好的SQL语句都会存储在共享池中。
在Oracle Instance中Shared Pool非常总要,它关系到数据库的性能,共享池包含两块共享内存,这两块共享内存关系到数据库的性能。
- Library Cache :Library Cache中存储的是经过编译解析后的SQL和PL/SQL语句的内容。如果下次在执行同样的SQL语句的时候,就不需要解析了,立即从Library Cache获取执行。Library Cache的SIZE会决定着编译解析SQL语句的频度,从而决定了性能。Library Cache中有包含两部分内容:Shared SQL Area和Shared PL/SQL Area。Library Cache是Shared Pool的一个子部件,Library Cache的SIZE是由Shared Pool来决定的。
- Data Dictionary Cache :Data Dictionary就是存储着数据库控制信息。为了提高访问Data Dictionary的速度,此时需要一个Cache,需要的时候访问内存即可。Data Dictionary Cache里面的信息包含了database files、tables、indexes、columns、users、privileges和其他的数据库对象。数据字典是使用最频繁的,几乎所有的操作都需要到数据字典去查询(例如:需要针对一个表进行操作,就需要到数据字典去查询用户对这个表是否具有访问权限等等),他的SIZE是由Shared Pool来决定的。
可以在线去更改Shared Pool的SIZE,只需要执行下面的SQL语句即可:
ALERT SYSTEM SET SHARED_POOL_SIZE=64M
Database Buffer Cache
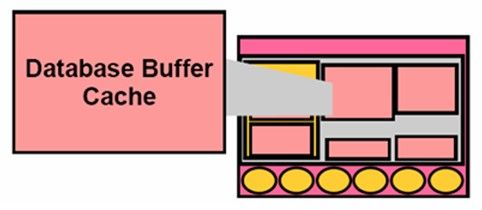
Database Buffer Cache的任务主要是用于存储数据文件中的数据,在Oracle中数据是存储在磁盘上的,又不可能将所有的数据文件内容都放到内存中,但访问磁盘中的数据速度又会很慢,那么就需要将其中一部分的数据放入到内存中,当用户去访问时发现需要访问的信息在内存中,那么就不需要访问磁盘了,这样提升了访问的速度。
Database Buffer Cache就是包含了来自于Data File中的数据以及即将要写到Data File中的数据(也成为Dirty Buffer)都会保存到这个Database Buffer Cache中,而且Database Buffer Cache得SIZE是最大的。例如一个用户去访问一个表里面的记录时,数据库接收到这个请求后,他首先会在这个Cache中查找是否存在该数据库表的记录,如果有这个记录直接从内存中读取该记录返回给用户,否则只能去磁盘上去读取。很显然如果希望性能提高就需要提升Cache的命中率。
Database Buffer Cache中存储的是Data Blocks(数据块)。Oracle中的数据是按照Block来进行存储的,Block是Oracle存储的最基本的单位。在Database Buffer Cache中针对Block的SIZE的设置,对应的参数是:DB_BLOCK_SIZE。
在Database Buffer Cache中包含三部分内容:
- DB_CACHE_SIZE
- DB_KEEP_CACHE_SIZE
- DB_RECYCLE_CACHE_SIZE
Database Buffer Cache可以在线去更改SIZE,只需要执行下面的SQL语句即可:
ALERT SYSTEM SET DB_CACHE_SIZE=64M
在性能调优的过程中,需要去监控DB_CACHE_SIZE的行为和他的统计信息,可以使用DB_CACHE_ADVICE参数来设定是否要收集信息,如果收集信息那么收集后的信息就会放在V$DB_CACHE_ADVICE表中。
Redo Log Buffer
数据库是处于经常在改变的,比如有时候事务失败的需要回滚,就需要Redo Log Files来记录数据库的改变,如果想恢复数据库文件就用Redo Log Files里面的内容进行恢复。Redo Log File在内存中有一个对应的Cache它称为Redo Log Buffer。每次对数据进行改变,在Redo Log里面就会有相应的一条记录,这条记录称为Redo Entries,一条Redo Entries就可以恢复一次对数据库的改变。Redo Log Buffer的SIZE由参数LOG_BUFFER来决定。
Large Pool
Large Pool主要是用于处理一些额外的工作,比如说使用RMAN进行备份需要使用Large Pool或者进行并行处理的时候会需要用到Large Pool。做一些IO操作的时候也会用到Large Pool。Large Pool的SIZE由参数LARGE_POOL_SIZE来决定。
Java Pool
Oracle支持Java编程,例如支持Java编写存储过程的,Java Pool的SIZE由参数JAVA_POOL_SIZE来决定。
PGA(Program Global Area)
PGA(Program Global Area程序全局区)与SGA不同,每一个Background Process对应一个PGA(例如:PMON就会有一个PGA与之对应)。PGA和SGA是平等的关系,并不存在包含关系。
Process Structures
Oracle分为三种类型的进程:User Process、Server Process、Background Process。其中Server Process和Background Process都属于后台进程。为了连接Oracle的后台服务器,那么User Process是在客户端所必须的进程。Oracle本身的进程细分成两类,就是前面提到的Server Process和Background Process。Oracle是可以运行在多种平台下,而Linux和Windows的进程有所不同,在Linux中进程为基本单位,所以Oracle在Linux(或Unix)中体现的是多个进程。而在Windows中一般是在进程中运行多个线程,所以Oracle在Windows中的体现是一个大的进程中运行了多个线程。
User Process
Oracle User Process就是Oracle客户端的进程,任何程序如果想去连接到Oracle的后台,那么这个程序就是Oracle的客户端(一般是编译利用Oracle提供的类库实现)。例如下面使用SQL*Plus进行登录,通过Windows Task Manager可以看到这便是Oracle User Process。
Server Process
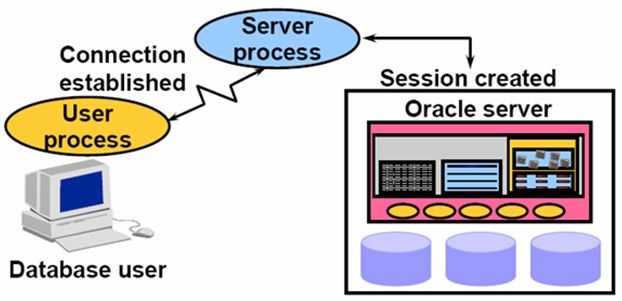
Oracle的后台进程分为两类,一类是Background Process,另一类就是Server Process。Server Process主要是负责和User Process连接。Oracle的连接方式有两种:Dedicated Server模式和Shared Server模式。Server process是处理客户端和服务器之间连接的进程。
以Linux为例,首先通过命令ps –ef | grep oracle查看Oracle进程。
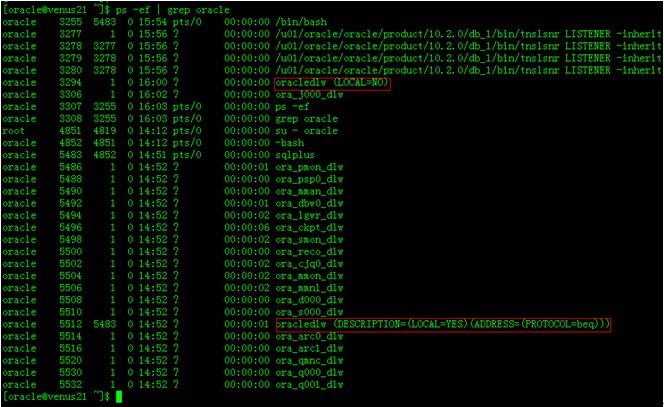
当有User Process与Server Process进行连接的时候,以Linux为例,通过ps –ef | grep oracle这时会发现后台进程中多出了一个进程(即本例中的:oracledlw),之所以客户端可以连接到Oracle Server,就是这个进程与客户端进程进行的通信,这个进程就是Server Process的一种。
在Oracle的服务器也可以通过SQL*plus命令进行客户端连接到Server Process。
那么在客户端机器使用客户端工具访问Oracle Server和在Oracle服务器上直接使用SQL*plus访问Oracle Server有什么区别呢?下图的两个大的矩形框表示两台物理机,黄色的框表示网卡,主机中的圆圈表示进程,两台机器的进行通信,需要通过网卡进行连接,一般是通过TCP/IP建立的连接,对于同一台计算机的进程之间的通信方式有两种:第一种方式为利用IPC进行通信;另一种方式为模拟TCP/IP方式,在Linux中有一个特殊的网卡【lo】这个网卡称为Local Loopback(本地环路网卡),他的IP地址永远是127.0.0.1,即使计算机不存在物理网卡这个网卡也是存在的。这种方式其实就是本地对本地的通信。
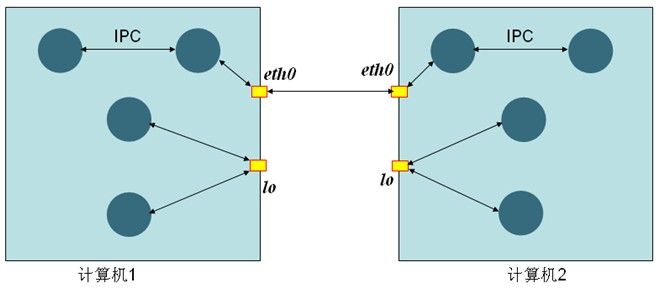
IPC:Inter Process Communication,包括共享内存、队列、信号量等几种形式。

Background Process
Background Process是Oracle Instance的核心,Oracle中有很多Background Process,下面可以通过命令 ps –ef | grep oracle 查看Oracle的进程,Oracle Background Process都是以【ora_ 】为前缀,以【_数据库实例名 】为后缀。
Oracle Background Process又分为两种:
- Mandatory Background Processes(必须的后台进程):当Oracle Instance启动完成以后这些进程必须要存在(例如:DBWn其中n表示从0开始,可能存在多个进程)。

- Optional Background Process(可选的后台进程):根据具体的配置,这些进程可能启动或不启动。

DBWn(Database Writer)
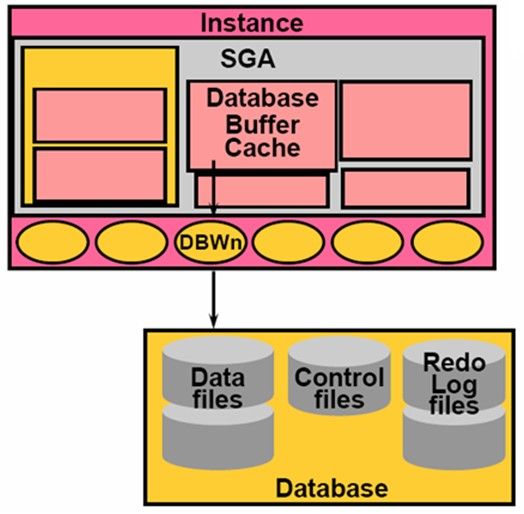
DBWn是Oracle中工作最繁重的进程。他的任务是把SGA中的Database Buffer Cache中保存着已修改过的内容(Dirty Buffer)写到Data File中,已经发生过修改的这些Buffer,在Oracle中称为Dirty Buffer(脏数据)。Data Buffer Cache中的Dirty Buffer通过DBWn Process写入Data File,如果数据库的负荷比较大,来自于客户端的请求比较多,存在大量的IO操作,需要频繁的将缓冲区的内容写到磁盘文件上,那么这时就可以配置多个DBWn(一共Oracle支持20个DBWn,DBW0-DBW9,DBWa-DBWg)。通常一个中小型的Oracle只需要一个DBW0 Process就可以了。
触发DBWn Process将缓冲区的内容写到磁盘文件的条件:
- Checkpoint Occurs
- Dirty Buffer reach threshold
- There are no free Buffers
- Timeout occurs
- RAC ping request is made
- Tablespace OFFLINE
- Tablespace READ ONLY
- Table DROP or TRUNCATE
- Tablespace BEGIN
- BACKUP
LGWR(LOG Writer)
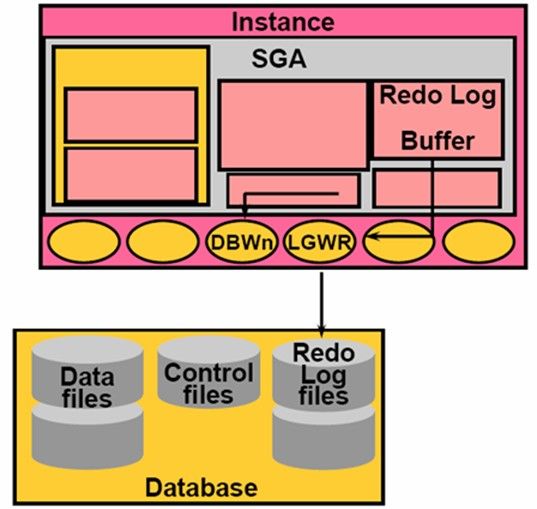
在Oracle Instance中只有一个LGWR Process,这个Process的工作和DBWn Process类似,LGWR Process是将Redo Log Buffer中的内容写入到Redo Log Files中。Redo Log Buffer是一个循环的Buffer,对应的Redo Log Files也是一个循环的文件组,从文件头开始写,当文件写满了,又会从文件头开始写(会把前面的内容覆盖掉),为了避免将Redo Log File覆盖掉可以选择将其写入到Archived Redo Log Files中。
触发LGWR Process的条件:
- At Commit
- When one-third full
- When there is 1 MB of redo
- Every three seconds
- Before DBWn writes
SMON(System Monitor)
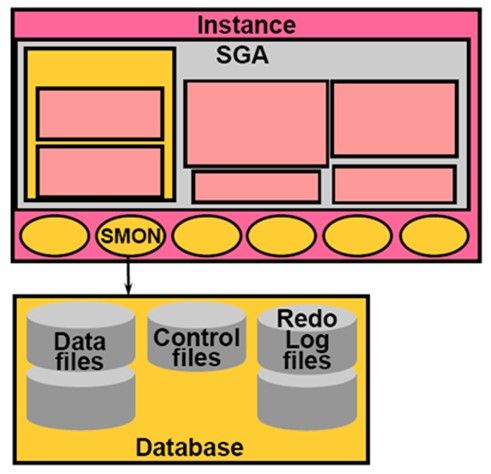
SMON(System Monitor)系统管理器,当Oracle运行时突然宕机,那么在下一次启动Oracle Instance的时候,它里面一些没有释放的资源,这些资源都会由SMON进行清理;在一些事务失败的时候也由SMON进行清理,或者由于内存空间很分散(不连续)这时需要SMON将这个分散的空间整合起来;对于一些临时的Segment由SMON进行释放。
PMON(Process Monitor)
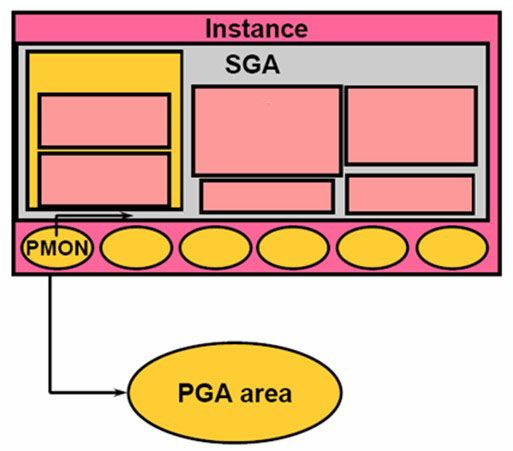
PMON ( Process Monitor )进程监控器,用于监控各个 Oracle 后台进程的,检查各个进程是否正常,发现异常的进程将其清除掉,重新生成该进程。
CKPT(Checkpoint)
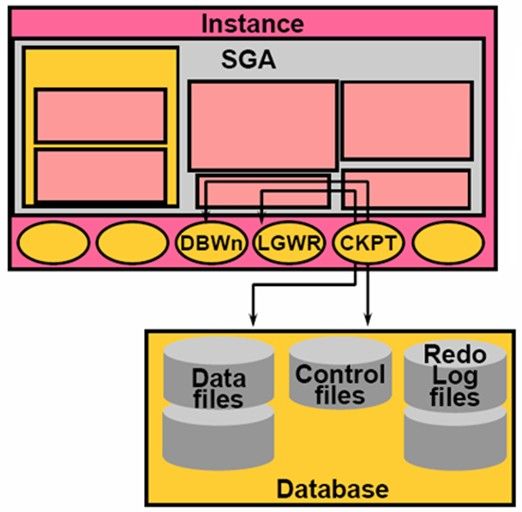
CKPT(Checkpoint)主要用于写Checkpoint(检查点)、在Data File的在文件头更新检查点信息、在Control File中更新检查点的信息。
ARCn(Archiver)
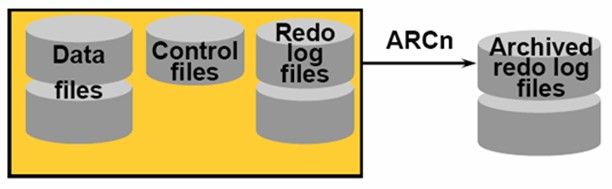
ARCn(Archiver)是Oracle中的可选项的进程(几乎可看作必选项进程),Oracle可以运行在两种模式下,一种是ARCHIVELOG MODE(归档模式);另一种是NOARCHIVELOG MODE(非归档模式)。Redo Log Files是一个循环文件组,从头开始写,写完了以后,又回到最开始的地方写(即:覆盖原来的开头部分),在覆盖之前就可以通过ACRn进程将老的信息写到Archiver Redo Log files(归档日志文件)中,基本上所有的生产数据库都会运行在Archiver模式,否则数据库发生灾难性事故后就很难进行恢复了。
Logical Structure
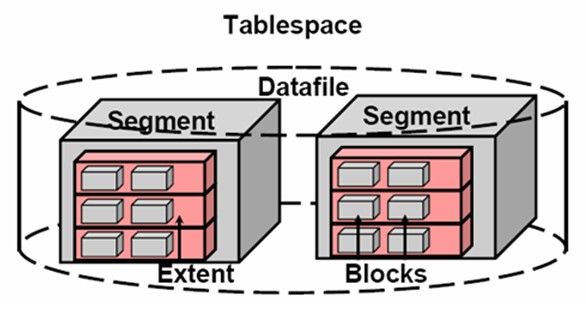
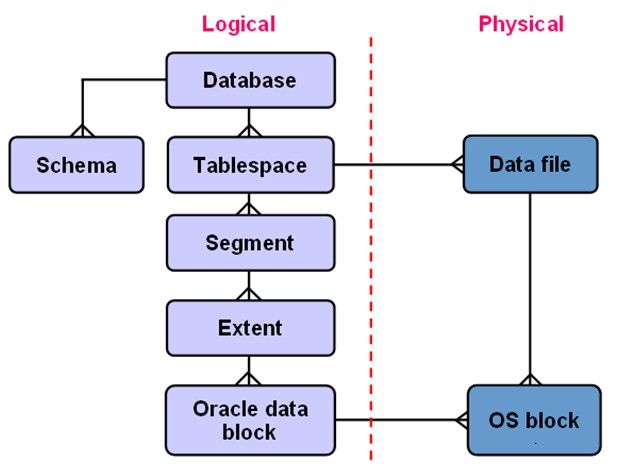
Oracle有一套Logical Structures(逻辑结构),一个Oracle Server只有一个Oracle Database,一个Oracle Database可以由多个Tablespace组成,一个Tablespace可以有多个Segment组成,一个Segmnet可以由多个Extent组成。一个Extent是一组连续的Blocks组成,Block是Oracle中的最小基本单位,Oracle中的Block对应着操作系统的Block,操作系统的文件系统也是由Block组成的,一个Block又对应着内存中的一个Page,Oracle的Block是操作系统文件系统的Block的整数倍,例如: Oracle的一个Block对应着操作系统的1个Block或者Oracle的一个Block对应着操作系统的2个Block。Oracle中有一个重要的参数DB_BLOCK_SIZE,该参数用于设置Oracle Block的SIZE(通常Oracle的Block=8K)。一堆连续的Block组成了Extent。很多Extent(不一定是连续的)组成了Segment。一个或多个Segment就组成了一个Tablespace。一个Tablespace或多个Tablespace组成了Oracle Database。Oracle有很多Data File,这些Data File其实就是他的物理结构。一个Tablespace可以由多个Data File组成,一个Segment也可以由多个Data file组成,但Segment和Data File并没有隶属关系,一个Data File必然属于一个Tablespace,但是一个Data File不一定属于一个Segment,Extent不能跨Data File,一个Extent只能存在于一个Data File中。
Processing SQL Statements
Oracle处理SQL语句的过程分为以下阶段:客户端Connect到后台建立一个Connection,建立一个会话,建立完成后, 向后台发出SQL语句,发到后台第一个阶段Parseing(其实在做Parseing之前还要做安全检查,查看用户的权限),Parseing就是解析SQL语句,把SQL语句分解成它能够执行的原子操作;下一个阶段叫做Banding,就是把一些变量绑定在SQL语句上,接下来就开始执行,执行完成SQL语句后,把返回的结果返回给客户端。
SQL语句分为几种:一种就是查询语句,就是SELECT,第二种是DML(数据操作语言),也就是INSERT、DELETE、UPDATE。比如说去UPDATE一条记录的时候,这条语句通过Parseing、通过安全检查后以及解析成原子操作后开始执行的时候,如果该操做的记录没有在SGA的Database Buffer Cache中,就会从磁盘上的数据文件中读取上来,然后再进行更新操作。